
13.1: BinaryTrie - A digital search tree
- Page ID
- 8490

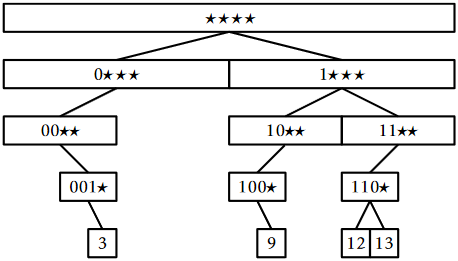
A BinaryTrie encodes a set of \(\mathtt{w}\) bit integers in a binary tree. All leaves in the tree have depth \(\mathtt{w}\) and each integer is encoded as a root-to-leaf path. The path for the integer \(\mathtt{x}\) turns left at level \(\mathtt{i}\) if the \(\mathtt{i}\)th most significant bit of \(\mathtt{x}\) is a 0 and turns right if it is a 1. Figure \(\PageIndex{1}\) shows an example for the case \(\mathtt{w}=4\), in which the trie stores the integers 3(0011), 9(1001), 12(1100), and 13(1101).
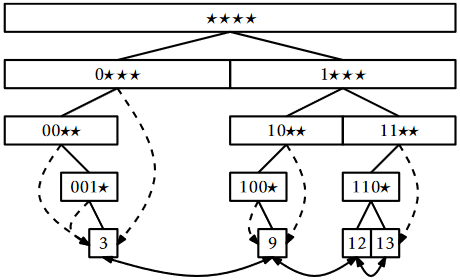
Because the search path for a value \(\mathtt{x}\) depends on the bits of \(\mathtt{x}\), it will be helpful to name the children of a node, \(\mathtt{u}\), \(\texttt{u.child[0]}\) (\(\mathtt{left}\)) and \(\texttt{u.child[1]}\) (\(\mathtt{right}\)). These child pointers will actually serve double-duty. Since the leaves in a binary trie have no children, the pointers are used to string the leaves together into a doubly-linked list. For a leaf in the binary trie \(\texttt{u.child[0]}\) (\(\mathtt{prev}\)) is the node that comes before \(\mathtt{u}\) in the list and \(\texttt{u.child[1]}\) (\(\mathtt{next}\)) is the node that follows \(\mathtt{u}\) in the list. A special node, \(\mathtt{dummy}\), is used both before the first node and after the last node in the list (see Section 3.2).
Each node, \(\mathtt{u}\), also contains an additional pointer \(\texttt{u.jump}\). If \(\mathtt{u}\)'s left child is missing, then \(\texttt{u.jump}\) points to the smallest leaf in \(\mathtt{u}\)'s subtree. If \(\mathtt{u}\)'s right child is missing, then \(\texttt{u.jump}\) points to the largest leaf in \(\mathtt{u}\)'s subtree. An example of a BinaryTrie, showing \(\mathtt{jump}\) pointers and the doubly-linked list at the leaves, is shown in Figure \(\PageIndex{2}\).
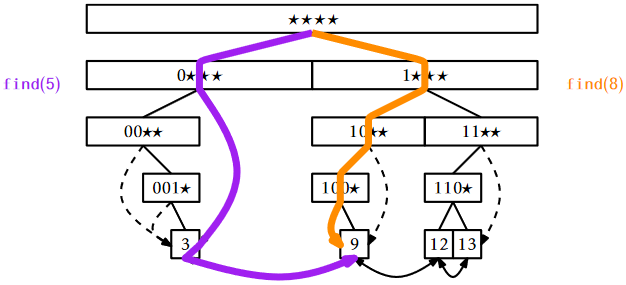
The \(\mathtt{find(x)}\) operation in a BinaryTrie is fairly straightforward. We try to follow the search path for \(\mathtt{x}\) in the trie. If we reach a leaf, then we have found \(\mathtt{x}\). If we reach a node \(\mathtt{u}\) where we cannot proceed (because \(\mathtt{u}\) is missing a child), then we follow \(\texttt{u.jump}\), which takes us either to the smallest leaf larger than \(\mathtt{x}\) or the largest leaf smaller than \(\mathtt{x}\). Which of these two cases occurs depends on whether \(\mathtt{u}\) is missing its left or right child, respectively. In the former case (\(\mathtt{u}\) is missing its left child), we have found the node we want. In the latter case (\(\mathtt{u}\) is missing its right child), we can use the linked list to reach the node we want. Each of these cases is illustrated in Figure \(\PageIndex{3}\).
T find(T x) {
int i, c = 0, ix = it.intValue(x);
Node u = r;
for (i = 0; i < w; i++) {
c = (ix >>> w-i-1) & 1;
if (u.child[c] == null) break;
u = u.child[c];
}
if (i == w) return u.x; // found it
u = (c == 0) ? u.jump : u.jump.child[next];
return u == dummy ? null : u.x;
}
The running-time of the \(\mathtt{find(x)}\) method is dominated by the time it takes to follow a root-to-leaf path, so it runs in \(O(\mathtt{w})\) time.
