
1: Web Development
- Page ID
- 45731

Learning Objectives
By the end of this section, you should be able to demonstrate:
- A basic understanding of the development of the Internet
- Awareness of current trends in web development
- An understanding of the components of a server
- Awareness of networking basics
- The ability to plan and design basic websites
- An awareness of different methods and approaches to development
- An understanding of types of tools that can assist development
Chapter 1
Brief History of the Internet
As far back as the early stirrings of the Cold War, the concept of a network connecting computers was under development by both government and university researchers looking for a better means to communicate and share research. The military at the time relied in part on microwave transmission technology for communications. An unexpected attack on some of these towers demonstrated how susceptible the technology was to failure of even small portions of the transmission path. This led the military to seek a method of communicating that could withstand attack. At the same time, university researchers were trying to share their work between campuses, and were struggling with similar problems when their transmissions suffered drops in signal. Parties from both groups ended up at the same conference with presentations, and decided to collaborate in order to further their work.
At the time, computers were far from what we know them as today. A single computer was a large, immobile assortment of equipment that took up an entire room. Data entry was done by using punched cards of paper, or the newest method of the time, magnetic tapes. Interacting with the computer meant reserving time on the equipment and traveling to where it was. Most machines were owned by universities, large corporations, or government organizations due to the staffing demands, size, and cost to acquire and maintain them. The image below depicts the UNIVAC 1, a system used by the United States Census Bureau and other large organizations like universities. One of the fastest machines at the time, it could perform roughly 1000 calculations per second.
 US Army, Public Domain, via Wikimedia
US Army, Public Domain, via Wikimedia
Figure 1 UNIVAC Computer System
In comparison, the K computer, a super computer produced in 2012 by the Japanese company Fujitsu, was capable of 10 petaflops per second when it was launched. Before you reach for your dictionary or calculator, we will break that down. FLOPS stands for floating point operations per second, or in basic terms, the number of calculations the system can finish in one second. A petaflop is a numerical indicator of how many 1015 (10 with 15 zeroes after it) calculations are completed per second. So, 10 petaflops means the K computer can complete 1015 calculations ten times in one second. If we fed the UNIVAC 1 just a single petaflop of data the day it was turned on, it would still be working on the problem today. In fact, it would barely be getting started, just a mere 60+ years into a roughly 317,098-year task!
ADDITIONAL NOTES
You may have heard of Moore’s Law, commonly defined as the tendency of technology’s capability to double every two years. Moore’s actual prediction was that this would apply to transistors, an element of circuits, and that it would continue for ten years after seeing its trend from 1958 to 1964. His prediction has shown to be applicable to memory capacity, speed, storage space as well as other factors and is commonly used as a bench mark for future growth.
As cold war tensions grew and Sputnik was launched, the United States Department of Defense (DoD) began to seek additional methods of transmitting information to supplement existing methods. They sought something that was decentralized, allowing better resiliency in case of attack, where damage at one point would not necessarily disrupt communication. Their network, Arpanet, connected the DoD and participating universities together for the first time. In order to standardize the way networked systems communicated, the Transfer Control Protocol/Internetwork Protocol (TCP/IP) was created. As various network systems migrated to this standard, they could then communicate with any network using the protocol. The Internet was born.
Email was soon to follow, as users of the networks were interested in the timely transmission and notification of messages. This form of messaging fit one of their initial goals. As time progressed, additional protocols were developed to address particular tasks, like FTP for file transfers and UDP for time-sensitive, error-resistant tasks.
Ongoing improvements in our ability to move more information, and move it faster, between systems progressed at a rate similar to the calculative power of the computers we saw earlier. This brings us to where we are today; able to watch full-length movies, streamed in high quality right to our phones and computers, even while riding in a car.
LEARN MORE
Keywords, search terms: History of the Internet, Arpanet
A Brief History of NSF and the Internet: http://www.nsf.gov/od/lpa/news/03/fsnsf_internet.htm
How the Internet Came to Be: http://www.netvalley.com/archives/mirrors/cerf-how-inet.html
Chapter 2
Current Trends
As important as it is to know how we reached where we are today, it is also important to stay current in web development. New products and innovations can greatly affect the landscape in a short amount of time. We can look to the rapid rise in Facebook, Twitter, and the myriad of Google services now relied upon around the world as examples of how fast new technology is embraced.
Cloud Computing
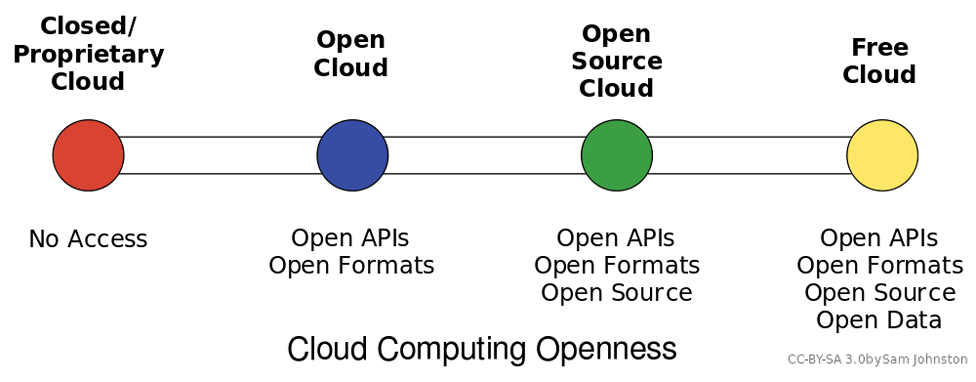 Figure 2 Cloud Computing Styles
Figure 2 Cloud Computing Styles
Cloud computing can be loosely defined as the allocation of hardware and/or software under a service model (resources are assigned and consumed as needed). Typically, what we hear today referred to as cloud computing is the concept of business-to-business commerce revolving around “Company A” selling or renting their services to “Company B” over the Internet. A cloud can be public (hosted on a public internet, shared among consumers) or private (cloud concepts of provisioning and storage are applied to servers within a fire wall or internal network that is privately managed), and can also fall into some smaller subsets in between, as depicted in the graphic above.
Under Infrastructure as a Service (IaaS) computing model, which is what is most commonly associated with the term cloud computing, one or more servers with significant amounts of processing power, capacity, and memory, are configured through hardware and/or software methods to act as though they are multiple smaller systems that add up to their capacity. This is referred to as virtualizing, or virtual servers. These systems can be “right sized” where they only consume the resources they need on average, meaning many systems needing little resources can reside on one piece of hardware. When processing demands of one system expand or contract, resources from that server can be added or removed to account for the change. This is an alternative to multiple physical servers, where each would need the ability to serve not only the average but expected peak needs of system resources.
Software as a Service, Platform as a Service, and the ever-expanding list of “as-a-service” models follow the same basic pattern of balancing time and effort. Platforms as a service allow central control of end user profiles, and software as a service allows simplified (and/or automated) updating of programs and configurations. Storage as a service can replace the need to manually process backups and file server maintenance. Effectively, each “as-a-service” strives to provide the end user with an “as-good-if-not-better” alternative to managing a system themselves, all while trying to keep the cost of their services less than a self-managed solution.
Additional Notes
One of the best methods to keep current is by following trade magazines, industry leader blogs, and simply browsing the internet looking for new items or site features you have not noticed before. Content aggregators like Zite, Feedly, and Slashdot are some of my favorites.
As a micro-scale example, imagine you and four friends are all starting small businesses. Faced with the costs of buying servers and software for data storage, web hosting, and office programs, each of you would invest funds into equipment and the staff to maintain it, even though much of it may get little use in the early stages of your company. This high initial investment reduces available funding that may have been used elsewhere, and your return on investment becomes longer. Instead, each of you would create an account with Amazon’s cloud services for file storage and website hosting, which are private to you, but physically stored on servers shared by other users. Since these services are managed offsite by Amazon staff, none of you need to hire IT staff to manage these servers, nor do you have to invest in the equipment itself. Just by not needing to hire a system administrator (estimated at $40,000 salary) you can pay for just over 3 years of Amazon service (calculated using Amazon’s pricing calculator1 for basic web services and file storage). When you combine the savings of that employee’s fringe costs like health care, along with those of not purchasing your own hardware, this approach can make your initial investment last longer.
These lowered costs are attractive to small businesses and startups for obvious reasons, but are also attractive to large companies with highly fluctuating levels of need. For example, a football team’s website sees far more traffic on game days than the off-season. They do not need the ability to serve the same amount of users all the time. Some tangible examples of “as-a-service” tools you may already be using are file hosting services like Dropbox2 or Google Drive.3 Your files are kept on servers along with those from other users that you do not see (unless you share with them intentionally) and you can add or remove extra space to your account whenever you like. Similarly, services like Amazon Web Services4 offer the ability to host your files, applications, and more to both home consumers and commercial clients.
Virtualization
Server virtualization is the act of running multiple operating systems and other software on the same physical hardware at the same time, as we discussed in Cloud Computing. A hardware and/or software element is responsible for managing the physical system resources at a layer in between each of the operating systems and the hardware itself. Doing so allows the consolidation of physical equipment into fewer devices, and is most beneficial when the servers sharing the hardware are unlikely to demand resources at the same time, or when the hardware is powerful enough to serve all of the installations simultaneously.
