
13.9: Discrete Distributions - Hypergeometric, Binomial, and Poisson
- Page ID
- 22530

What are Discrete Distributions?
In order to explain the meaning and utility of dicrete distributions, it is necessary to first introduce the topic of Random Variables. The term random in Random Variable refers to the idea that each individual outcome has an equal chance of occuring. Therefore, each outcome is randomly determined. For example, a fair coin has an equal probability of flipping up heads as it does flipping up tails. Hence, the random variable is determined by the outcome of flipping a coin. However, it is frequently the case in chemical engineering that when a process is performed we are only interested in some function of the outcome rather than the outcome itself. For example, in a chemical reactor we might want to know the probability that two molecules collide and react to form a product at a certain temperature, however it is more useful to know the sum of the these collisions that form product rather than the individual occurences. This is analgous to rolling two dice and wanting to know the sum of the dice rather than the individual numbers rolled. These discrete values defined on some sample space compose what are called Random Variables.
Random Variable Example
Suppose that our experiment consists of tossing 4 fair coins. If we define a variable X and let it denote the number of heads flipped, then X is a random variable with possible discrete values of 0,1,2,3,4 with respective probabilities:
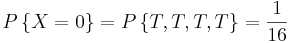
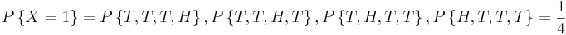
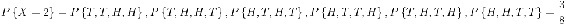
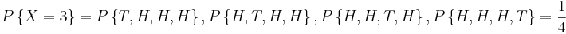
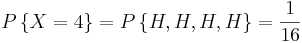
We can do the same for the probability of rolling sums of two dice. If we let Y denote the sum, then it is a random variable that takes on the values of 2, 3, 4, 5, 6, 7, 8, 9, 10, & 12. Rather than writing out the probability statements we can represent Y graphically:
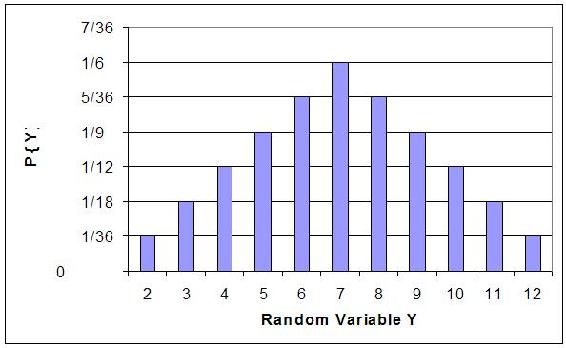
The graph plots the probability of the Y for each possible random value in the sample space (y-axis) versus the random value in the sample space (x-axis). From the graph one can infer that the sum with the greatest probability is Y = 7.
These are just two ways one can describe a random variable. What this leads into is representing these random variables as functions of probabilities. These are called the discrete distributions or probability mass functions. Furthermore, independent random events with known probabilities can be lumped into a discrete Random Variable. The Random Variable is defined by certain criteria, such as flipping up heads a certain number of times using a fair coin. The probability of a certain random variable equaling a discrete value can then be described by a discrete distribution. Therefore, a discrete distribution is useful in determining the probability of an outcome value without having to perform the actual trials. For example, if we wanted to know the probability of rolling a six 100 times out of 1000 rolls a distribution can be used rather than actually rolling the dice 1000 times.
Note: Here is a good way to think of the difference between discrete and continuous values or distributions. If there are two continuous values in a set, then there exists an infinite number of other continuous values between them. However, discrete values can only take on specific values rather than infinite divisions between them. For example, a valve that can only be completely open or completely closed is analogous to a discrete distribution, while a valve that can change the degree of openness is analogous to a continuous distribution.
The three discrete distributions we discuss in this article are the binomial distribution, hypergeometric distribution, and poisson distribution.
Binomial Distribution
This type of discrete distribution is used only when both of the following conditions are met:
- The test has only two possible outcomes
- The sample must be random
If both of the above conditions are met, then one is able to use this distribution function to predict the probability of a desired result. Common applications of this distribution range from scientific and engineering applications to military and medical ones. For example, a binomial distribution may be used in determining whether a new drug being tested has or has not contributed ("yes" or "no" labels) to alleviating symptoms of a disease.
