
13.2: XFastTrie - Searching in Doubly-Logarithmic Time
- Page ID
- 8491

The performance of the BinaryTrie structure is not very impressive. The number of elements, \(\mathtt{n}\), stored in the structure is at most \(2^{\mathtt{w}}\), so \(\log \mathtt{n}\le \mathtt{w}\). In other words, any of the comparison-based SSet structures described in other parts of this book are at least as efficient as a BinaryTrie, and are not restricted to only storing integers.
Next we describe the XFastTrie, which is just a BinaryTrie with \(\mathtt{w+1}\) hash tables--one for each level of the trie. These hash tables are used to speed up the \(\mathtt{find(x)}\) operation to \(O(\log \mathtt{w})\) time. Recall that the \(\mathtt{find(x)}\) operation in a BinaryTrie is almost complete once we reach a node, \(\mathtt{u}\), where the search path for \(\mathtt{x}\) would like to proceed to \(\texttt{u.right}\) (or \(\texttt{u.left}\)) but \(\mathtt{u}\) has no right (respectively, left) child. At this point, the search uses \(\texttt{u.jump}\) to jump to a leaf, \(\mathtt{v}\), of the BinaryTrie and either return \(\mathtt{v}\) or its successor in the linked list of leaves. An XFastTrie speeds up the search process by using binary search on the levels of the trie to locate the node \(\mathtt{u}\).
To use binary search, we need a way to determine if the node \(\mathtt{u}\) we are looking for is above a particular level, \(\mathtt{i}\), of if \(\mathtt{u}\) is at or below level \(\mathtt{i}\). This information is given by the highest-order \(\mathtt{i}\) bits in the binary representation of \(\mathtt{x}\); these bits determine the search path that \(\mathtt{x}\) takes from the root to level \(\mathtt{i}\). For an example, refer to Figure \(\PageIndex{1}\); in this figure the last node, \(\mathtt{u}\), on search path for 14 (whose binary representation is 1110) is the node labelled \(11{\star\star}\) at level 2 because there is no node labelled \(111{\star}\) at level 3. Thus, we can label each node at level \(\mathtt{i}\) with an \(\mathtt{i}\)-bit integer. Then, the node \(\mathtt{u}\) we are searching for would be at or below level \(\mathtt{i}\) if and only if there is a node at level \(\mathtt{i}\) whose label matches the highest-order \(\mathtt{i}\) bits of \(\mathtt{x}\).
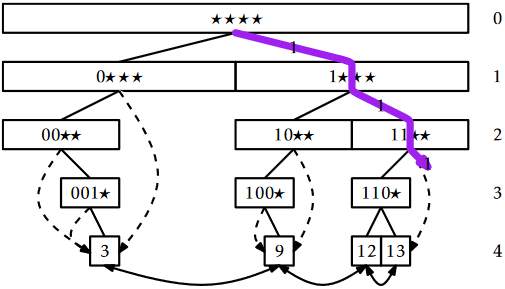
In an XFastTrie, we store, for each \(\mathtt{i}\in\{0,\ldots,\mathtt{w}\}\), all the nodes at level \(\mathtt{i}\) in a USet, \(\mathtt{t[i]}\), that is implemented as a hash table (Chapter 5). Using this USet allows us to check in constant expected time if there is a node at level \(\mathtt{i}\) whose label matches the highest-order \(\mathtt{i}\) bits of \(\mathtt{x}\). In fact, we can even find this node using \(\mathtt{t[i]\texttt{.}find(x\text{>>>}(w-i))}\)
The hash tables \(\mathtt{t[0]},\ldots,\mathtt{t[w]}\) allow us to use binary search to find \(\mathtt{u}\). Initially, we know that \(\mathtt{u}\) is at some level \(\mathtt{i}\) with \(0\le \mathtt{i}< \mathtt{w}+1\). We therefore initialize \(\mathtt{l}=0\) and \(\mathtt{h}=\mathtt{w}+1\) and repeatedly look at the hash table \(\mathtt{t[i]}\), where \(\mathtt{i}=\lfloor(\mathtt{l+h})/2\rfloor\). If \(\mathtt{t[i]}\) contains a node whose label matches \(\mathtt{x}\)'s highest-order \(\mathtt{i}\) bits then we set \(\mathtt{l=i}\) ( \(\mathtt{u}\) is at or below level \(\mathtt{i}\)); otherwise we set \(\mathtt{h=i}\) ( \(\mathtt{u}\) is above level \(\mathtt{i}\)). This process terminates when \(\mathtt{h-l}\le 1\), in which case we determine that \(\mathtt{u}\) is at level \(\mathtt{l}\). We then complete the \(\mathtt{find(x)}\) operation using \(\texttt{u.jump}\) and the doubly-linked list of leaves.
T find(T x) {
int l = 0, h = w+1, ix = it.intValue(x);
Node v, u = r, q = newNode();
while (h-l > 1) {
int i = (l+h)/2;
q.prefix = ix >>> w-i;
if ((v = t[i].find(q)) == null) {
h = i;
} else {
u = v;
l = i;
}
}
if (l == w) return u.x;
Node pred = (((ix >>> w-l-1) & 1) == 1)
? u.jump : u.jump.child[0];
return (pred.child[next] == dummy)
? null : pred.child[next].x;
}
Each iteration of the \(\mathtt{while}\) loop in the above method decreases \(\mathtt{h-l}\) by roughly a factor of two, so this loop finds \(\mathtt{u}\) after \(O(\log \mathtt{w})\) iterations. Each iteration performs a constant amount of work and one \(\mathtt{find(x)}\) operation in a USet, which takes a constant expected amount of time. The remaining work takes only constant time, so the \(\mathtt{find(x)}\) method in an XFastTrie takes only \(O(\log\mathtt{w})\) expected time.
The \(\mathtt{add(x)}\) and \(\mathtt{remove(x)}\) methods for an XFastTrie are almost identical to the same methods in a BinaryTrie. The only modifications are for managing the hash tables \(\mathtt{t[0]}\),..., \(\mathtt{t[w]}\). During the \(\mathtt{add(x)}\) operation, when a new node is created at level \(\mathtt{i}\), this node is added to \(\mathtt{t[i]}\). During a \(\mathtt{remove(x)}\) operation, when a node is removed form level \(\mathtt{i}\), this node is removed from \(\mathtt{t[i]}\). Since adding and removing from a hash table take constant expected time, this does not increase the running times of \(\mathtt{add(x)}\) and \(\mathtt{remove(x)}\) by more than a constant factor. We omit a code listing for \(\mathtt{add(x)}\) and \(\mathtt{remove(x)}\) since the code is almost identical to the (long) code listing already provided for the same methods in a BinaryTrie.
The following theorem summarizes the performance of an XFastTrie:
Theorem \(\PageIndex{1}\).
An XFastTrie implements the SSet interface for \(\mathtt{w}\)-bit integers. An XFastTrie supports the operations
- \(\mathtt{add(x)}\) and \(\mathtt{remove(x)}\) in \(O(\mathtt{w})\) expected time per operation and
- \(\mathtt{find(x)}\) in \(O(\log \mathtt{w})\) expected time per operation.
The space used by an XFastTrie that stores \(\mathtt{n}\) values is \(O(\mathtt{n}\cdot\mathtt{w})\).