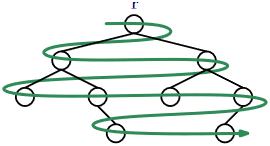
6.1: BinaryTree - A Basic Binary Tree
- Page ID
- 8461

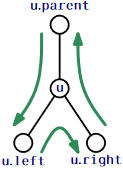
The simplest way to represent a node, \(\mathtt{u}\), in a binary tree is to explicitly store the (at most three) neighbours of \(\mathtt{u}\):
class BTNode<Node extends BTNode<Node>> {
Node left;
Node right;
Node parent;
}
When one of these three neighbours is not present, we set it to \(\mathtt{nil}\). In this way, both external nodes of the tree and the parent of the root correspond to the value \(\mathtt{nil}\).
The binary tree itself can then be represented by a reference to its root node, \(\mathtt{r}\):
Node r;
We can compute the depth of a node, \(\mathtt{u}\), in a binary tree by counting the number of steps on the path from \(\mathtt{u}\) to the root:
int depth(Node u) {
int d = 0;
while (u != r) {
u = u.parent;
d++;
}
return d;
}
\(\PageIndex{1}\) Recursive Algorithms
Using recursive algorithms makes it very easy to compute facts about binary trees. For example, to compute the size of (number of nodes in) a binary tree rooted at node \(\mathtt{u}\), we recursively compute the sizes of the two subtrees rooted at the children of \(\mathtt{u}\), sum up these sizes, and add one:
int size(Node u) {
if (u == nil) return 0;
return 1 + size(u.left) + size(u.right);
}
To compute the height of a node \(\mathtt{u}\), we can compute the height of \(\mathtt{u}\)'s two subtrees, take the maximum, and add one:
int height(Node u) {
if (u == nil) return -1;
return 1 + Math.max(height(u.left), height(u.right));
}
\(\PageIndex{2}\) Traversing Binary Trees
The two algorithms from the previous section both use recursion to visit all the nodes in a binary tree. Each of them visits the nodes of the binary tree in the same order as the following code:
void traverse(Node u) {
if (u == nil) return;
traverse(u.left);
traverse(u.right);
}
Using recursion this way produces very short, simple code, but it can also be problematic. The maximum depth of the recursion is given by the maximum depth of a node in the binary tree, i.e., the tree's height. If the height of the tree is very large, then this recursion could very well use more stack space than is available, causing a crash.
To traverse a binary tree without recursion, you can use an algorithm that relies on where it came from to determine where it will go next. See Figure \(\PageIndex{1}\). If we arrive at a node \(\mathtt{u}\) from \(\texttt{u.parent}\), then the next thing to do is to visit \(\texttt{u.left}\). If we arrive at \(\mathtt{u}\) from \(\texttt{u.left}\), then the next thing to do is to visit \(\texttt{u.right}\). If we arrive at \(\mathtt{u}\) from \(\texttt{u.right}\), then we are done visiting \(\mathtt{u}\)'s subtree, and so we return to \(\texttt{u.parent}\). The following code implements this idea, with code included for handling the cases where any of \(\texttt{u.left}\), \(\texttt{u.right}\), or \(\texttt{u.parent}\) is \(\mathtt{nil}\):
void traverse2() {
Node u = r, prev = nil, next;
while (u != nil) {
if (prev == u.parent) {
if (u.left != nil) next = u.left;
else if (u.right != nil) next = u.right;
else next = u.parent;
} else if (prev == u.left) {
if (u.right != nil) next = u.right;
else next = u.parent;
} else {
next = u.parent;
}
prev = u;
u = next;
}
}
The same facts that can be computed with recursive algorithms can also be computed in this way, without recursion. For example, to compute the size of the tree we keep a counter, \(\mathtt{n}\), and increment \(\mathtt{n}\) whenever visiting a node for the first time:
int size2() {
Node u = r, prev = nil, next;
int n = 0;
while (u != nil) {
if (prev == u.parent) {
n++;
if (u.left != nil) next = u.left;
else if (u.right != nil) next = u.right;
else next = u.parent;
} else if (prev == u.left) {
if (u.right != nil) next = u.right;
else next = u.parent;
} else {
next = u.parent;
}
prev = u;
u = next;
}
return n;
}
In some implementations of binary trees, the \(\mathtt{parent}\) field is not used. When this is the case, a non-recursive implementation is still possible, but the implementation has to use a List (or Stack) to keep track of the path from the current node to the root.
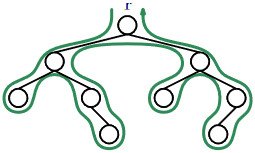
A special kind of traversal that does not fit the pattern of the above functions is the breadth-first traversal. In a breadth-first traversal, the nodes are visited level-by-level starting at the root and moving down, visiting the nodes at each level from left to right (see Figure \(\PageIndex{2}\)). This is similar to the way that we would read a page of English text. Breadth-first traversal is implemented using a queue, \(\mathtt{q}\), that initially contains only the root, \(\mathtt{r}\). At each step, we extract the next node, \(\mathtt{u}\), from \(\mathtt{q}\), process \(\mathtt{u}\) and add \(\texttt{u.left}\) and \(\texttt{u.right}\) (if they are non-\(\mathtt{nil}\)) to \(\mathtt{q}\):
void bfTraverse() {
Queue<Node> q = new LinkedList<Node>();
if (r != nil) q.add(r);
while (!q.isEmpty()) {
Node u = q.remove();
if (u.left != nil) q.add(u.left);
if (u.right != nil) q.add(u.right);
}
}