Since only two outcomes are possible, they can be denoted as MS and MF for the number of successes and number of failures respectively. The term p is the frequency with which the desired number, MS or MF will occur. The probability of a collection of the two outcomes is determined by the following equation.
\[P\left(M_{S}, M_{F}\right)=k p^{M_{S}}(1-p)^{M_{F}} \label{1} \]
k in the above equation is simply a proportionality constant. For the binomial distribution it can be defined as the number of different combinations possible
\[k=C\left(\frac{M_{S}+M_{F}}{M_{S}}\right)=\frac{\left(M_{S}+M_{F}\right) !}{M_{S} ! M_{F} !} \label{2} \]
! is the factorial operator. For example, 4! = 4 * 3 * 2 * 1 and x! = x * (x − 1) * (x − 2) * … * 2 * 1. In the above equation, the term (MS + MF)! represents the number of ways one could arrange the total number of MS and MF terms and the denominator, NS!MF!, represents the number of ways one could arrange results containing MS successes and MF failures. Therefore, the total probability of a collection of the two outcomes can be described by combining the two above equations to produce the binomial distribution function.
\[P\left(M_{S}, M_{F}\right)=\frac{\left(M_{S}+M_{F}\right) !}{M_{S} ! M_{F} !} p^{M_{S}}(1-p)^{M_{F}} \label{3} \]
This can be simplified as the equation
\[\Gamma\{X-k\}-\frac{n !}{(n-k) ! k !} p^{k}(1-p)^{n} \label{4} \]
for \(k= k=-0,1,2,3 \dots\).
In the above equation, n represents the total number of possibilities, or MS + MF, and k represents the number of desired outcomes, or MS. These equations are valid for all non-negative integers of MS , MF , n , and k and also for p values between 0 and 1.
Below is a sample binomial distribution for 30 random samples with a frequency of occurrence being 0.5 for either result. This example is synonymous to flipping a coin 30 times with k being equal to the number of flips resulting in heads.
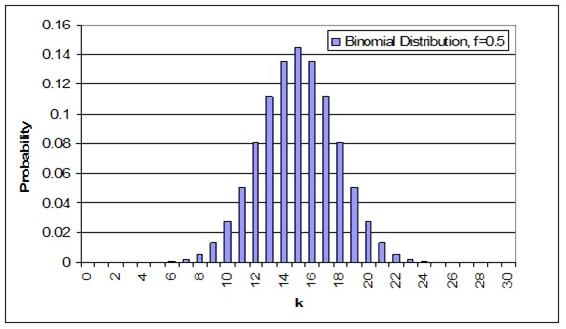
An important note about these distributions is that the area under the curve, or the probability of each integer added together, always sums up to 1.
One is able to determine the mean and standard deviation, which is described in the Basic Statistics article, as shown below.

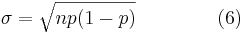
An example of a common question that may arise when dealing with binomial distributions is “What is the probability of a certain result occurring 33 – 66% of the time?” In the above case, it would be synonymous to the likelihood of heads turning up between 10 and 20 of the trials. This can be determined by summing the individual probabilities of each integer from 10 to 20.
X > 33%)=\sum_{possible values}P(N_S)=P(10)+P(11)+...+P(19)+P(20)" src="/@api/deki/files/19527/image-813.png">
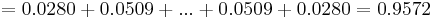
The probability of heads resulting in 33 – 66% of the trials when a coin is flipped 30 times is 95.72%.
The probability for binomial distribution can also be calculated using Mathematica. This will simplify the calculations, save time, and reduce the errors associated with calculating the probability using other methods such as a calculator. The syntax needed to calculate the probability in Mathematica is shown below in the screen shot. An example is also given for various probabilities based on 10 coin tosses.

where k is the number of events, n is the number of independent samples, and p is the known probability. The example above also generates a set of values for the probabilities of getting exactly 0 to 10 heads out of 10 total tosses. This will be useful because it simplifies calculating probabilities such as getting 0-6 heads, 0-7 heads, etc. out of 10 tosses because the probabilities just need to be summed according to the exact probabilities generated by the table.
In addition to calling the binomial function generated above, Mathematica also has a built in Binomial Distribution function that is displayed below:
PDF[BinomialDistribution[n,p],k] where n,p, and k still represent the same variables as before
This built in function can be applied to the same coin toss example.

As expected, the probabilities calculated using the built in binomial function matches the probabilities derived from before. Both methods can be used to ensure accuracy of results.
Poisson Distribution
Note: The variables used in this section are defined the same way as seen above in the "Binomial Distribution" section.
A Poisson distribution has several applications, and is essentially a derived limiting case of the binomial distribution. It is most applicably relevant to a situation in which the total number of successes is known, but the number of trials is not. An example of such a situation would be if you know the mean expected number of cancer cells present per sample and wanted to determine the probability of finding 1.5 times that amount of cells in any given sample, you would use a Poisson distribution.
