
3.7: Non-regular Languages
- Page ID
- 9629
The fact that our models for mechanical language-recognition accept exactly the same languages as those generated by our mechanical language generation system would seem to be a very positive indication that in “regular” we have in fact managed to isolate whatever characteristic it is that makes a language “mechanical”. Unfortunately, there are languages that we intuitively think of as being mechanically-recognizable (and which we could write C++ programs to recognize) that are not in fact regular.
How does one prove that a language is not regular? We could try proving that there is no DFA or NFA that accepts it, or no regular expression that generates it, but this kind of argument is generally rather difficult to make. It is hard to rule out all possible automata and all possible regular expressions. Instead, we will look at a property that all regular languages have; proving that a given language does not have this property then becomes a way of proving that that language is not regular.
Consider the language \(L=\left\{w \in\{a, b\}^{*} | n_{a}(w)=2 \bmod 3, n_{b}(w)=\right.\) 2 \(\bmod 3 \} .\) Below is a DFA that accepts this language, with states numbered 1 through 9.
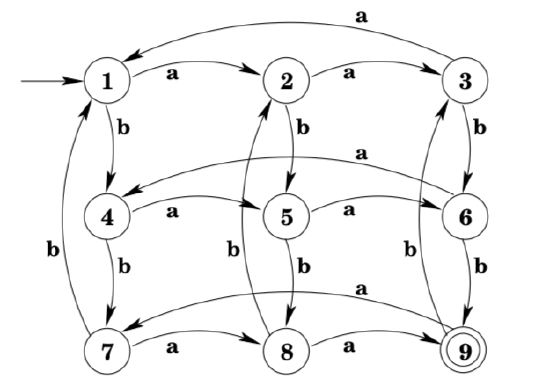
Consider the sequence of states that the machine passes through while processing the string abbbabb. Note that there is a repeated state (state 2). We say that abbbabb “goes through the state 2 twice”, meaning that in the course of the string being processed, the machine is in state 2 twice (at least). Call the section of the string that takes you around the loop y, the preceding section x, and the rest z. Then xz is accepted, xyyz is accepted,xyyyz is accepted, etc. Note that the string aabb cannot be divided this way, because it does not go through the same state twice. Which stringscan be divided this way? Any string that goes through the same state twice. This may include some relatively short strings and must include any string with length greater than or equal to 9, because there are only 9 states in the machine, and so repetition must occur after 9 input symbols at the latest.
More generally, consider an arbitrary DFA M, and let the number of states in M be n. Then any string w that is accepted by M and has n or more symbols must go through the same state twice, and can therefore be broken up into three pieces x,y,z (where y contains at least one symbol) so that w = xyz and
xz is accepted by M
xyz is accepted by M (after all, we started with w in L(M))
xyyz is accepted by M
etc.
Note that you can actually say even more: within the first n characters
of w you must already get a repeated state, so you can always find an x, y, zas described above where, in addition, the xy portion of w (the portion of w that takes you to and back to a repeated state) contains at most n symbols.
So altogether, if M is an n-state DFA that accepts L, and w is a string in L whose length is at least n, then w can be broken down into three pieces x, y, and z, w = xyz, such that
(i) x and y together contain no more than n symbols; (ii) y contains at least one symbol;
(iii) xz is accepted by M
(xyz is accepted by M)xyyz is accepted by Metc.
The usually-stated form of this result is the Pumping Lemma:
Theorem 3.6.
If L is a regular language, then there is some number n > 0such that any string w in L whose length is greater than or equal to n can be broken down into three pieces x, y, and z, w = xyz, such that
(i) x and y together contain no more than n symbols; (ii) y contains at least one symbol;
(iii) xz is accepted by M
(xyz is accepted by M)
xyyz is accepted by M
etc.