The act of virtualizing is not just for use in cloud environments, but can be used to decrease the “server sprawl,” or overabundance of physical servers, that can occur when physical hardware is installed on a one-to-one (or few-to-one) scale to applications and sites being served. Special hardware and/or software is used to create a new layer in between the physical resources of your computer and the operating system(s) running on it. This layer manages what each system sees as being the hardware available to it, and manages allocation of resources and the settings for all virtualized systems. Hardware virtualization, or the stand alone approach, sets limits for each operating system and allows them to operate independent of one another. Since hardware virtualization does not require a separate operating system to manage the virtualized system(s), it has the potential to operate faster and consume fewer resources than software virtualization. Software virtualization, or the host-guest approach, requires the virtualizing software to run on an operating system already in use, allowing simpler management to occur from the initial operating system and virtualizing program, but can be more demanding on system resources even when the primary operating system is not being used.
Ultimately, you can think of virtualization like juggling. In this analogy, your hands are the servers, and the balls you juggle are your operating systems. The traditional approach of hosting one application on one server is like holding one ball in each hand. If your hands are both “busy” holding a ball, you cannot interact with anything else without putting a ball down. If you juggle them, however, you can “hold” three or more balls at the same time. Each time your hand touches a ball is akin to a virtualized system needing resources, and having those resources allocated by the virtualization layer (the juggler) assigning resources (a hand), and then reallocating for the next system that needs them.
 By Daniel Hirschbach [CC-BY-SA-2.0 Germany] via Wikimedia
By Daniel Hirschbach [CC-BY-SA-2.0 Germany] via Wikimedia
Figure 3 Virtualization Styles
The addition of a virtual machine as shown above allows the hardware or software to see the virtual machine as part of the regular system. The monitor itself divides the resources allocated to it into subsets that act as their own computers.
Net Neutrality
This topic is commonly misconstrued as a desire for all Internet content to be free of cost and without restrictions based on its nature. In fact, net neutrality is better defined as efforts to ensure that all content (regardless of form or topic) and the means to access it, are protected as equal. This means Internet Service Providers (ISPs) like your cable or telephone company cannot determine priority of one site over another, resulting in a “premium” Internet experience for those able to pay extra. Additional concerns are that without a universal agreement, a government may elect to restrict access to materials by its citizens (see North Korea censorship5), and similarly that corporations controlling the physical connections would be able to extort higher prices for privileged access or pay providers to deny equal access to their competitors.
Useful Features
Legislation continues to change regarding what is and is not legal or acceptable content on the internet. Laws change over time as well as across jurisdictions and can greatly differ. Just because material is legal in your area does not mean it is in others and you may still be in violation of laws applicable in the location of your server.
Existing laws vary around the world, some protecting the providers, some protecting the user. The United States received considerable attention in 2012 for anti-piracy bills that were highly protested both with physical rallies and online petitions. Each bill drew debate over what affects the stipulations would have not only within the United States, but over the Internet as a whole. Even though SOPA6 (introduced by the House) and PIPA7 (introduced by the Senate after the failure of COICA8 in 2010) were not ultimately ratified, The United States and other countries had at that point already signed ACTA9 in 2011, which contained provisions that placed the burden on ISPs to police their users regardless of sovereign laws in the user’s location.
Learn more
Keywords, search terms: Cloud computing, virtualization,
virtual machines (VMs), software virtualization, hardware virtualization
Xen and the Art of Virtualization: http://li8-68.members.linode.com/~caker/xen/2003-xensosp.pdf
Virtualization News and Community: http://www.virtualization.net
Cloud Computing Risk Assessment: http://www.enisa.europa.eu/activities/risk-management/files/deliverables/cloud-computing-risk-assessment
Without formal legislation, judges and juries are placed in positions where they establish precedence by ruling on these issues, while having little guidance from existing law. As recently as March 2012 a file sharing case from 2007 reached the Supreme Court, where the defendant was challenging the constitutionality of a $222,000 USD fine for illegally sharing 24 songs on file sharing service Kazaa. This was the first case for such a lawsuit heard by a jury in the United States. Similar trials have varied in penalties up to $1.92 million US dollars, highlighting a lack of understanding of how to monetize damages. The Supreme Court denied hearing the Kazaa case, which means the existing verdict will stand for now. Many judges are now dismissing similar cases that are being brought by groups like the Recording Industry Association of America (RIAA10), as these actions are more often being seen as the prosecution using the courts as a means to generate revenue and not recover significant, demonstrable damages.
As these cases continue to move through courts and legislation continues to develop at the federal level, those decisions will have an impact on what actions are considered within the constructs of the law, and may have an effect on the contents or location of your site.
Cyber Warfare
Intentional, unauthorized intrusion of systems has existed about as long as computers have. While organized, coordinated attacks are not new, carrying them out in response to geopolitical issues is now emerging, as was found in the brief 2008 war between Russia and Georgia. Whether the attacks on each country’s infrastructures were government sanctioned or not is contested, but largely irrelevant. What is relevant is that these attacks will only continue, and likely worsen, in future disputes.
In the United States and other countries, equipment that controls aging infrastructure for utilities is increasingly connected, with control computers at facilities for electric, water, gas, and more being placed online to better facilitate monitoring and maintenance. However, many of these systems were not developed with this level of connectivity in mind, therefore security weaknesses inherent in the older equipment can result in exploits that allow Hackers to cause real, permanent damage to physical equipment, potentially disrupting the utilities we rely on every day.
Tehran’s uranium enrichment development facilities were targeted in late 2010 by a custom-created virus that focused on equipment used in the refining of nuclear material. The virus would randomly raise or lower the speed of the equipment in a manner that would not create alarms, but enough to strain the equipment. This would lead to equipment failures, after which the replacement hardware would be similarly infected. Eventually discovered, the virus had been running for many months, delaying the project and increasing its costs. This virus was intentionally designed to run in that particular environment and was based on the specific SCADA hardware involved, and in this case was such a sophisticated attack that it is widely believed to have been facilitated by the United States and Israel.
 Figure 4 10 Years of Known Cyber Attacks
Figure 4 10 Years of Known Cyber Attacks
The graph above, from foreignaffairs.com, provides an idea of how prevalent government to government attacks are becoming. We should keep in mind that the ninety-five incidents depicted are only the known, reported incidents, and the true number is likely higher.
Botnets
Botnets are not exactly a new threat to the Internet, but they remain one of the most persistent threats to the average user and their computer. The word botnet, an amalgamation of the words robot and network, is an accurate description of what it entails. Botnets are programs that use a network connection to communicate with each other to coordinate and perform tasks. Originally, botnets were created as part of programs for Internet Relay Chat (IRC) to help establish and control channels people would log into to talk to each other. They are still in frequent use today for a number of legitimate, non-malicious tasks.
We have also seen a rise in malicious botnets, designed to work undetected in the background of your computer. The controller (typically referred to as the command and control server) uses the infected machines to complete tasks that require large amounts of processing power and/or bandwidth to complete, like finding or exploiting weaknesses in networks or websites, or to “mine” infected systems for personal data such as credentials, credit card numbers, and other information that can then be used or sold to others.
Additional Notes
It did not take long for the first virus to enter the internet. Just two years after the first systems were connected, The Creeper (a self-replicating script) was created in 1971, which did no harm but displayed “I’m the creeper, catch me if you can” on infected machines. It was immediately followed by The Reaper, the first anti-virus program, which too self-replicated, removing the Creeper wherever it was found.
Some botnet controllers have grown so large and organized that they act as businesses in competition, typically “renting” their botnet out as a service or tool to others for agreed upon rates. Efforts by security researchers to detect and analyze botnets often involve close coordination with government agencies and law enforcement as the size of an average botnet typically involves computers from multiple countries. Simply shutting down or attempting to remove the malicious files from infected systems could cause unintended damage to the machines, further complicating the process of eliminating a botnet.
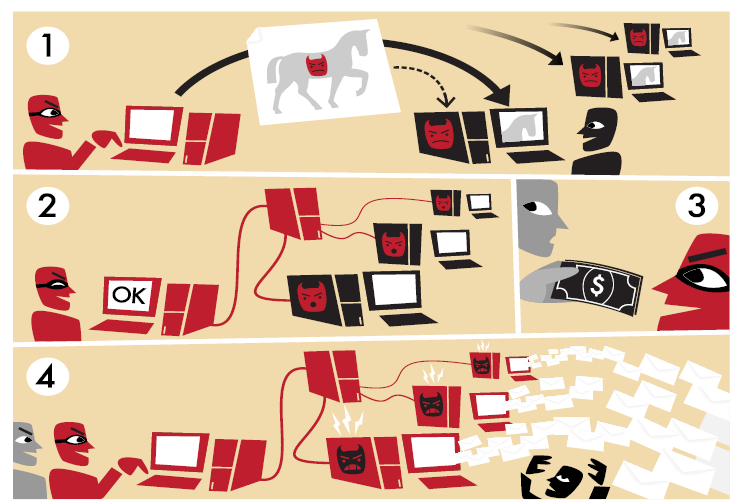 By Tom-B [CC-BY-SA-3.0], via Wikimedia
By Tom-B [CC-BY-SA-3.0], via Wikimedia
Figure 5 Botnets
Learn more
Keywords, search terms: Botnets, command and control system, malware, network security
Build Your Own Botnet: http://howto.wired.com/wiki/Build_your_own_botnet_with_open_source_software
Honeynet Project: http://www.honeynet.org/papers/bots/
Internet of Things
In much the same vein of the connection of older equipment to the networks of the modern world, the newest devices emerging into the market can also be a bit more non-traditional. This results in an internet that is soon to be awash with live connections from everything from cars to ovens and refrigerators, an explosion of devices no longer focused on delivering information to the masses as much as aggregating many data sources of interest to a small set of recipients. Some cars now include the ability for consumer service companies to perform tasks like remotely shutting down your car if stolen; coordinating use of these tools with law enforcement allows them to stop a vehicle before or during a pursuit. While these are innovative tools with positive uses, they also add new vectors for a malicious person to attack. Instead of the thief being thwarted, he might use a device to shut your car down at an intersection, eliminating your ability to simply drive away when he approaches. The very tool intended to stop him afforded him a means to gain access to your vehicle. This is not merely waxing philosophically, either. It has been demonstrated as a proof of concept11
backed by researchers funded by DARPA.