In order to derive the Poisson distribution, you must first start off with the binomial distribution function.
\[P\{X-k\} = \frac{n!}{(n-k)! k!} p^{k}(1-p)^n \label{4A} \]
for \(k= 1,2,3 \ldots\).
Due to the fact that the Poisson distribution does not require an explicit statement of the total number of trials, you must eliminate n out of the binomial distribution function. This is done by first introducing a new variable (\(μ\)), which is defined as the expected number of successes during the given interval and can be mathematically described as:
\[\mu=n p \label{5} \]
We can then solve this equation for \(p\), substitute into Equation \ref{5}, and obtain Equation \ref{7}, which is a modified version of the binomial distribution function.
\[P\{X=k\}=\frac{n !}{(n-k) ! k !}\left(\frac{\mu}{n}\right)^{k}\left(1-\frac{\mu}{n}\right)^{n-k} \label{7} \]
If we keep μ finite and allow the sample size to approach infinity we obtain Equation \ref{8}, which is equal to the Poisson distribution function. (Notice to solve the Poisson distribution, you do not need to know the total number of trials)
\[P\{X=k\}=\frac{\mu^{k} e^{-\mu}}{k !} \label{8} \]
In the above equation:
- e is the base of the natural logarithm (e = 2.71828...)
- k is the number of occurrences of an event
- k! is the factorial of k
- μ is a positive real number, equal to the expected number of occurrences that occur during the given interval.
Using the Poisson distribution a probability versus number of successes plot can be made for several different numbers of successes.
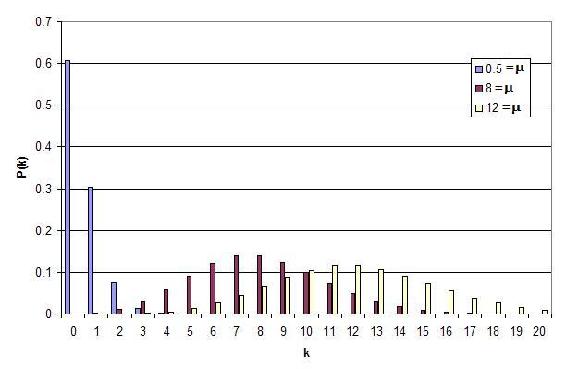
This graph represents several key characteristics of a Poisson process.
- The number of successes is independent of the time since the last event.
- Probabilities, or outcomes, are discrete.
- The probability of two or more successes in a short interval is extremely small (approximately zero).
These rules hint that the Poisson processes only model rare events, yet this is not true. What these characteristics say is that if you are limited to a small interval window, you will observe less than two events. It is important to know that the Poisson distribution is actually an approximation of the binomial distribution. As n increases and p decreases, the Poisson distribution becomes equal to the binomial distribution.
Hypergeometric Distribution
Note: The definitions of the variables in this section are different than the previous sections.
A hypergeometric distribution function is used only if the following three conditions can be met:
- Only two outcomes are possible
- The sample must be random
- Selections are not replaced
Hypergeometric distributions are used to describe samples where the selections from a binary set of items are not replaced. This distribution applies in situations with a discrete number of elements in a group of N items where there are K items that are different. As a simple example imagine we are removing 10 balls from a jar of mixed red and green balls without replacing it. What is the chance of selecting 2 green balls? 5 red balls? In general terms, if there are K green balls and N total balls , the chance of selecting k green balls by selecting n balls is given by
\[P(x=k)=\frac{(\# \text { of ways to select } k \text { green balls })(\# \text { of ways to select } n-k \text { red balls })}{(\text { total number of ways to select) }} \label{9} \]
As another example, say there are two reactants sitting in a CSTR totaling to N molecules. The third reactant can either react with A or B to make one of two products. Say now that there are K molecules of reactant A, and N-K molecules of reactant B. If we let n denote the number of molecules consumed, then the probability that k molecules of reactant of A were consumed can be described by the hypergeometric distribution. Note: This assumes that there is no reverse or side reactions with the products.
