
6.2: Parsing HTML
- Page ID
- 12758

When you download a web page, the contents are written in HyperText Markup Language, aka HTML. For example, here is a minimal HTML document:
<!DOCTYPE html>
<html>
<head>
<title>This is a title</title>
</head>
<body>
Hello world!</p>
</body>
</html>
The phrases “This is a title” and “Hello world!” are the text that actually appears on the page; the other elements are tags that indicate how the text should be displayed.
When our crawler downloads a page, it will need to parse the HTML in order to extract the text and find the links. To do that, we’ll use jsoup, which is an open-source Java library that downloads and parses HTML.
The result of parsing HTML is a Document Object Model tree, or DOM tree, that contains the elements of the document, including text and tags. The tree is a linked data structure made up of nodes; the nodes represent text, tags, and other document elements.
The relationships between the nodes are determined by the structure of the document. In the example above, the first node, called the root, is the <html> tag, which contains links to the two nodes it contains, <head> and <body>; these nodes are the children of the root node.
The <head> node has one child, <title>, and the <body> node has one child,
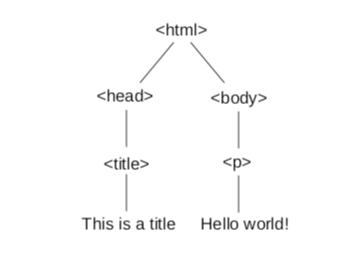
Figure \(\PageIndex{1}\): DOM tree for a simple HTML page.
Each node contains links to its children; in addition, each node contains a link to its parent, so from any node it is possible to navigate up and down the tree. The DOM tree for real pages is usually more complicated than this example.
Most web browsers provide tools for inspecting the DOM of the page you are viewing. In Chrome, you can right-click on any part of a web page and select “Inspect” from the menu that pops up. In Firefox, you can right-click and select “Inspect Element” from the menu. Safari provides a tool called Web Inspector, which you can read about at thinkdast.com/safari. For Internet Explorer, you can read the instructions at thinkdast.com/explorer.
Figure \(\PageIndex{2}\) shows a screenshot of the DOM for the Wikipedia page on Java, thinkdast.com/java. The element that’s highlighted is the first paragraph of the main text of the article, which is contained in a element with . We’ll use this element id to identify the main text of each article we download.

Figure \(\PageIndex{2}\): Screenshot of the Chrome DOM Inspector.