As more devices are introduced to the Internet, the amount of interaction with things as simple as small appliances is increasing. Comments like “We have to stop by the store on the way home, the toaster report said we will need at least one loaf of bread for the week” seem silly to us now, but could eventually exist in the same breath as “The fridge called, it ordered our groceries for the week.” For about $2,700 USD, Samsung already offers a fridge with interactive features similar to these ideas.
Items embedded with RFID tags contribute to the Internet of Things, as they can be tracked and provide information that can be aggregated and applied to processes. Shipping crates with RFID expedite taking inventory as their tags can be scanned automatically in transit. Access cards not only allow privileged access to restricted areas but also let us know where people (or, at least their cards) are located and where they have been. Home automation systems allow lights, locks, cameras, and alarms to be managed by your smart phone to the extent that your lights can come on, doors unlocked, and garage door opened, when it detects that your phone has entered the driveway. All of these are items—not people—interacting with the Internet to fulfill a task, and are part of the emerging Internet of Things.
Proliferation of Devices
As reliance on the Internet and the drive for constant connection proliferate through our societies, and technology becomes more affordable and adaptable, we have not only left the age of one computer per home, but meandered even past the point where everyone in the house has their own device, and now the average consumer has multiple devices. The proliferation allows us to adjust technology to fit where we need it in our lives. I use my desktop for hardware intensive applications at home, or for doing research and web development where multiple monitors eases my need to view several sources at once. Out of the house, my tablet allows me to consume information and is easily slid into a keyboard attachment that allows it to operate as a laptop, turning it into a content creation device by reducing the difficulty of interacting by adding back a keyboard and mouse.
Improvements in software both in efficiency and ease of use allow older hardware to get second lives. My laptop, though ten years old, is still running happily (albeit without a useful battery life) and is still capable of browsing the internet and being used as a word processor due to a lightweight Linux operating system that leaves enough of its aging resources available for me to complete these tasks. When the average lifespan of a laptop is typically considered to be only three years, many older devices like mine have not left operation, and are still finding regular use in our growing set of tech tools.
Chapter 3
Web Servers
While we could simply focus on how to create web pages and websites, none of this is possible without the underlying hardware and software components that support the pages we create. Examining what these components are and how they interact helps us understand what our server is capable of.
The diagram below represents the basic elements of a web server. Hardware, an operating system, and an http server comprise the bare necessities. The addition of a database and scripting language extend a server’s capabilities and are utilized in most servers as well.
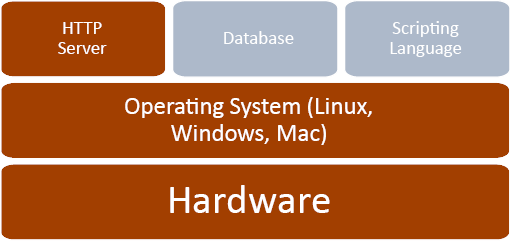 Figure 6 Web Server Software Structure
Figure 6 Web Server Software Structure
Hardware
The mention of phrases like data center, hosting provider, or even big name companies like Microsoft and Google can invoke mental images of large, sterile rooms full of tall racks of hardware with blinking lights and a maze of wires. Those more familiar with such rooms will also know the chill resulting from the heavily air conditioned atmosphere and droning whir of fans that typically accompany them. This, however, is not a requirement nor an accurate portrayal of a great deal of servers connected to the Internet. With the addition of the right software (assuming you are consuming this text digitally), the device you are using to read this with could become an internet connected server. While it would not sustain the demands made of domains like Amazon.com or MSN.com, you would be able to perform the basic actions of a server with most of today’s devices.
Even though we have reached this point, it is difficult to forget the mental picture conjured by the thoughts of the data center. In the current “traditional” model, thin, physically compact servers are stacked vertically. These are referred to as rack mount hardware. Many rack mount systems today contain hardware similar to what we have in our desktops, despite the difference in appearance.
A number of companies, including Google, Yahoo, and Facebook, are looking to reinvent this concept. Google for instance has already used custom-built servers in parts of its network in an effort to improve efficiency and reduce costs. One implementation they have tried proved so efficient that they were able to eliminate large power backup units by placing a 9 volt battery in each server—giving it enough emergency power to keep running until the building’s backup power source could kick in. They have also experimented with alternative cooling methods like using water from retention ponds, or placing datacenters where they can take advantage of natural resources like sea water for cooling or wind and solar for energy.
Additional Notes
Take note! While all of the programs we refer to in our LAMP stack have free, open source versions, not all uses may be covered by those licenses (using them for study and research purposes is covered).
Even small, low powered devices are finding demand as servers in part to enable the Internet of Things. Devices like the Raspberry Pi12 and an explosion of similar products like “android sticks” can be purchased for as little as $25 USD. These small, “just-enough-power” devices are used to connect data from the environment or other devices to the Internet, leaving the data center behind and living instead at the source of the data itself.
Software
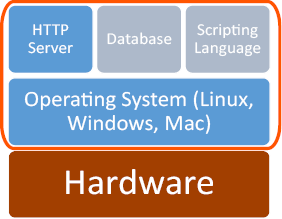
A typical web server today contains four elements in addition to the physical hardware. These are the operating system, web server, a database and a scripting language. One of the most popular combinations of these systems has been abbreviated to LAMP, standing for Linux, Apache, MySQL, and PHP, named in the same order. There are many combinations of solutions that meet these features, resulting in a number of variations of the acronym, such as WAMP for Windows, Apache, MySQL, PHP or MAMP, identical with exception of Mac (or, rightfully, a Macintosh developed operating system). Among the plethora of combinations, the use of LAMP prevails as the catch all reference to a server with these types of services.
All that is ultimately required to convey static pages to an end user are the operating system and HTTP server, the first half of the WAMP acronym. The balance adds the capability for interactivity and for the information to change based on the result of user interactions.
Operating System—Linux
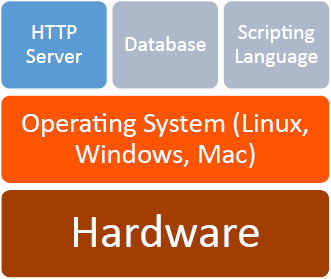
Your operating system is what allows you to interact with the applications and hardware that make up your computer. It facilitates resource allocation to your applications, and communication between hardware and software. Typically, operating systems for servers fall under three categories: Linux based, Windows based, and Mac based. Within each of these categories are more options, such as various version of Mac and Windows operating systems, and the wide variety of Linux operating systems. We will utilize Linux, the predominant choice.
Developed by Linus Torvalds in the early 1990s while he was a student, Linux was created so Linus could access UNIX systems at his university without relying on an operating system. As his project became more robust, he decided to share it with others, seeking input but believing it would remain a more personal endeavor. What he could not have predicted was the community that would come together and participate in helping shape it into what is today. As the basis of a large number of Linux-based operating systems (or “flavors” of Linux), the Linux core can be found around the world, even in the server rooms of its competitors like Microsoft.
HTTP Server—Apache
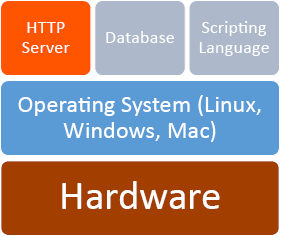
Apache is an open source web server originally developed for UNIX systems. Now supported on most platforms including UNIX, Linux, Windows, and Mac, Apache is one of the most utilized server applications. First developed in 1995, Apache follows a similar open source approach as Linux, allowing users to expand on the software and contribute to the community of users. The user group around Apache developed The Apache Foundation, which maintains a library of solutions for web services.
In a web server, Apache serves as the HTTP component, which compiles the results from scripting languages, databases, and HTML files to generate content that is sent to the user. Apache (or any web service) will track which files on the server do and do not belong to the website, and also controls what options are available to the end user through its configuration files.
Apache and other HTTP servers allow us to share our webpages, scripts, and files with our end users. Any output from our database and scripting languages is turned into HTML output that the client’s browser displays as our webpage. While we can view HTML and JavaScript files on a computer that is not a webserver, we need an http server to view them as a destination on a network.
Configuration Files
When we create a new system, settings may not be exactly as we want them, or the time may come where we want to add, remove, or change something about our server. To do this, we will need to edit the configuration files that control the different pieces of our system. Our actual web server config file is called httpd.conf. For PHP settings, we need to refer to php.ini, and for MySQL we refer to my.cnf. These files may be located in different places depending on the operating system, and the version in use, so it is best to use your system’s file search tools to find where they are on your machine. Configuration (or setting) files are typically a plain text format file with one setting on each line with comments near each value describing the setting’s use. These files will also use the same commenting delimiter for their notes to enable or disable individual settings. Typically the delimiter used is a semi colon ; or pound sign #.