In mathematical terms this becomes
\[P\{X=k\}=\frac{(N-K) ! K ! n !(N-n) !}{k !(K-k) !(N-K+k-n) !(n-k) ! N !} label{10} \nonumber \]
where,
- N = total number of items
- K = total number of items with desired trait
- n = number of items in the sample
- k = number of items with desired trait in the sample
This can be written in shorthand as
\[P\{X=k\}=\frac{\left(\begin{array}{l}
K \\
k
\end{array}\right)\left(\begin{array}{l}
N-K \\
n-k
\end{array}\right)}{\left(\begin{array}{l}
N \\
n
\end{array}\right)} \label{11} \]
where
\[\left(\begin{array}{l}
A \\
B
\end{array}\right)=\frac{A !}{(A-B) ! B !} \label{12} \]
The formula can be simplified as follows: There are 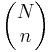 possible samples (without replacement). There are
possible samples (without replacement). There are 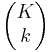 ways to obtain k green balls and there are
ways to obtain k green balls and there are 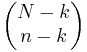 ways to fill out the rest of the sample with red balls.
ways to fill out the rest of the sample with red balls.
If the probabilities P are plotted versus k, then a distribution plot similar to the other types of distributions is seen.
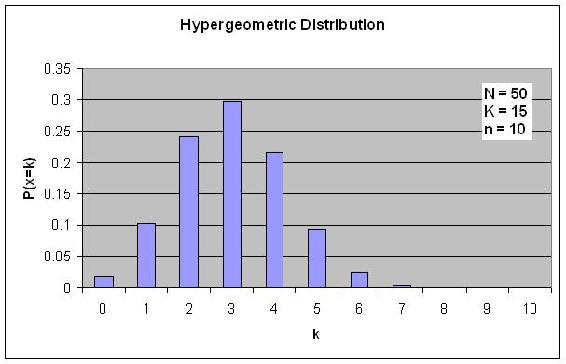
Suppose that you have a bag filled with 50 marbles, 15 of which are green. What is the probability of choosing exactly 3 green marbles if a total of 10 marbles are selected?
Solution
\[P\{X=3\}=\frac{\left(\begin{array}{c}15 \\ 3
\end{array}\right)\left(\begin{array}{c}
50-15 \\
10-3
\end{array}\right)}{\left(\begin{array}{c}
50 \\
10
\end{array}\right)}]
\[P\{X=3\}=\frac{(50-15) ! 15 ! 10 !(50-10) !}{3 !(15-3) !(50-15+3-10) !(10-3) ! 50 !} \nonumber \]
\[P\{X=3\}=0.2979 \nonumber \]
Fisher's exact
A special case of the hypergeometric distribution is the Fisher's exact method. Fisher's exact is the probability of sampling a specific configuration of a 2 by 2 table with constrained marginals. Marginals in this case refer to the sums for each row and each column. Therefore, every Fisher's exact will have 4 marginals, those 4 being the sum of the first column, the sum of the second column, the sum of the first row, and the sum of the second row. Since these values are constant, that also means that the sum of all the elements in the table will always equal the same thing. This is clarified with the image below:

In the image above, constant marginals would mean that E, F, G, and H would be held constant. Since those values would be constant, I would also be constant as I can be thought of as the sum of E and F or G and H are of which are constants.
In theory this test can be used for any 2 by 2 table, but most commonly, it is used when necessary sample size conditions for using the z-test or chi-square test are violated. The table below shows such a situation:
From this pfisher can be calculated:
\[p_{\text {fisher }}=\frac{(a+b) !(c+d) !(a+c) !(b+d) !}{(a+b+c+d) ! a ! b ! c ! d !} \nonumber \]
where the numerator is the number of ways the marginals can be arranged, the first term in the denominator is the number of ways the total can be arranged, and the remaining terms in the denominator are the number of ways each observation can be arranged.
As stated before, this calculated value is only the probability of creating the specific 2x2 from which the pfisher value was calculated.
Another way to calculate pfisher is to use Mathematica. The syntax as well as an example with numbers can be found in the screen shot below of the Mathematica notebook. For further clarification, the screen shot below also shows the calculated value of pfisher with numbers. This is useful to know because it reduces the chances of making a simple algebra error.

Another useful tool to calculate pfisher is using available online tools. The following link provides a helpful online calculator to quickly calculate pfisher. [1]
Using Mathematica or a similar calculating tool will greatly simplify the process of solving for pfisher.
After the value of pfisher is found, the p-value is the summation of the Fisher exact value(s) for the more extreme case(s), if applicable. The p-value determines whether the null hypothesis is true or false. An example of this can be found in the worked out hypergeometric distribution example below.
Finding the p-value
As elaborated further here: [2], the p-value allows one to either reject the null hypothesis or not reject the null hypothesis. Just because the null hypothesis isn't rejected doesn't mean that it is advocated, it just means that there isn't currently enough evidence to reject the null hypothesis.
