For a length-\(N\) sequence, the time index takes on the values \(n=0,1,2,...,N-1\).
When the length of the DFT is not prime, \(N\) can be factored as \(N=N_{1}N_{2}\) and two new independent variables can be defined over the ranges \(n_{1}=0,1,2,...,N_{1}-1\) and \(n_{2}=0,1,2,...,N_{2}-1\).
A linear change of variables is defined which maps \(n_1\) and \(n_2\) to \(n\) and is expressed by
\[n=((K_{1}n_{1}+K_{2}n_{2}))_{N} \nonumber \]
where \(K_i\) are integers and the notation \(((x))_N\) denotes the integer residue of \(x\) modulo \(N\). This map defines a relation between all possible combinations ofn1n1" role="presentation" style="position:relative;" tabindex="0"> \(n_1\) and \(n_2\) as shown in the equations below. The question as to whether all of the n are represented, i.e., whether the map is one-to-one (unique), has been answered in showing that certain integer \(K_i\) always exist such that the map in the equation below is one-to-one. Two cases must be considered.
Case 1
\(N_1\) and \(N_2\) are relatively prime, i.e., the greatest common divisor \((N_{1},N_{2})=1\)
The integer map of the equation is one-to-one if and only if:
\[(K_{1}=aN_{2})\; \; and/or\; \; (K_{2}=bN_{1})\; \; and\; \; (K_{1},N_{1})=(K_{2},N_{2})=1 \nonumber \]
where \(a\) and \(b\) are integers.
Case 2
\(N_1\) and \(N_2\) are not relatively prime, i.e., \((N_{1},N_{2})>1\)
The integer map of the above equation is one-to-one if and only if:
\[(K_{1}=aN_{2})\; \; and\; \; (K_{2}\neq bN_{1})\; \; and\; \; (a,N_{1})=(K_{2},N_{2})=1 \nonumber \]
or
\[(K_{1}\neq aN_{2})\; \; and\; \; (K_{2}=bN_{1})\; \; and\; \; (K_{1},N_{1})=(b,N_{2})=1 \nonumber \]
Two classes of index maps are defined from these conditions.
Type-One Index Map
The map of the above equation is called a type-one map when when integers a and b exist such that
\[K_{1}=aN_{2}\; \; and\; \; K_{2}=bN_{1}, \nonumber \]
Type-Two Index Map
The map of the above equation is called a type-two map when when integers a and b exist such that
\[K_{1}=aN_{2}\; \; or\; \; K_{2}=bN_{1},\; \; but\; not\; both. \nonumber \]
The type-one can be used only if the factors of \(N\) are relatively prime, but the type-two can be used whether they are relatively prime or not. Good, Thomas and Winograd all used the type-one map in their DFT algorithms. Cooley and Tukey used the type-two in their algorithms, both for a fixed radix (\(N=R^M\)) and a mixed radix.
The frequency index is defined by a map similar to the equation as
\[k=((K_{3}k_{1}+K_{4}k_{2}))_{N} \nonumber \]
where the same conditions are used for determining the uniqueness of this map in terms of the integers \(K_3\) and \(K_4\)K3K3" role="presentation" style="position:relative;" tabindex="0">.
Two-dimensional arrays for the input data and its DFT are defined using these index maps to give
\[\widehat{x}(n_{1},n_{2})=x((K_{1}n_{1}+K_{2}n_{2}))_{N} \nonumber \]
\[\widehat{X}(k_{1},k_{2})=X((K_{3}k_{1}+K_{4}k_{2}))_{N} \nonumber \]
In some of the following equations, the residue reduction notation will be omitted for clarity. These changes of variables applied to the definition of the DFT given in the equation in section 2.1 give:
\[C(k)=\sum_{n_{2}=0}^{N_{2}-1}\sum_{n_{1}=0}^{N_{1}-1}x(n)W_{N}^{K_{1}K_{3}n_{1}k_{1}}W_{N}^{K_{1}K_{4}n_{1}k_{2}}W_{N}^{K_{2}K_{3}n_{2}k_{1}}W_{N}^{K_{2}K_{4}n_{2}k_{2}} \nonumber \]
where all of the exponents are evaluated modulo \(N\)NN" role="presentation" style="position:relative;" tabindex="0">.