If you want to change settings about your server itself such as the port it listens on, what folder it looks for files in, its name, or other related features, look to the httpd.conf file. From the php.in file you can control elements like which modules are installed and enabled for your system, how much data scripts are allowed to consume, and more. Similarly your MySQL config file determines what port it listens on, which user it runs as on your server, what your admin account’s credentials are, and more.
Changes to these files typically require you to restart your web server (in our case, for apache or PHP changes), or at least the service that you are changing (in our case, MySQL changes). This can be done using the control panel if you are using a combination program like Wamp 2, or by using your operating system’s service tools or by using system commands at a command prompt. Restarting Wamp 2 in a GUI operating system like Windows can be done be right clicking on Wamp’s icon in the tray. In a Cent OS server, the same effect can be achieved by typing “service httpd restart.” If all else fails, you can always physically restart the machine (referred to as “bouncing”), but this is something you will want to avoid on a live system as it will cause a much longer period of down time.
If you use installer packages, or a combo installer like Wamp 2, you will probably get by initially without making any changes to these files. Binary installers however will not know where or how to make changes to config files and you will need to follow the instructions to edit these files by hand to integrate all of your elements.
Why would I use a combination other than Linux, Apache, My SQL, and PHP?
Given the popularity of this particular combination of four, it is easy to wonder why it has not simply become the system. However, needs and preferences may change why a particular approach is selected. Perhaps you are in an all Windows environment and feel more comfortable with a Windows operating system. Maybe your data is already available in a flat file or XML format and you want a database that can use XML files, like MongoDB.13 Or, you might prefer the approach and packages available in Python to those found in PHP. Each system has its particular strengths and weaknesses, and should be chosen based on the needs of the project.
Open Source
At this point, you have come across many references to terms like free, free to edit, and open source throughout the text. In fact, all of the elements in our example LAMP are free, open source solutions. Open source means the provider of the software allows the end user access to the actual code of their software, allowing the end user to make changes anywhere in the program.
This differs from traditional software where you own a copy or license to use the program, but cannot extend or change elements of the program beyond what the developer allows. An executable in Windows for example is closed source. You cannot open the executable to read its code or make changes. If you wanted to change the program, the developer would have to provide you with the files used to create it (called source code) so you could make changes and compile your own, modified, executable program.
Open source is growing in popularity but the concept has existed for quite some time. Recently, larger governments have begun to embrace free, open source solutions as a means to reduce costs and achieve modifications that customize programs to fit their needs. Historically open source was viewed as a security risk as anyone could submit changes to the project, and it was feared that vulnerabilities or malicious code would be inserted. In fact, with so many users able to view and modify the files, it has actually made those with malicious intent less able to hide their modifications (sometimes called the “many eyes” approach to reliability). Development time has also been reduced as the community of developers on a popular open source project can greatly exceed that of a closed source solution with limited development staff.
A popular acronym referring to these projects is FOSS—Free, Open Source Software. As not all open source programs are free in terms of purchasing or licensing, FOSS indicates solutions that are free of costs as well as free to change. These solutions may be developed entirely by a community of volunteers, or may come from a commercial company with developers dedicated to the project. While it is odd to think of a company giving away its creation for free, these companies generate revenue by building advertising into their software or offering premium services such as product support or contracting with clients to customize the product. Many companies will also offer only some tools as open source alongside other products they sell, or offer a “freemium” model where the open sourced platform contains most of the features of their software. Here, additional features or add-ons beyond the open source package carry additional licensing and costs.
FTP
While not included in LAMP acronyms, another important element to note is the existence of a file transfer protocol (FTP) server. As you typically will want to perform development activities on private server before editing your live server, you will need a mechanism that allows you to move files between the two. FTP is designed for moving files between systems, allowing you to synchronize items when you are ready. In addition to an FTP server, you will also likely want an FTP client application for the machine(s) that contain the files you want to move. The client allows you to see files in both locations and interact with them to determine which file is moved to which machine. There are a number of free file transfer programs available, some of which can even be integrated into browsers like Chrome by using browser extensions.
Chapter 4
Network Basics
IP Addresses
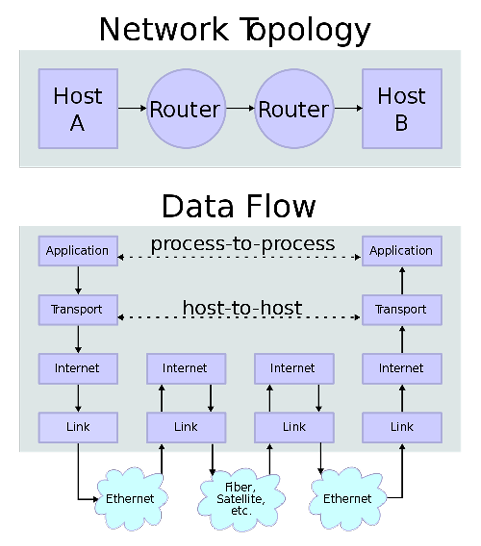
Figure 7 Network Topology
An IP (Internet Protocol) address is a unique code that identifies a piece of equipment connected to a network. These addresses are used in messages between network devices like the network or wireless card in your computer, the equipment from your ISP (internet service provider), and all pieces of equipment between your machine and the one your computer needs to talk to.
IP Addresses live in the network layer, which is one of seven layers in the protocol suite defined in the OSI Model. The OSI model stands for Open Systems Interconnection, and was created by the International Organization for Standardization, an international non-governmental group of professionals who strive to establish standards and best practices in a variety of fields. The OSI Model for networking breaks the system of transmitting data into the layers show below in an attempt to delineate where certain actions should take place.
 By MrsValdry [CC-By-SA 3.0] via Wikimedia
By MrsValdry [CC-By-SA 3.0] via Wikimedia
Figure 8 OSI 7 Layer Model
The seven layers depicted above make up the OSI body’s recommended protocol suite. In the diagram, transmission of data crosses two routers and over the Internet to reach its destination. By following the data along the arrows, we see it pass through various layers of communication and processing as it crosses the internal network, through the first router, across the public network (internet connection), into the recipient’s router, and then is reassembled into its original form.
Until recently, most network equipment has operated on IPv4, the fourth standard released for IP addresses, which has been in place for about thirty years. Addresses in this format are typically represented as a pattern of four blocks of up to three digits separated by periods, with no block of numbers exceeding 255 such as 127.0.0.1 or 24.38.1.251. This is referred to as dot-decimal representation, and although it is not the only way to express an IPv4 address it is the most recognized form. Segments of the addresses within the ranges of 192.168.xxx.xxx, 172.16.xxx.xxx to 172.31.xxx.xxx, and 10.0.xxx.xxx to 10.255.xxx.xxx are reserved for private networks, meaning they are used within a network in your house, at work, or anywhere else where a group of computers share a connection to the internet.
Each of these networks uses one or more of these blocks of numbers for devices on that network. Only the equipment connecting that local network to the Internet needs a unique address from the rest of the world. That equipment will track which computer inside the network to send data to and from by reading packets—the individual pieces of messages that are sent across networks. This means your computer might be 192.168.1.25 at home, and so might your computer at work, according to your home and work networks. The connection between your house and office thought still have a different, unique number assigned to them.
This separation of networks was done to reduce the speed at which unique addresses were consumed. Although this scheme allows for almost 4.3 billion (accurately, 232) addresses, the last one was officially assigned on February 4th, 2012. To sustain today’s growing number of devices, IPv6 was created, which is depicted as eight blocks of four hexadecimal digits now separated by colons. These new addresses might look like 2001:0db8:85a3:0042:1000:8a2e:0370:7334, and can support roughly 4 billion unique addresses. Since the new range is so staggeringly large, additional protocols were created that specify when certain values or ranges are used in addresses. This allows additional information about the device to be conveyed just from the address.
The actual messages sent between machines are broken down into multiple pieces. These pieces, called packets, are sent piece by piece from sender to recipient. Each packet is sent the fastest way possible, which means some packets may take different routes—picture a short cut, or getting off a congested road to take a different one. This helps to ensure that the message gets from sender to receiver as fast as possible, but also means packets may arrive in a different order than they were sent.
Additional Notes
Hexadecimal is a number scheme that allows 0 through 9 and A through F as unique values, which means we can count to 15 with one character.
To account for this, each piece of the message, or payload, is wrapped in a header—additional information that describes how many other pieces there are, what protocol is being used, where the packet came from and is headed to, along with some other related information.
 By Nicolargo [ CC-BY-SA-3.0-2.5-2.0-1.0] via Wikimedia Commons
By Nicolargo [ CC-BY-SA-3.0-2.5-2.0-1.0] via Wikimedia Commons
Figure 9 IP 4 Packet
After the packets are reassembled, the receiving computer sends any necessary responses, and the process repeats. This all takes place in fractions of a second, beginning with the “hello,” or handshake packet to announce a communication request, to the last piece of the packet.
URL
Seeing as most of us would have a hard time remembering what IP address is needed to get to, say, Facebook (173.252.100.16) or the Weather Channel (96.8.80.132) we instead use URLs, universal resource locators. This allows us to use www.facebook.com and www.weather.com to get to where we want to go without referring to a long list of IP addresses. Specialized servers (called name servers) all around the world are responsible for responding to requests from computers for this information. When you type facebook.com into your address bar, if your router does not have a note of its own as to where that is, it will “ask” a name server, which will look it up in its records and reply.