In order to fine the p-value, it is necessary to find the probabilities of not only a specific table of results, but of results considered even more "extreme" and then sum those calculated probabilities. An example of this is shown below in example 2.
What is considered "more extreme" depends on the situation. In the most general sense, more extreme means further from the expected or random result.
Once the more extreme tables have been created and the probability for each value obtained, they can be added together to find the p-value corresponding to the least extreme table.
It is important to note that if the probabilities for every possible table were summed, the result would invariably be one. This should be expected as the probability of a table being included in the entire population of tables is 1.
The example table below correlates the the amount of time that one spent studying for an exam with how well one did on an exam.
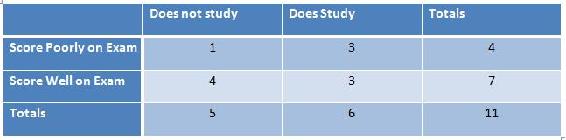
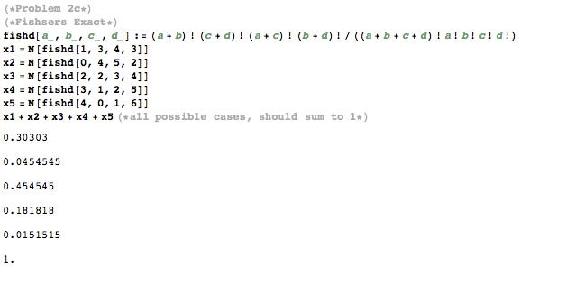
There are 5 possible configurations for the table above, which is listed in the Mathematica code below. All the pfisher for each configuration is shown in the Mathematica code below.
What are the odds of choosing the samples described in the table below with these marginals in this configuration or a more extreme one?
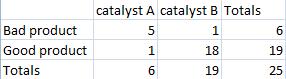
Solution
First calculate the probability for the initial configuration.
\[p_{\text {fisher }}=\frac{6 ! 19 ! 6 ! 19 !}{25 ! 5 ! 1 ! 1 ! 18 !}=0.000643704 \nonumber \]
Then create a new table that shows the most extreme case that also maintains the same marginals that were in the original table.
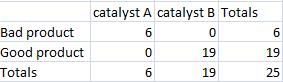
Then calculate the probability for the most extreme case.
\[p_{\text {fisher }}=\frac{6 ! 19 ! 6 ! 19 !}{25 ! 6 ! 0 ! 0 ! 19 !}=0.00000564653 \nonumber \]
Finally add the two probabilities together.
\[p_{fisher} = 0.000643704 + 0.00000564653 = 0.00064 \nonumber \]
Maximum Entropy Function
The maximum entropy principle uses all the testable information about multiple given probability distributions to describe the true probability distribution by maximizing the information entropy. To derive a distribution with the maximum entropy principle, you obtain some testable information I about some quantity x. This information is expressed as m constraints on the expectation values of the functions fk. This makes the Bayesian probability distribution to satisfy:
\[F_{k}=\sum_{i=1}^{n} \operatorname{Pr}\left(x_{i} \mid I\right) f_{k}\left(x_{i}\right) \nonumber \]
with \(k=1, \cdots, m\).
We also know that all of these probabilities must sum to 1, so the following constraint is introduced:
\[\sum_{i=1}^{n} \operatorname{Pr}\left(x_{i} \mid I\right)=1 \nonumber \]
Then the probability distribution with maximum information entropy that satisfies all these constraints is:
\[\operatorname{Pr}\left(x_{i} \mid I\right)=\frac{1}{Z\left(\lambda_{1}, \cdots, \lambda_{m}\right)} \exp \left[\lambda_{1} f_{1}\left(x_{i}\right)+\cdots+\lambda_{m} f_{m}\left(x_{i}\right)\right] \nonumber \]
The normalization constant is determined by the classical partition function:
\[Z\left(\lambda_{1}, \cdots, \lambda_{m}\right)=\sum_{i=1}^{n} \exp \left[\lambda_{1} f_{1}\left(x_{i}\right)+\cdots+\lambda_{m} f_{m}\left(x_{i}\right)\right] \nonumber \]
The λk parameters are Lagrange multipliers with values determined by:
\[F_{k}=\frac{\partial}{\partial \lambda_{k}} \log Z\left(\lambda_{1}, \cdots, \lambda_{m}\right) \nonumber \]
All of the well-known distributions in statistics are maximum entropy distributions given appropriate moment constraints. For example, if we assume that the above was constrained by the second moment, and then one would derive the Gaussian distribution with a mean of 0 and a variance of the second moment.