Though the Pumping Lemma says something about regular languages, it is not used to prove that languages are regular. It says “if a language is regular, then certain things happen”, not “if certain things happen, thenyou can conclude that the language is regular.” However, the Pumping Lemma is useful for proving that languages are not regular, since the con- trapositive of “if a language is regular then certain things happen” is “if certain things don’t happen then you can conclude that the language is not regular.” So what are the “certain things”? Basically, the P.L. says that if a language is regular, there is some “threshold” length for strings, and every string that goes over that threshold can be broken down in a certain way. Therefore, if we can show that “there is some threshold length for strings such that every string that goes over that threshold can be broken down in a certain way” is a false assertion about a language, we can conclude that the language is not regular. How do you show that there is no threshold length? Saying a number is a threshold length for a language means that every string in the language that is at least that long can be broken down in the ways described. So to show that a number is not a threshold value, we have to show that there is some string in the language that is at least that long that cannot be broken down in the appropriate way.
Theorem 3.7.
\(\left\{a^{n} b^{n} | n \geq 0\right\}\) is not regular.
Proof. We do this by showing that there is no threshold value for the language. Let N be an arbitrary candidate for threshold value. We want to show that it is not in fact a threshold value, so we want to find a string in the language whose length is at least N and which can’t be broken down in the way described by the Pumping Lemma. What string should we try to prove unbreakable? We can’t pick strings like \(a^{100} b^{100}\) because we’re working with an arbitrary N i.e. making no assumptions about N’s value; picking \(a^{100} b^{100}\) is implicitly assuming that \(N\) is no bigger than \(200-\) for larger values of N, \(a^{100} b^{100}\) would not be "a string whose length is at least N”. Whatever string we pick, we have to be sure that its length is at least N , no matter what number N is. So we pick, for instance, \(w=a^{N} b^{N}\). This string is in the language, and its length is at least N, no matter what num- ber N is. If we can show that this string can’t be broken down as described by the Pumping Lemma, then we’ll have shown that N doesn’t work as a threshold value, and since N was an arbitrary number, we will have shown that there is no threshold value for L and hence L is not regular. So let’s show that \(w=a^{N} b^{N}\) can't be broken down appropriately.
We need to show that you can't write \(w=a^{N} b^{N}\) as \(w=x y z\) where x and y together contain at most N symbols, y isn’t empty, and all the strings xz, xyyz, xyyyz, etc. are still in L, i.e. of the form \(a^{n} b^{n}\) for some number n. The best way to do this is to show that any choice for y (with xbeing whatever precedes it and z being whatever follows) that satisfies the first two requirements fails to satisfy the third. So what are our possible choices for y? Well, since x and y together can contain at most N symbols, and w starts with N a’s, both x and y must be made up entirely of a’s; since y can’t be empty, it must contain at least one a and (from (i)) no more than N a’s. So the possible choices for y are \(y=a^{k}\) for some \(1 \leq k \leq N\). We want to show now that none of these choices will satisfy the third requirement by showing that for any value of k, at least one of the stringsxz, xyyz, xyyyz, etc will not be in L. No matter what value we try for k, we don’t have to look far for our rogue string: the string xz, which is \(a^{N} b^{N}\) with k a’s deleted from it, looks like \(a^{N-k} b^{N}\), which is clearly not of the form \(a^{n} b^{n}\). So the only y’s that satisfy (i) and (ii) don’t satisfy (iii); so wcan’t be broken down as required; so N is not a threshold value for L; and since N was an arbitrary number, there is no threshold value for L; so L is not regular.
The fact that languages like \(\left\{a^{n} b^{n} | n \geq 0\right\}\) and \(\left\{a^{p} | p \text { is prime }\right\}\) are not regular is a severe blow to any idea that regular expressions or finite- state automata capture the language-generation or language-recognition capabilities of a computer: They are both languages that we could easily write programs to recognize. It is not clear how the expressive power of regular expressions could be increased, nor how one might modify the FSA model to obtain a more powerful one. However, in the next chapter you will be introduced to the concept of a grammar as a tool for generating languages. The simplest grammars still only produce regular languages, but you will see that more complicated grammars have the power to generate languages far beyond the realm of the regular.
Exercises
1. Use the Pumping Lemma to show that the following languages over {a, b} are not regular.
a) L1 = {x | \(n_{a}(x)=n_{b}(x)\)}
b)L2 ={xx|\(x \in\{a, b\}^{*}\)}
c)L3 ={\(x x^{R}\) |\(x \in\{a, b\}^{*}\)}
d) L4 = {\(a^{n} b^{m}\) | n < m}