There are three parts to a network address: the protocol, name, and resource id. The protocol represents how we want to send and receive messages, for example we can use http:// for accessing websites and ftp:// for moving files. The name is what we associate with the site, like www.facebook.com, and the resource id, or URI, is everything after that, which points to the particular file we want to see.
Ports
While an IP address and a URL will bring you to a particular web server, there may be more than one way you want to interact with it, or more than one thing you want it to do. Maybe you also want the server to provide email services, or you want to use FTP to update your files. These ports act as different doors into your server, so different applications can communicate without getting in each other’s way. Certain ports are typically used for certain activities, for example port 80 is the standard port for web traffic (your browser viewing a page), as opposed to ftp, which typically uses port 21. Using standard ports is not a rule, as applications can be configured to use any available port number, but it is recommended in most cases as firewalls and other security devices may require additional configuring to keep them from blocking wanted traffic because it is arriving at an unusual, fire walled, or “locked” port.
Hosting Facilities
If you are using a server that is not under your physical care, and is managed by an off-site third party, then you likely have an agreement with a hosting facility. Hosting facilities are typically for-profit companies that manage the physical equipment necessary to provide access to websites for a number of clients. Many offer web development and management services as well, but if you are still reading, then that tidbit is probably of little interest as you are here to build it yourself.
Additional Notes
Up Time is the average amount of time that all services on a server are operational and accessible to end users. It is a typical measurement of a hosting company’s ability to provide the services they promise.
The benefit of using a hosting service falls under the same principles as other cloud computing services. You are paying to rent equipment and/or services in place of investing in equipment and managing the server and Internet connection yourself. Additionally, hosting facilities are equipped with backup power sources as well as redundant connections to the internet, and may even have multiple facilities that are physically dispersed, ensuring their clients have the best up time as possible. Ads like the one below are common to these services and often emphasize their best features. Price competition makes for relatively affordable hosting for those who are not looking for dedicated servers and are comfortable with sharing their (virtual) server resources with other customers.

Domain Registrar
Domain registrars coordinate the name servers that turn URLs into the IP addresses that get us to our destinations. These companies are where you register available names in order to allow others to find your site. One of the most recognized registrars right now is GoDaddy—you may know them from their ads, which feature racecar driver Danica Patrick. Like many registrars, GoDaddy also offers other services like web and email hosting as well as web development in an effort to solve all of your website needs.
Learn more
Keywords, search terms: Networking, network topology, OSI, network architecture
Cisco Networking Example: http://docwiki.cisco.com/wiki/Internetworking_Basics
List and description of all top level domains: http://www.icann.org/en/resources/registries/tlds
Ongoing comparison of hosting providers: http://www.findmyhosting.com/
Chapter 5
Website Design
Website design is a topic of study often neglected until after a programming background has been developed. Worse, it may be entirely ignored or missed by computer science students when courses covering the topic are in other programs like graphic arts or media. This results in programmers trying to understand how to write code meant for layout and design elements without understanding design. By studying these elements first, we can develop a better knowledge of the concepts of web design before we write code. Progressing through the topics in this section during your site design will greatly ease your development efforts in the future, allowing stakeholders to understand the project and provide feedback early on, reducing (re)development time.
A number of factors affect design in web development, complicating what would otherwise appear to the end user to be a relatively simple process of displaying a picture or document. In truth, the development process involves not only the HTML and multimedia that make up the visual aspects of the page but also considerations of software engineering, human-computer interaction, quality assurance and testing, project management, information and requirement engineering, modeling, and system analysis and design.
Today’s sites are now becoming more application centered than traditional sites. This further complicates our projects as we integrate with legacy software and databases, strive to meet real-time data demands, address security vulnerabilities inherent to the environment we are working in, and ongoing support and maintenance typical of robust software applications.
In response to these advances in complexity and capability, web development has grown to embrace many of the same development processes of software development. We will consider some of these processes below, which you may wish to use depending on the size and complexity of a given project.
Planning Cycle
Web development is best achieved as a linear process, but is usually completed asynchronously. The planning process described is intended to build upon itself to refine project requirements, look and feel, and development plans. However, limitations in timelines, mid-project revisions, and the extensive time that can be invested into the early stages of design lead many programmers to begin development while a project is still in design.
Starting early with programming during design planning can accelerate a project when the elements created early on are unlikely to be affected by later changes in the scope. When done carefully, early programming also allows an opportunity to test concepts before investing time into an idea that may not work. It is important to avoid aspects that are assumed to change, like visual layout or particular pieces of content, instead focusing on data structure, frameworks, and other components that are easily adapted to design changes.
While you are planning, keep an eye out for indicators that things are going off-track. Some of the more important flags that should be resolved include:
- Vaguely defined use cases and inadequate project requirements
- Overly broad or undefined scope of features
- Unresolved disputes between stakeholders about project features
- Unrealistic time table, budget, or inadequate resources
When considering your milestones, tasks, objectives, or whatever label you or your team place on objectives, a handy acronym to reference is SMART. SMART stands for Specific, Measurable, Attainable, Realistic, and Timely. The idea is to check all of your objectives against these criteria to determine if they are appropriate and well developed. By ensuring all of your objectives meet the SMART criteria, you will have a better chance of keeping your project on time and well planned.
Specific:
Is your objective specific enough to convey its full scope? While you do not want to specify implementation of the objective, you should convey enough specific information that the person assigned to the objective can begin their portion of implementation.
Good Example: Deliver our standard proposal with adjusted price quotes to reflect customer’s discount rate of 15%.
Bad Example: Deliver a proposal to the customer.
Measurable:
Your objective should have a clear indicator of when it is complete.
Good Example: Complete the first 15 pages identified in the site plan.
Bad Example: Complete the first 20% of the site.
Attainable:
Is it possible, at all, to complete the objective?
Good Example: Get the server to a FedEx store by close of business on delivery date.
Bad Example: Drive the server from New York to California within 24 hours.
Realistic:
Is it possible to complete the objective given the timeline and resources on hand?
Good Example: Have Team A (staff of 20) complete 10 pages by tomorrow.
Bad Example: Have Bob the Intern complete 10 pages by tomorrow.
Timely:
Will the objective be useful if it is completed at (not near or before) its deadline?
Assuming a proposal deadline of Friday morning:
Good Example: Have draft sitemap completed by the end of Wednesday to include in the proposal.
Bad Example: Have draft sitemap completed by the end of Friday to include in the proposal.
“But, wait, Attainable and Realistic sound like the same thing!” Well, yes they are quite similar. However the difference lies in what else you know about the project, timeline, resources and objectives. In our Realistic example this is highlighted by specifying the resources available for the objective. While our example company could assign sufficient resources to complete 10 pages in a day, it could never drive a server from New York to California in a day no matter how many people it has or how fast their car is given current speed limits. In the same vein, the objective of creating 10 pages in a day is perfectly attainable for our example company, but is not realistic if your company lacks enough manpower to complete the task.
While we broke these examples down to highlight the particulars of each element of our litmus test, real world objectives would contain all of these together in up to two or three brief sentences:
Team A will complete the customer’s proposal using our standard forms including their discount and a sample site plan by the 15th for delivery the 20th.
Now we need to test it. Is the objective specific? Yes. We are not left needing basic questions asked before we could work on the objective. Is it Measurable? Yes. We have a deadline of the 15th of the month for a specific list of items. Is it Attainable? Yes. With appropriate resources there is nothing impossible about the objective. Is it Realistic? Assuming Team A has enough time and manpower to complete the task by the deadline, yes. Is it Timely? The work is due 5 days before delivery, allowing time for review, changes, or delays, and its deadline does not extend beyond its useful life, so yes, we have a SMART objective.
How do we come up with our objectives? We extract them as the “big things” that need to be done from the customer’s request, the mission statement, or other sources of information that define the scope of your project.
What do we do with our objectives? The individual(s) tasked to the objective will break it into actionable tasks, or individual items that need to be completed. For example, our hypothetical objective of ten pages in a day could be broken down into ten tasks, one for each page. Helpful Hint: SMART can be applied to tasks, too (really any future planning/goal).
Why bother with any of this? Why even create a scope document in the first place if we know things will change? Well, we do it because things will change. New ideas will crop up, problems might be found, or something might be forgotten in the mix. The planning stage will define for us and our client exactly what we are going to do, and what our price, time, terms, etc. are meant to cover. As a project is in progress, especially if iterative meetings are held with the client, new requests will come into play. These may be great ideas. They may be terrible. They may derail the project’s success if they are not completed. However, each of them will affect your timeline and resources. The tendency to squeeze in “one more idea” over and over again is called Feature Creep, as it creeps into your project and eventually eats away at your resources and profit.
Learn more
Keywords, search terms: Website planning, web development plan, planning templates, project management
Good Planning Worksheet: http://www.goodworkmarketing.com/docs/WebsitePlanningGuide.pdf
BusinessBalls.com Guide to Project Management: http://www.businessballs.com/project.htm
The Fold
As we begin to develop our pages, we need to begin to consider where we want to place pieces of our content. If you look at newspapers, you will find that the most attractive story of the day (as decided, at least, by the publisher) is emblazoned in large letters near the middle or top of the front page, surrounded by the name of the paper, the date, and other pieces of information that quickly lend to your decision of whether or not to purchase a given paper. This is done intentionally, to make the paper attract your attention and get you to buy their edition over their competitors. In the printed news industry, the prime retail space in the paper is the top half of the front page, or what you see when the newspaper is folded normally at a newsstand. This is referred to as “above the fold,” and is crucial to getting their audience’s attention. This also applies to websites, except in our case, our “above the fold” is what the user sees on the landing page for our site, without having to scroll down or use any links.