The use of the maximum entropy distribution function will soon become more predominant. In 2007 it had been shown that Bayes’ Rule and the Principle of Maximum Entropy were compatible. It was also shown that maximum entropy reproduces every aspect of orthodox Bayesian inference methods. This enables engineers to tackle problems that could not be simply addressed by the principle of maximum entropy or Bayesian methods, individually, in the past.
Summary
The three discrete distributions that are discussed in this article include the Binomial, Hypergeometric, and Poisson distributions. These distributions are useful in finding the chances that a certain random variable will produce a desired outcome.
Binomial Distribution Function
The Binomial distribution function is used when there are only two possible outcomes, a success or a faliure. A success occurs with the probability p and a failure with the probability 1-p. Suppose now that in n independent trials the binomial random variable X represents the number of successes. The following equation applies to binomial random variables:
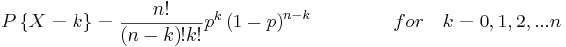
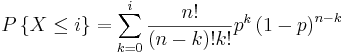
Poisson Distribution Function
The Poisson distribution can be used in a large variety of situations. It can also be used to approximate the Binomial Distribution when n is large and p is small yielding a moderate np.
The following example is a situation in which the Poisson Distribution applies: Suppose a CSTR is full of molecules and the probability of any one molecule reacting to form product is small (say due to a low temperature) while the number of molecules is large, then the probability distribution function would fit the Poisson Distribution well (Note: all the molecules are the same here, unlike in the hypergeometric example to follow). Other examples include, the number of wrong telephone numbers that are dialed each day or the number of people in a community that live to 100 years of age. The following equation is the Poisson Distribution function:

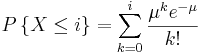
Summary of Key Distributions
Summary of Distribution Approximations
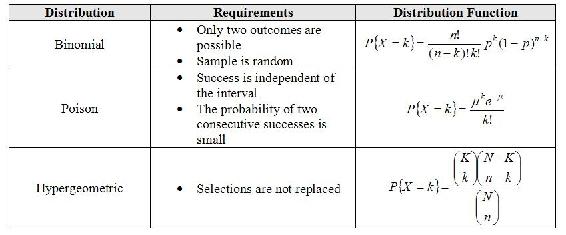
There are many useful approximations for discrete random variables. An important approximation is that which yields a normal distribution because it allows for confidence intervals and probabilities to be continuous. Additionally, since the normal distribution is so well understood it is used for convenience when speaking to those who have yet to study probability theory. Below is a table of useful approximations. The majority of the theory behind these approximations is in the application of the Central Limit Theorem and Large Number Law but these are outside the scope of this text.

The above chart can be read as "A random variable under the following distribution can is approximately a <blank> random variable when the following requirements are met." For example, the final line of the table can be read: "A random variable following a Poisson distribution with parameter λ is approximately a continuous Normal random variable where the mean is λ and the variance is λ assuming that there are at least 100 samples that have been taken."
In order for a vaccination of Polio to be efficient, the shot must contain at least 67% of the appropriate molecule, VPOLIO. To ensure efficacy, a large pharmaceutical company manufactured a batch of vaccines with each syringe containing 75% VPOLIO. Your doctor draws a syringe from this batch which should contain 75% VPOLIO. What is the probability that your shot, will successfully prevent you from acquiring Polio? Assume the syringe contains 100 molecules and that all molecules are able to be delivered from the syringe to your blood stream.
Solution
This can be done by first setting up the binomial distribution function. In order to do this, it is best to set up an Excel spreadsheet with values of k from 0 to 100, including each integer. The frequency of pulling a VPOLIO molecule is 0.75. Randomly drawing any molecule, the probability that this molecule will never be VPOLIO, or in other words, the probability of your shot containing 0 VPOLIO molecules is
\[P=\frac{100 !}{(100-0 !) ! 0 !}(0.75)^{0}(1-0.75)^{100-0} \nonumber \]
Note that 0!=1
Your spreadsheet should contain probabilities for all off the possible values of VPOLIO in the shot. A link to our spreadsheet can be seen at the end of this article. A graph of our distribution is shown below.