The amount of arithmetic required to calculate the above equation is the same as in the direct calculation of that equation. However, because of the special nature of the DFT, the integer constants \(K_i\) can be chosen in such a way that the calculations are “uncoupled" and the arithmetic is reduced. The requirements for this are
\[((K_{1}K_{4}))_{N}=0\; \; and/or\; \; ((K_{2}K_{3}))_{N}=0 \nonumber \]
When this condition and those for uniqueness in the equation are applied, it is found that the \(K_i\) may always be chosen such that one of the terms in the equation is zero. If the \(N_i\) are relatively prime, it is always possible to make both terms zero. If the \(N_i\) are not relatively prime, only one of the terms can be set to zero. When they are relatively prime, there is a choice, it is possible to either set one or both to zero. This in turn causes one or both of the center two \(W\) terms in the equation to become unity.
An example of the Cooley-Tukey radix-4 FFT for a length-16 DFT uses the type-two map with
\[K_{1}=4, K_{2}=1, K_{3}=1, K_{4}=4 \nonumber \]
giving
\[n=4n_{1}+n_{2} \nonumber \]
\[k=k_{1}+4k_{2} \nonumber \]
The residue reduction in the equation is not needed here since n does not exceed \(N\) as \(n_1\) and \(n_2\) take on their values. Since, in this example, the factors of \(N\) have a common factor, only one of the conditions in the equation can hold and, therefore, the equation becomes
\[\widehat{C}(k_{1},k_{2})=C(k)=\sum_{n_{2}=0}^{3}\sum_{n_{1}=0}^{3}x(n)W_{4}^{n_{1}k_{1}}W_{16}^{n_{2}k_{1}}W_{4}^{n_{2}k_{2}} \nonumber \]
Note the definition of WN in the equation allows the simple form of
W16K1K3=W4W16K1K3=W4" role="presentation" style="position:relative;" tabindex="0">\[W_{16}^{K_{1}K_{3}}=W_{4} \nonumber \]
This has the form of a two-dimensional DFT with an extra term \(W_{16}\), called a “twiddle factor". The inner sum over \(n_1\) represents four length-4 DFTs, the \(W_{16}\) term represents 16 complex multiplications, and the outer sum over \(n_2\) represents another four length-4 DFTs. This choice of the \(K_i\) “uncouples" the calculations since the first sum over \(n_1\) for \(n_2=0\) calculates the DFT of the first row of the data array \(\widehat{x}(n_{1},n_{2})\) and those data values are never needed in the succeeding row calculations. The row calculations are independent, and examination of the outer sum shows that the column calculations are likewise independent. This is illustrated in Fig. 2.2.1 below.
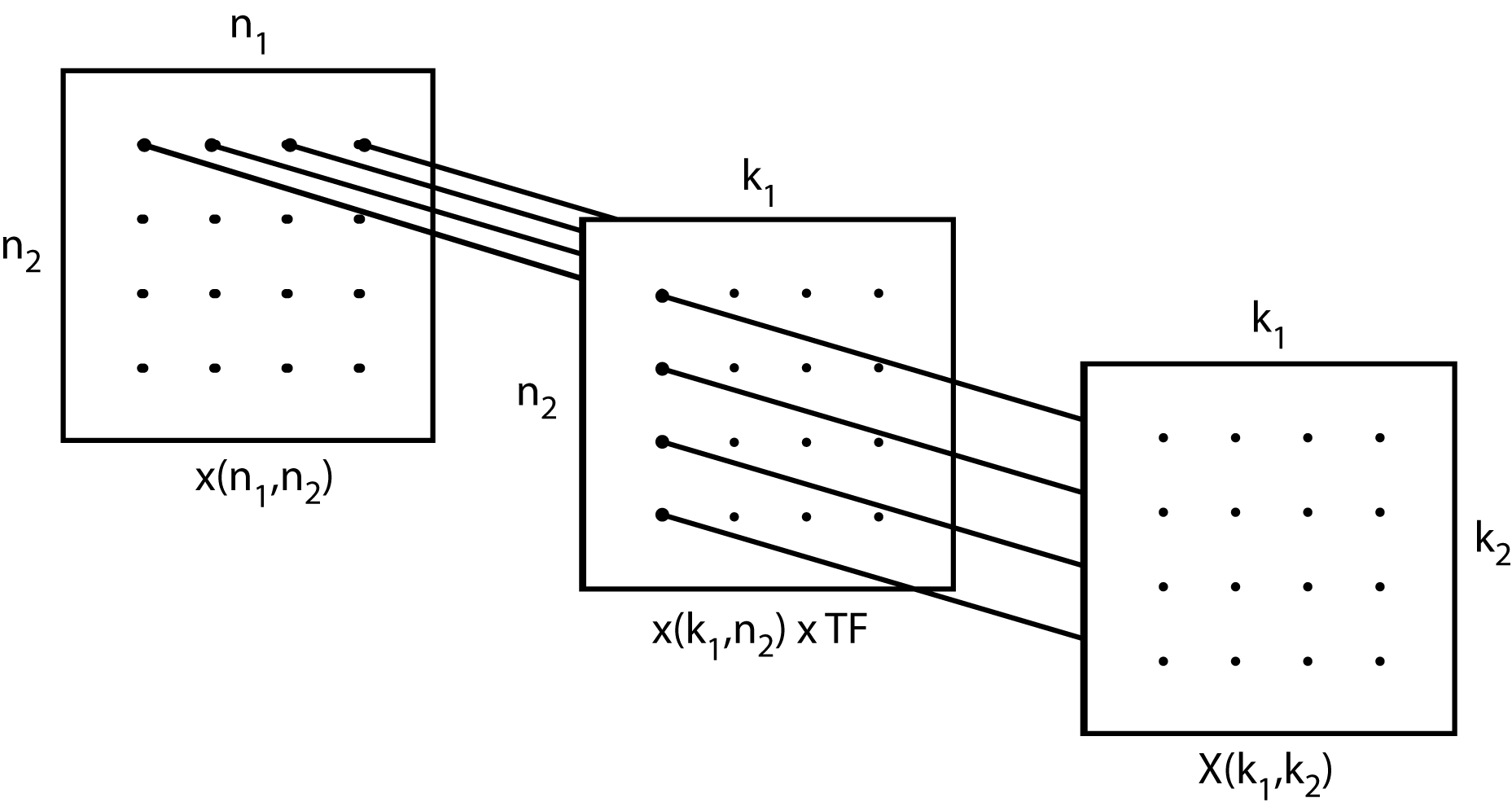
Fig. 2.2.1 Uncoupling of the Row and Column Calculations (Rectangles are Data Arrays)
The left 4-by-4 array is the mapped input data, the center array has the rows transformed, and the right array is the DFT array. The row DFTs and the column DFTs are independent of each other. The twiddle factors (TF) which are the center W in the equation, are the multiplications which take place on the center array of Fig. 2.2.1.
This uncoupling feature reduces the amount of arithmetic required and allows the results of each row DFT to be written back over the input data locations, since that input row will not be needed again. This is called “in-place" calculation and it results in a large memory requirement savings.
An example of the type-two map used when the factors of \(N\) are relatively prime is given for \(N=15\) as
\[n=5n_{1}+n_{2} \nonumber \]
\[k=k_{1}+3k_{2} \nonumber \]
The residue reduction is again not explicitly needed. Although the factors 3 and 5 are relatively prime, use of the type-two map sets only one of the terms in Equation to zero. The DFT in the equation becomes
\[X=\sum_{n_{2}=0}^{4}\sum_{n_{1}=0}^{2}xW_{3}^{n_{1}k_{1}}W_{15}^{n_{2}k_{1}}W_{5}^{n_{2}k_{2}} \nonumber \]
which has the same form as the equation, including the existence of the twiddle factors (TF). Here the inner sum is five length-3 DFTs, one for each value of \(k_1\). This is illustrated in the equation where the rectangles are the 5 by 3 data arrays and the system is called a " role="presentation" style="position:relative;" tabindex="0"> mixed radix" FFT.
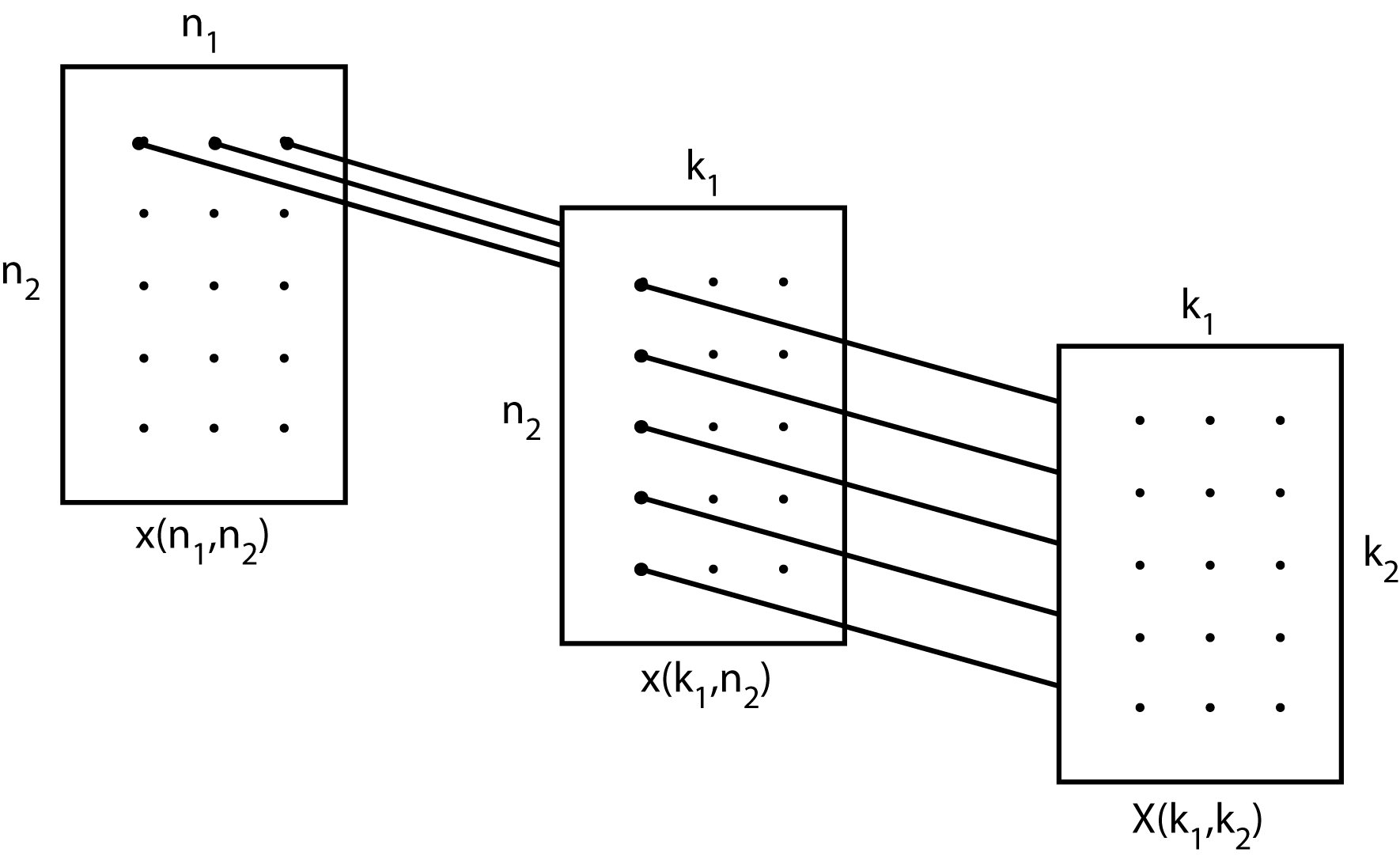
Fig. 2.2.2 Uncoupling of the Row and Column Calculations (Rectangles are Data Arrays)