What you typically find here is the name and or logo of the company, and what they feel is most important for you to see first. As you begin to analyze web pages in this light, you will find it very easy to determine what kind of site they are, or what they want or expect from you as their guest. News sites will typically follow a similar setting to a printed paper, leading with headlines and links to other sections. Companies will lead with a featured product or sale to attract your attention, and search engines will make the search bar prominent, usually with ad space close by to increase their revenue streams.
 The concept of “The Fold” is another of the many highly argued concepts in web development. Proponents are quick to point out the same example I used of traditional print media methods, while detractors will argue that if it were true, scrolling would never have been created, or users would lose interest in following links. While I endorse “The Fold” as a useful approach to landing pages, I do not mean to imply that all of your pages should fit on only one, non-scrolling screen.
The concept of “The Fold” is another of the many highly argued concepts in web development. Proponents are quick to point out the same example I used of traditional print media methods, while detractors will argue that if it were true, scrolling would never have been created, or users would lose interest in following links. While I endorse “The Fold” as a useful approach to landing pages, I do not mean to imply that all of your pages should fit on only one, non-scrolling screen.
Recent trends on sites like Facebook and LinkedIn show us there are in fact places for scrolling. Indefinitely, as it were. Both sites now feature status pages where older content is continuously appended each time you near the bottom of the page. This is quite similar to the concept of paging, but instead of clicking a link to the next page, the content is simply written in at the bottom creating a never-ending feel to the page. Ultimately, your design phase will help identify where following “The Fold“ is not really an option, or if there is enough content to warrant indefinite scrolling, and all other ranges in between.
Typography
Typography is the study of font. While an important topic in media arts, it has until recently received little attention in web development. Utilizing unusual fonts used to be a complicated process that required the end user to have your font(s) installed in order to see the site as you intended. Now, advances in CSS allow us to use unusual fonts by connecting to them through our styling. This allows us to use a tremendous variety of fonts in our sites to add to our look and feel, adding an aspect that has unlocked new approaches to design. Some of the elements of typography include the study of features like readability, conveying meaning or emotion through impression, and the artistic effect of mixing styles.
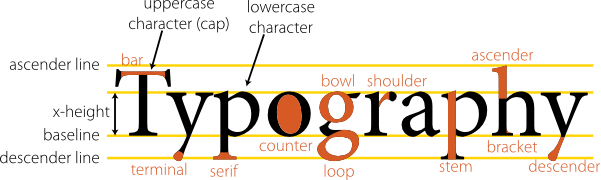 Public Domain—openclipart.org
Public Domain—openclipart.org
Figure 10 Typography
For ease of reading and to avoid a cluttered appearance, most sites keep to two or three fonts when creating their design. One for text, and one or two for headings, titles, and distinguishing marks. All of these should be kept in the same family for a more congruous experience, and each unusual font defined in your site should include fallback definitions in case there are problems loading your primary style (we will see this in examples later on). You may want to set your regular text as one of the standards supported by all browsers as users are most familiar and usually comfortable with that set.
Web Fonts
To tap into this aspect of design, a great place to start is with the Google Fonts14 website. This site is a repository of character sets for a great variety of fonts that you can link to or download and include in your own site’s files. We will look at connecting to these later, but browsing the site now will give you an initial look at the amount of variety that is available for design.
Site Maps
A site map is a file that contains a master list of links to the pages on your site, and can provide information about those pages like how often they are updated, how pages connect to each other, and how important it is relative to the other pages. It can be a reference tool to both Bots that index your site for search engines, as well as your visitors trying to find particular content. Site map files are XML documents arranged in hierarchical format that bots read to gain understanding of your site layout, page relevance, and organization. The file may also be a human readable page that diagrams how pages relate to one another, and serve as a master list of the pages in your site. Site maps are best kept in the root of your website, at the same level as your initial index page.
While a complete site map cannot be finalized until after your site is ready to be published, I include site maps under development methods because laying out your site’s organization on paper will help with developing your menu system, logically organizing content, and in defining the scope and purpose of your site. The more content or pages you can define at the beginning of the process will reveal information that will help during your design phase.
To create a site map, you can start by creating a running list of all the content you wish to have on your site. Anyone involved in the production or validation of content should be in room! In each of these steps, it is important to identify your stakeholders. As you are creating your running list, it is often helpful to use index cards so you can determine by card color or pile where a particular piece of content should be. This will help you discover your menu system, as you create names for piles of cards as your menu title. After, as you diagram what cards are with what pile and where that pile is relative to others, your site map will begin to take shape.
 Creative Commons 2.0 Licensed by Kent Bye
Creative Commons 2.0 Licensed by Kent Bye
Figure 11 Site Map
If you are rebuilding an existing site, you may wish to adapt the existing menu system or scrap it entirely and start new. Larger sites or those with a large number of stakeholders involved will need more time to complete this step. To break larger projects down, you may wish to begin by defining what type(s) of content you do not want on your site. For example, if your target audience is casual shoppers looking for in-home plants, you can eliminate information on plants not suited for indoor living, or restrict the amount of information provided to basic care and maintenance, as opposed to the greater detail professional landscapers will look for. Distributing the process of identifying what material needs to be published into several groups of stakeholders who share interests in certain categories will also help streamline this process.

Figure 12 Website Planning
The sitemap you create should follow the URL standards RFC-398615 (notably the use of entity escape codes) and the standards for XML.16 Your character encoding must also be in UTF-8, which means some special characters and markings beyond those traditionally used in text will not be available. Once your sitemap is complete and uploaded, you can add it to your robots.txt file as:
You can also submit your site (and sitemap) for crawling directly to the search engines. While this may not happen immediately, it lets them know that your site is new or has changed. Some engines, like Google17 provide tools and reporting for a comprehensive experience while others like Bing18 have quick entry forms that only require your site’s main URL and a confirmation that you are, in fact, human (which seems amusing when you consider the point of what you are doing is to trigger a bot).
Let us plan a small site of just a few links: our index page, a contact page, an information page, and publications and research pages off of our information page. As an XML file, our visual sitemap above would be expressed as the following:
- <?xml version="1.0" encoding="UTF-8"?>
- <urlset xmlns=http://www.sitemaps.org/schemas/sitemap/0.9>
- <url>
- <loc>http://www.oursite.com/</loc>
- <lastmod>2013-01-13</lastmod>
- <priority>0.8</priority>
- <url>
- <url>
- <loc>http://www.oursite.com/contact.htm</loc>
- <lastmod>2013-01-13</lastmod>
- <priority>0.9</priority>
- <url>
- <url>
- <loc>http://www.oursite.com/publications.htm</loc>
- <lastmod>2013-01-13</lastmod>
- <priority>0.5</priority>
- <changefreq>monthly</changefreq>
- <url>
- <url>
- <loc>http://www.oursite.com/information.htm</loc>
- <lastmod>2013-01-13</lastmod>
- <priority>0.5</priority>
- <url>
- <url>
- <loc>http://www.oursite.com/research.html</loc>
- <lastmod>2013-01-13</lastmod>
- <priority>0.7</priority>
- <url>
- </urlset>
As we are focusing on the sitemap aspects of this example at the moment (we will learn more about XML later), just take note that the <loc>, <url>, and <urlset> tags for location are required. Everything else is optional, but adds more information for site crawlers. You will also note that in this example you cannot deduce the menu or hierarchy that we saw in our visual diagram—indexing services do not care about this. For a site visitor, we would style this page differently or create a sitemap optimized for our visitors to read.
Robots.txt
Robots are automated scripts typically used to index, or take inventory, of the content in a website for use in things like web searching sites or collecting statistics. A robots file is a basic text file kept in the root folder of your website that instructs these robots on what sections or types of content in your site you do or do not want them to index. Legitimate robots will read this file when they first arrive on your site to honor your request. Keep in mind this is an enforceable act, and malicious or less-than-reputable robots are still perfectly capable of reading through all non-privileged (i.e. no login required) content on your site.
The simplest robots.txt file involves only two lines:
- User-agent: *
- Disallow: /
The first specifies that the rules below apply to all robots that read the file. The second adds that nothing is allowed below (meaning deeper, or all the files and folders inside of) the root folder ( / represents the main folder of the site). If we wanted to be more specific about what sections we want to keep bots out of, we can identify them individually instead of the whole site:
- User-agent: *
- Disallow: /pictures/reserved/
- Disallow: /index.php
- Disallow: /media
- Disallow: /scripts
To distinguish cases where a particular bot has a different set of permissions, we can use the bot’s name in place of our “all” wildcard:
- User-agent: BadBot
- Allow: /About/robot-policy.html
- Disallow: /
- User-agent: *
- Disallow: /pictures/reserved/
- Disallow: /index.php
- Disallow: /media
- Disallow: /scripts
The above settings tell BadBot that it is allowed to see the policy file, but nothing else. It still specifies the blocked paths for the rest of the bots that might visit.
Wireframes
Wireframes in the web development world are not exactly their literal three dimensional counterparts in the real world, but they bear a similar purpose. A wireframe may include things like location and size of elements such as a login button, where banners and content sections will sit, and provide an overall idea of how a site will operate. When wire framing a website, the idea is to create a mockup of one or more designs that portray how the interface might appear to the user. By the end of your wire framing process, you should have an idea of how the site will operate, and have resolved questions over where users will find particular features and elements.