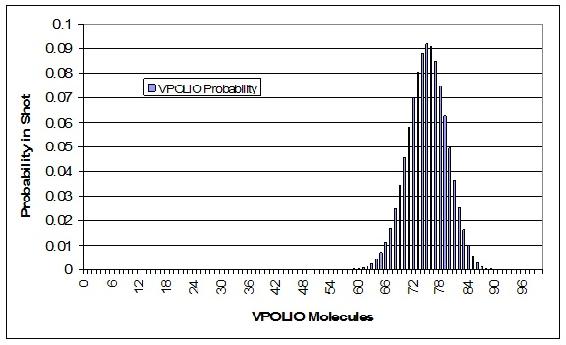
The next step is to sum the probabilities from 67 to 100 of the molecules being VPOLIO. This is calculation is shown in the sample spreadsheet. The total probability of at least 67 of the molecules being VPOLIO is 0.9724. Thus, there is a 97.24% chance that you will be protected from Polio.
Calculation of the binomial function with n greater than 20 can be tedious, whereas calculation of the Gauss function is always simple. To illustrate this, consider the following example.
Suppose we want to know the probability of getting 23 heads in 36 tosses of a coin. This probability is given by the following binomial distribution:
\[P=\frac{36 !}{23 ! 13 !}(0.5)^{36}=3.36 \% \nonumber \]
To use a Gaussian Approximation, we must first calculate the mean and standard deviation.
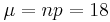
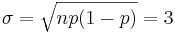
Now we can approximate the probability by the Gauss function below.
\[P=\frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{(x-X)^{2}}{2 \sigma^{2}}}=3.32 \% \nonumber \]
This approximation is very close and requires much less calculation due to the lack of factorials. The usefulness of the Gaussian approximation is even more apparent when n is very large and the factorials involve very intensive calculation.
A teacher has 12 students in her class. On her most recent exam, 7 students failed while the other 5 students passed. Curious as to why so many students failed the exam, she took a survey, asking the students whether or not they studied the night before. Of the students who failed, 4 students did study and 3 did not. Of the students who passed, 1 student did study and 4 did not. After seeing the results of this survey, the teacher concludes that those who study will almost always fail, and she proceeds to enforce a "no-studying" policy. Was this the correct conclusion and action?
Solution
This is a perfect situation to apply the Fisher's exact test to determine if there is any association between studying and performance on the exam. First, create a 2 by 2 table describing this particular outcome for the class, and then calculate the probability of seeing this exact configuration. This is shown below.
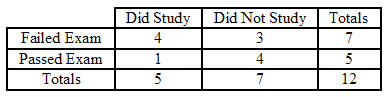
\[p_{\text {fisher }, 1}=\frac{(4+3) !(1+4) !(4+1) !(3+4) !}{(4+3+1+4) ! 4 ! 3 ! 1 ! 4 !}=0.221 \nonumber \]
Next, create 2 by 2 tables describing any configurations with the exact same marginals that are more extreme than the one shown above, and then calculate the probability of seeing each configuration. Fortunately, for this example, there is only one configuration that is more extreme, which is shown below.
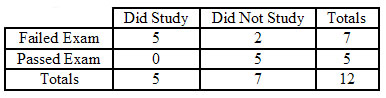
\[p_{\text {fisher }, 2}=\frac{(5+2) !(0+5) !(5+0) !(2+5) !}{(5+2+0+5) ! 5 ! 2 ! 0 ! 5 !}=0.0265 \nonumber \]
Finally, test the significance by calculating the p-value for the problem statement. This is done by adding up all the previously calculated probabilities.
\[p=p_{\text {fisher }, 1}+p_{\text {fisher }, 2}=0.221+0.0265=0.248 \nonumber \]
Thus, the p-value is greater than 0.05, which is the standard accepted level of confidence. Therefore, the null hypothesis cannot be rejected, which means there is no significant association between studying and performance on the exam. Unfortunately, the teacher was wrong to enforce a "no-studying" policy.
The hormone PREGO is only found in the female human body during the onset of pregnancy. There is only 1 hormone molecule per 10,000 found in the urine of a pregnant woman. If we are given a sample of 5,000 hormone molecules what is the probability of finding exactly 1 PREGO? If we need at least 10 PREGO molecules to be 95% positive that a woman is pregnant, how many total hormone molecules must we collect? If the concentration of hormone molecules in the urine is 100,000 molecules/mL of urine,what is the minimum amount of urine (in mL) necessary to insure an accurate test(95% positive for pregnancy)?
Solution
This satisfies the characteristics of a Poisson process because
- PREGO hormone molecules are randomly distributed in the urine
- Hormone molecule numbers are discrete
- If the interval size is made smaller (i.e. our sample size is reduced), the probability of finding a PREGO hormone molecule goes to zero
Therefore we will assume that the number of PREGO hormone molecules is distributed according to a Poisson distribution.