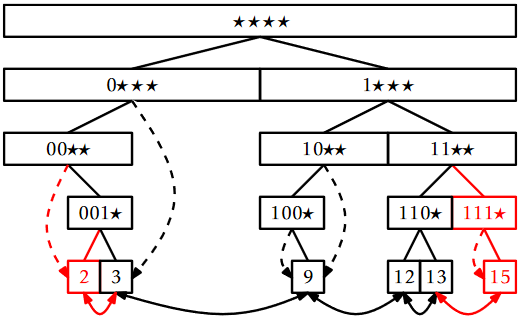
The \(\mathtt{add(x)}\) operation in a BinaryTrie is also fairly straightforward, but has a lot of work to do:
- It follows the search path for \(\mathtt{x}\) until reaching a node \(\mathtt{u}\) where it can no longer proceed.
- It creates the remainder of the search path from \(\mathtt{u}\) to a leaf that contains \(\mathtt{x}\).
- It adds the node, \(\mathtt{u'}\), containing \(\mathtt{x}\) to the linked list of leaves (it has access to the predecessor, \(\mathtt{pred}\), of \(\mathtt{u'}\) in the linked list from the \(\mathtt{jump}\) pointer of the last node, \(\mathtt{u}\), encountered during step 1.)
- It walks back up the search path for \(\mathtt{x}\) adjusting \(\mathtt{jump}\) pointers at the nodes whose \(\mathtt{jump}\) pointer should now point to \(\mathtt{x}\).
An addition is illustrated in Figure \(\PageIndex{4}\).
boolean add(T x) {
int i, c = 0, ix = it.intValue(x);
Node u = r;
// 1 - search for ix until falling out of the trie
for (i = 0; i < w; i++) {
c = (ix >>> w-i-1) & 1;
if (u.child[c] == null) break;
u = u.child[c];
}
if (i == w) return false; // already contains x - abort
Node pred = (c == right) ? u.jump : u.jump.child[0];
u.jump = null; // u will have two children shortly
// 2 - add path to ix
for (; i < w; i++) {
c = (ix >>> w-i-1) & 1;
u.child[c] = newNode();
u.child[c].parent = u;
u = u.child[c];
}
u.x = x;
// 3 - add u to linked list
u.child[prev] = pred;
u.child[next] = pred.child[next];
u.child[prev].child[next] = u;
u.child[next].child[prev] = u;
// 4 - walk back up, updating jump pointers
Node v = u.parent;
while (v != null) {
if ((v.child[left] == null
&& (v.jump == null || it.intValue(v.jump.x) > ix))
|| (v.child[right] == null
&& (v.jump == null || it.intValue(v.jump.x) < ix)))
v.jump = u;
v = v.parent;
}
n++;
return true;
}
This method performs one walk down the search path for \(\mathtt{x}\) and one walk back up. Each step of these walks takes constant time, so the \(\mathtt{add(x)}\) method runs in \(O(\mathtt{w})\) time.
The \(\mathtt{remove(x)}\) operation undoes the work of \(\mathtt{add(x)}\). Like \(\mathtt{add(x)}\), it has a lot of work to do:
- It follows the search path for \(\mathtt{x}\) until reaching the leaf, \(\mathtt{u}\), containing \(\mathtt{x}\).
- It removes \(\mathtt{u}\) from the doubly-linked list.
- It deletes \(\mathtt{u}\) and then walks back up the search path for \(\mathtt{x}\) deleting nodes until reaching a node \(\mathtt{v}\) that has a child that is not on the search path for \(\mathtt{x}\).
- It walks upwards from \(\mathtt{v}\) to the root updating any \(\mathtt{jump}\) pointers that point to \(\mathtt{u}\).
A removal is illustrated in Figure \(\PageIndex{5}\).

boolean remove(T x) {
// 1 - find leaf, u, containing x
int i, c, ix = it.intValue(x);
Node u = r;
for (i = 0; i < w; i++) {
c = (ix >>> w-i-1) & 1;
if (u.child[c] == null) return false;
u = u.child[c];
}
// 2 - remove u from linked list
u.child[prev].child[next] = u.child[next];
u.child[next].child[prev] = u.child[prev];
Node v = u;
// 3 - delete nodes on path to u
for (i = w-1; i >= 0; i--) {
c = (ix >>> w-i-1) & 1;
v = v.parent;
v.child[c] = null;
if (v.child[1-c] != null) break;
}
// 4 - update jump pointers
c = (ix >>> w-i-1) & 1;
v.jump = u.child[1-c];
v = v.parent;
i--;
for (; i >= 0; i--) {
c = (ix >>> w-i-1) & 1;
if (v.jump == u)
v.jump = u.child[1-c];
v = v.parent;
}
n--;
return true;
}
Theorem \(\PageIndex{1}\).
A BinaryTrie implements the SSet interface for \(\mathtt{w}\)-bit integers. A BinaryTrie supports the operations \(\mathtt{add(x)}\), \(\mathtt{remove(x)}\), and \(\mathtt{find(x)}\) in \(O(\mathtt{w})\) time per operation. The space used by a BinaryTrie that stores \(\mathtt{n}\) values is \(O(\mathtt{n}\cdot\mathtt{w})\).