Wireframes typically do not include color, actual content, or advanced design decisions like typography. Some of these considerations will have been at least partly addressed when creating your site map, and the rest will come once we begin storyboarding.

Figure 13 Wireframe
Storyboarding
Storyboarding a website is quite similar to storyboarding a TV show, comic, or other forms of media. Using our wireframes, we can begin to add color, font, and rough images to our documents. Keep in mind at this point we are probably still in a graphics editor or document style program like PowerPoint, Photoshop, etc. Real code is coming soon, but we can do more mock-ups faster without taking the time to make it function.
As you storyboard, you will create separate pages, or panels, for the screen a user would see as they complete the most important processes on your site. If you are selling something, for example, your storyboard may include examples of product pages, adding items to their cart, logging in, and completing their purchase.
By paging through these panels, you can see how the user experience will progress and identify potential problems like a confusing check out process, or you may discover that your shopping cart block from wire framing may be better off in a different, more predominant location. This process may be repeated several times until a final version is accepted by everyone in the decision process.
 Creative Commons 2.0 Rob Enslin
Creative Commons 2.0 Rob Enslin
Figure 14 Storyboarding
Color Schemes
The process of determining the color(s) involved in your site could fill a book. In fact, it does.19 Regardless of the varying opinions of what emotions colors instill, or represent, the quickest way to alienate a user is to give them a visual experience that is unappealing. The layout, appearance, and cohesiveness of your site are something that are immediately judged when a user first visits. These elements influence everything from their impression of what the site represents, its reputability, and even its trustworthiness as an ecommerce option. If your site appears to be disorganized, dated and out of style, or seems too “busy” or complicated, you canlose users in less than ten seconds.20
You can address this issue (even without an artistic eye) by following the techniques we discussed earlier to plan out a simple, intuitive interface, and by using tools to help you select and compare color schemes like http://colorschemedesigner.com/ or http://www.colorsontheweb.com/colorwizard.asp.
Whether you choose to study other books on the subject or not, a great way to keep current is to get ideas from what others are doing by following sites that list or rate sites by appearance such as the annual Times review21 and http://www.thebestdesigns.com/.
Learn more
Keywords, search terms: Web design, aesthetics, graphics, typography
Web Style Guide 3rd Edition: http://webstyleguide.com/wsg3/8-typography/index.html
TypeCulture: http://www.typeculture.com/academic_resource/
Chapter 6
Development
Below are just a few examples of different methods of programming found in the workplace. This is not an exhaustive list, but is meant to induce some personal analysis of what approaches might be effective for you. We will look at examples of styles based on the number of programmers—one, two, or many—to demonstrate how programming can be approached as team sizes change.
Staffing Styles
Single Developer
Also called The Lone Cowboy or Lone Wolf. Typically found in small companies, benefits of being a single developer are that you are intimately familiar with the entire code base (at least while you are writing it—we will get to that under Good Practices), do not have to agree on coding styles, branching, or integrating code, and your functions and classes are built to what you specify.
Downfalls however are also large. A second pair of eyes or fresh mind can help find bugs faster, the workload burden is entirely yours, and any security issues or bugs you are not aware of are likely to be found the hard way, by an end user or malicious visitor.
Paired Programming
Sometimes referred to as Holmes and Watson programming, paired programming is the practice of assigning two programmers to the same task, and having them (quite literally) work side by side. This allows one person to write while the other contemplates code interactions, watches for bugs, and keeps track of tasks. By altering which programmer in the pair is the lead at different intervals both programmers are able to contribute and learn from each other. Proponents of this model will highlight studies that show decreases in bugs, increased performance (it is, after all, harder to sneak in that Facebook post when co-workers are regularly using your screen), increased knowledge across staff members, and less distraction.
This approach may or may not work well depending on the culture present, and paying two staff members to complete one task can be more expensive, possibly offsetting reduced programming time. Poor pairing decisions (e.g., two programmers with little experience) and other factors like addressing sick time and vacations that interrupt teams can also reduce the potential benefits of this approach.
Team Development
Team development allows the work involved in a project to be dispersed among a group of individuals (a necessary step for most large scale projects) and reduces overall development time. A team with well-defined divisions of labor who adhere to an agreed upon set of methods can be a highly effective group.
Detractors are found where agreements on labor or method are ill defined or not adhered to. They can also arise from personal issues or conflicts of personality, and physically dispersed teams may find issues with time zone differences, limitations of communication methods, and increased “lag” time caused by not being face-to-face for immediate communication.
Project Management Methods
Once you move beyond programming alone and into groups, or have multiple parties working on the same project, a management approach will be needed to determine pace, goals, deadlines, and to maintain order and understanding of the project. There are a great deal of approaches to this problem, and we will take a quick look at some of the currently popular solutions.
Agile
While some of the principles of agile development go against the planning process we examined above, it can be effective in instances where fast turnaround is necessary and a highly iterative release process is acceptable. Some of its tenets are frequent communication between parties, self-organized groups motivated for the project, and requirements that are changed as ideas progress through the project. Changing requirements are driven by what is revealed through the iterative releases, and this fluidity is one of the strengths to be found in this approach.
Ultimately, the guiding principle here is to work in the mindset where you get the best people, trust in them, and focus more on the customer’s wishes and the project itself than length contracts, internal processes, and bureaucracy. You are most likely to run into this approach in start-ups that are not burned by an internal bureaucracy and heavily structured atmosphere.
The twelve principles of agile development, according to a published manifesto22 by seventeen software developers are as follows:
- Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
- Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage.
- Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
- Business people and developers must work together daily throughout the project.
- Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
- The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
- Working software is the primary measure of progress.
- Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
- Continuous attention to technical excellence and good design enhances agility.
- Simplicity—the art of maximizing the amount of work not done—is essential.
- The best architectures, requirements, and designs emerge from self-organizing teams.
- At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
Scrum
The Scrum process is a more focused and organized approach than agile development. The Scrum process maintains the defined roles of team members while pursuing the fast-paced development goals of agile. Daily meetings are held at the same time/place, and are typically held standing, to encourage shorter meetings. Core team members lead the 15-minute meeting by briefly reporting on what they did since the last meeting, their plans for the day, and any obstacles they have come across. Stumbling blocks brought up in these reports are addressed by the Scrum Masters, who address obstacles in order to keep the rest of the team on task.
Scrum goals are organize into Sprints, blocks of time usually shorter than 30 days, in which certain tasks of the project should be completed. Sprints are kicked off with planning meetings, and the goal is to have those portions of the project in full working order by the Sprint’s completion.
 By Lakeworks [CC-BY-SA-3.0-2.5-2.0-1.0], via Wikimedia Commons
By Lakeworks [CC-BY-SA-3.0-2.5-2.0-1.0], via Wikimedia Commons
Figure 15 Scrum
Waterfall
The Waterfall approach to project management recognizes the projects are typically cyclical, and builds that recognition into its five stage approach to management:
.svg) Paulsmith99 at en.Wikipedia CC-BY-3.0, via Wikimedia Commons
Paulsmith99 at en.Wikipedia CC-BY-3.0, via Wikimedia Commons
Figure 16 Waterfall Diagram
Requirements
Requirement gathering can be interactions with your users that generate feature requests, initial project definition like its scope, or discovery of other important information during the planning phase of a project.
Design
Development of pseudo-code, storyboards, wireframes, or any other materials necessary to depict what will be implemented to satisfy the requirements. See sections: Pseudo-Code First!, Storyboarding, and Wireframes.
Implementation
The actual programming and development phase to generate the working solution.
Verification
Testing and debugging the solution to ensure it meets the requirements and works as intended.
Maintenance
Ongoing tasks such as database maintenance, modifications to support changing requirements, or new tasks created by the discovery of bugs.
Items discovered in this phase trigger the process to begin again in order to address them. Eliminating a bug, for example, requires determining how to fix the problem, after which the bug resolution will move through the rest of the steps just like the project did initially. New ideas or feature requests will also trigger the requirements stage to begin. As these events will not occur at the same time, the waterfall effect occurs as individual items in the project will be in different phases as the cycle continues.
Structural Patterns
More decisions! Now that we have our team(s), and an approach for managing the project as a whole, we need to determine how to manage the development of the code as well. How the code is organized contributes to how easy or difficult change management becomes, how flexible the system is, and how portable it is. The options of how to approach organizing the actual code are called Architectural Patterns.
Model View Controller
In the MVC approach, we create three distinct concepts in our code. The image below depicts a de-coupled approach to MVC, where the model and view have no direct communication.
 Shane Brinkman-Davis, December 2012 CC-A 3.0
Shane Brinkman-Davis, December 2012 CC-A 3.0
Figure 17 Model View Controller
Models
Our models contain the logic, functions, and rules that manipulate our data. A model is the only piece of the system that should interact directly with your data source. It should also respond to a request with a consistently formatted reply, and not simply return messages from the data source. This allows you to utilize multiple different sources for your data, or easily change how it is stored, as you would only need to edit your model’s interactions and connections instead of adjusting code throughout your entire site.