To answer the first question, we begin by finding the expected number of PREGO hormone molecules:
\[\mu=n p \nonumber \]
\[\mu=(5,000)\left(\frac{1}{10,000}\right)=0.5 \nonumber \]
Next we use the Poisson distribution to calculate the probability of finding exactly one PREGO hormone molecule:
\[P\{X=k\}=\frac{\mu^{k} e^{-\mu}}{k !}=0.303 \nonumber \]
where \(k=1\) and \(\mu=0.5\).
The second problem is more difficult because we are calculating n. We begin as before by calculating the expected number of PREGO hormone molecules:
\[\mu=n p=\frac{n}{10,000} \nonumber \]
Now we apply the Poisson Distribution Function equation:
\[F\{X \geq 10\}-0.95-\sum_{k=1}^{\infty} \frac{\mu^{k} e^{\mu}}{k !}-1.0-\sum_{k=0}^{-5} \frac{\mu^{k} e^{\mu}}{k !}-1.0-\sum_{k=1}^{10}\left(\left(\frac{n^{\prime}}{10.000}\right)^{k} \frac{\left.e^{-\left(\frac{u}{k, 00 !}\right.}\right)}{k !}\right) \nonumber \]
It is easiest to solve this in Mathematica:

The function FindRoot[] was used in Mathematica because the Solve[] function has problems solving polynomials of degree order greater than 4 as well as exponential functions. However, FindRoot[] requires an initial guess for the variable trying to be solved, in this case n was estimated to be around 100,000. As you can see from the Mathematica screen shot the total number of hormone molecules necessary to be 95% sure of pregnancy (or 95% chance of having atleast 10 PREGO molecules) was 169,622 molecules.
For the last step we use the concentration of total hormone molecules found in the urine and calculate the volume of urine required to contain 169,622 total hormone molecules as this will yield a 95% chance of an accurate test:
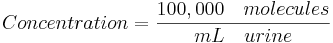
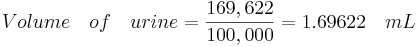
To illustrate the Gaussian approximation to the Poisson distribution, consider a distribution where the mean (\(μ\)) is 64 and the number of observations in a definite interval (\(N\)) is 72. Determine the probability of these 72 observations?
Solution
Using the Poisson Distribution
\[\begin{align*}
P(N) &=e^{-\mu} \cdot \frac{\mu^{N}}{N !} \\[4pt]
P(72) &=e^{-64} \cdot \frac{64^{7} 2}{72 !}=2.9 \%
\end{align*} \nonumber \]
This can be difficult to solve when the parameters \(N\) and \(μ\) are large. An easier approximation can be done with the Gaussian function:
\[P(72)=G_{64,8}=\frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{(x-X)^{2}}{2 \sigma^{2}}}=3.0 \% \nonumber \]
where, \(X=μ\) and \(σ= \sqrt{\mu}\).
All of the following are characteristics of the Poisson distribution EXCEPT:
- The number of successes is independent of the interval
- There are imaginary numbers
- Probabilities, or outcomes, are discrete
- Two or more success in a short interval is extremely small
- Answer
-
TBA
If there are K blue balls and N total balls , the chance of selecting k blue balls by selecting n balls in shorthand notation is given by:
a)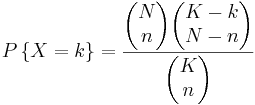
b)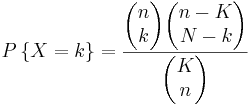
c)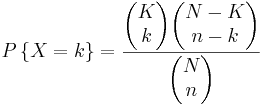
d)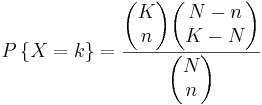
- Answer
-
TBA
Discrete Distribution Presentation: Clown Time
www.youtube.com/v/6WOieU664Ew
References
- Ross, Sheldon: A First Course in Probability. Upper Saddle River: Prentice Hall, Chapter 4.
- Uts, J. and R. Hekerd. Mind on Statistics. Chapter 15 - More About Inference for Categorical Variables. Belmont, CA: Brooks/Cole - Thomson Learning, Inc. 2004.
- Weisstein, Eric W.: MathWorld - Discrete Distributions. Date Accessed: 20 November 2006. MathWorld
- Woolf, Peter and Amy Keating, Christopher Burge, Michael Yaffe: Statistics and Probability Primer for Computational Biologists. Boston: Massachusetts Institute of Technology, pp 3.1 - 3.21.
- Wikipedia-Principle of maximum entropy. Date Accessed: 10 December 2008. [3]
- Giffin, A. and Caticha, A., 2007,[4].