The type-one map is illustrated next on the same length-15 example. This time the situation of the equation with the “and" condition is used in the equation using an index map of
\[n=5n_{1}+3n_{2} \nonumber \]
and
\[k=10k_{1}+6k_{2} \nonumber \]
The residue reduction is now necessary. Since the factors of \(N\) are relatively prime and the type-one map is being used, both terms in the equation are zero, and the equation becomes
\[\widehat{X}=\sum_{n_{2}=0}^{4}\sum_{n_{1}=0}^{2}\widehat{x}W_{3}^{n_{1}k_{1}}W_{5}^{n_{2}k_{2}} \nonumber \]
which is similar to the equation, except that now the type-one map gives a pure two-dimensional DFT calculation with no TFs, and the sums can be done in either order. the above figures also describe this case but now there are no Twiddle Factor multiplications in the center and the resulting system is called a " role="presentation" style="position:relative;" tabindex="0"> prime factor algorithm" (PFA).
The purpose of index mapping is to improve the arithmetic efficiency. For example a direct calculation of a length-16 DFT requires 162 or 256 real multiplications (recall, one complex multiplication requires 4 real multiplications and 2 real additions) and an uncoupled version requires 144. A direct calculation of a length-15 DFT requires 225 multiplications but with a type-two map only 135 and with a type-one map, 120. Recall one complex multiplication requires four real multiplications and two real additions.
Algorithms of practical interest use short DFT's that require fewer than \(N^2\) multiplications. For example, length-4 DFTs require no multiplications and, therefore, for the length-16 DFT, only the TFs must be calculated. That calculation uses 16 multiplications, many fewer than the 256 or 144 required for the direct or uncoupled calculation.
The concept of using an index map can also be applied to convolution to convert a length
\[N=N_{1}N_{2} \nonumber \]
one-dimensional cyclic convolution into a N1 by N2 two-dimensional cyclic convolution. There is no savings of arithmetic from the mapping alone as there is with the DFT, but savings can be obtained by using special short algorithms along each dimension. This is discussed in Algorithms for Data with Restrictions.