Views
Views generate the output that is presented to the user. They request, or are given, the data needed to complete the page by the model. In some interpretations of MVC, the controller may also act as a mediator between the model and view—the important fact is that you should not see code in a view section that completes any actions other than formatting and presenting output. The view contains the images, tables, styling, and page formatting that make up the site itself. By keeping these items isolated from the models and controllers, we can easily duplicate our site’s appearance somewhere else, or “skin” several sites differently, but have them all use the same data and models for interaction.
Controllers
Controllers recognize changes and events, such as user interaction and results of model responses that drive other actions. The controller will then call the appropriate model(s) to interact with data, and the appropriate view(s) to reflect the changes made. When controllers also manage passing data from the model to the view, the system is considered passive, or de-coupled, as the models and views have no awareness of each other.
Variations
MVC was originally developed as a method for traditional software development. Migrating it to web development is not a simple task, as the concepts become muddled when interacting with multiple languages, and a client-server model of communication. Other approaches to interpreting the MVC method for web development such as model/view/presenter, model/view/adapter, and presentation/abstraction/control attempt to resolve and clarify implementing this approach online.
Service-Oriented Architecture
SOA is a modular style approach to interaction. It is used in web services and Cloud Computing (APIs) as a method of providing tools, actions, and information to other systems that allows for larger and/or multiple systems to integrate into. Each item in an SOA approach is oblivious to the actions of other services. It only knows how to request information or actions contained in other services as they are needed.
By building in this approach, the programmers can specify and limit what actions are available and under what conditions (end user’s authentication level, nature of data, etc.) all while keeping the actual systems removed from direct interaction with the consumer. This helps protect internal systems by limiting access to raw data and intellectual property while still providing an organized platform from which developers can retrieve what they need.
Larger companies might develop an API that provides information from multiple data sources from one place. By creating the common platform, their developers can connect to the data from other applications or websites without having to connect to each data source. These companies might also allow their partners to access their API in order to provide automate communication between companies, create other add-on tools, or to contribute their own information. Walgreens recently opened a portion of their internal API for just this reason. By allowing third parties access, outside vendors were able to create applications like printing from Instagram right at your local store, or refilling prescriptions from a mobile device.
Unit Testing
Unit testing is an exercise in writing each element of your software to meet very specific requirements. By reducing your project to its smallest testable component, each part can be tested individually. These modules are then connected together to form the larger whole. It is included under methods instead of practices as it is an important approach that needs to be followed by each team member if it is to be used at all. Testing these units before including them in the software should reduce debugging, and more readily allows for testing components before a full implementation has been assembled. This technique can also be combined with other methods because it is more of a coding practice than an approach to project implementation.
Unit testing is frequently used in fast paced approaches like Scrum to help ensure a less error prone product. Keep in mind that this is not a perfect solution. While individual units may test fine, logical problems can still be created as these modules are combined. Continued testing of the results of not only single units but also units working in combination will help in addressing this potential point of failure.
Learn more
Keywords, search terms: Project management, programming architecture, software planning and development
Architectural Blueprints—The “4+1” View Model of Software Architecture http://www.cs.ubc.ca/~gregor/teaching/papers/4+1view-architecture.pdf
Project Management Advisor http://www.pma.doit.wisc.edu/index.html
Good Practices
File Organization
As we begin to create more and more files to complete our website, keeping everything in one folder will quickly grow cluttered. To address this, we can create folders just like we do when sorting files in My Documents. Traditionally you can find folders for images, scripts, pages or files, or for different sections of content or tasks, like an admin folder or ecommerce store. How and why these folders are created varies to personal taste or group determinations, and in some cases is done to maintain a particular method of writing code such as model-view-controller.
Pseudo-Code First!
Whiteboards, notepads, and napkins are your friends. Writing out how you plan to tackle a particular problem will help you identify logic problems before you are halfway through coding them, and will help you keep track of what you need to work on as you progress. Creating pseudo-code is the process of writing out in loosely structured sentences what needs to be done. For example, if my task is to look at each element in an array and tell the user if it is true or false, we might draft the following:
- foreach(thing in array){
- if(thing / 2 is 0) then show Even
- else show Odd
- }
Imagine that while writing this example out we realize that we want to store the responses for use again later, not just show them to the user. So, let us update our pseudo-code to take that use case into mind:
- foreach(thing in array){
- if(thing / 2 is 0) then add to even array
- else add to odd array
- send arrays back in an array
- }
Reviewing what we have now, not much looks different, but so far we have not had to rewrite any code either. After some thought, it might occur to us that creating two additional arrays could be more memory intensive and less efficient than editing the one we already have. So, to simplify things and possibly improve performance, we might try this:
- foreach(thing in array){
- if(thing / 2 is 0) then add it to even array, delete from this array
- send arrays back in an array
- }
Finally, since we are now editing our existing array, we need to make sure we reference it (ensuring our changes are reflected after the foreach completes), which also means we only have to pass back our even array:
- foreach(reference! Thing in array){
- if(thing / 2 is 0) then add it to even array, delete from this array
- send even array back
- }
While none of the above examples would work (they are just pseudo-code), we were able to edit a conceptual version of our program four times. Alternatively we would have spent time creating and revising actual lines of code three times, only to keep finding an issue, backing up, and make lots of changes.
Comments
To quote Eagleson’s Law, “Any code you have not looked at for six or more months might as well have been written by someone else.” This is not to say that your style or approach will change drastically over time, but that your immediate memory of what variables mean, why certain exceptions were made, or what the code, ultimately, was meant to address may not be as apparent as when you last worked on the file. It is natural for us to feel that we will remember these details as they are so obvious when we are creating them. The need for good commenting becomes immediately apparent when reviewing someone else’s work, and you are wallowing in frustration trying to figure out what that person was trying to do.
This is not meant to endorse comments that are obvious to the reader from the line, like:
- $int = 2 + 2 //we added 2 and 2 together
Rather, comments are best suited to explaining why agreed upon methods were not used or what difficult to understand code might be doing, like:
- // This block of code checks each text file in the folder for the given date and deletes it
- // This is legacy code from when Frank M. worked here. If we change anything, payroll breaks
Order of Assignment
Many scripting languages distinguish between assignment statements and logical tests based on the number of equal signs used in the statement. For example, giving the variable $temp the value of 10 (also called “setting” or “assigning” the variable) can be expressed as $temp = 10, while checking the value would look like if ($temp == 10). It is very easy to forget the extra = when writing logic statements, since we are so conditioned to using it in singular form.
This creates issues as a logic test written as if ($temp = 10) will always be true. First, we are executing what is in the parenthesis—in this case, setting temp equal to 10. When this occurs, the system returns returns a result of “true” to the script—the request has been completed. This is like asking if true is true—it always is! Since this does not cause a problem that stops the program from running, we will not get any errors before running it. The errors will be discovered only when the program does not behave as intended, and depending on the nature of the logic statement we wanted, that might be a rare case, making for some frustrating debugging. These are called logical errors, as the compiler or engine can run the code we gave it, and the error lies between expected execution and what the system is actually programmed to do. We will look at this further in Chapter 27.
To protect ourselves from this, we can invert our logic statements to put our values first. Since we cannot assign a variable to a number, writing 10 = $temp would be considered invalid, as 10 does not represent a place in system memory. Neither variables nor constants can start with a number, even $10 is invalid. However, if (10 == $temp) is still valid, as the system compares both sides of the equation to each other, and is indifferent to the order.
By placing values first in our logic statements, if we forget to use the correct number of =, we will get an error from the engine early on that we can immediately find and fix. Otherwise we are left with a logic error that needs to be traced through our program later when we discover it is not working correctly.
Read Me
Closely connected with the concept of good commenting is the ubiquitous readme file—familiar to many users as the basic text file no one ever reads despite its title’s quiet plea. The readme file’s continued prevalence in such an antiquated file format is done to ensure it is legible on the widest variety of operating systems, and is still considered the best delivery format.
Within your readme file should be notes targeting your end users. Unless you release open source code, they would not be able to read your comments. These notes should tell the user what the application’s requirements are, how to install it, how to get help, and if you like, what notable changes are in the version they are looking at compared to its predecessor(s). Typically, the most common location to put a readme file is in the root folder of your files, or in a sub folder in which the readme notes apply to.
Spacing
Just as we use spacing in documents to convey that a topic change is occurring, we can break up longer string of commands by putting spaces around lines that are grouped together to complete a particular task, signifying that the next set of lines is for another task.
Brackets
Some languages require the programmer to use a combination of parenthesis and brackets to identify what pieces of code belong together. This allows the engine or compiler to delineate between the code that should be tested as a logic statement, code that gets executed if that statement is true, and code that belongs to functions or classes.
As we write our code and reach instances where we need these elements, it is good practice to immediately enter both the starting and ending marker first, then create space between them to enter your code. This will help ensure that you do not forget to close brackets later, or close them in the wrong places when nesting code. Depending on your text editor, it may assist you by automatically adding closing brackets and helping you identify which opening and closing brackets go together.
Indentation
To make your code easier to read, you can use indentation to give the reader an idea of what lines of code belong to different sections. This is typically done inside functions, classes, and control structures. When we nest code, extra indentations are added for each layer within, moving those blocks of text further right to visually distinguish. As we finish the contents of a loop or function, our closing bracket is lined up with our function definition or logic statement to show that the section of code belonging to it is complete.
While our program will run just fine without indentation, it makes it easier to see where you are in your program and where the line you are looking at is intended to be in the logic flow.
 Figure 18 Code Formatting Examples
Figure 18 Code Formatting Examples
Meaningful Variable Names
When you create variables and functions, try to create names that will have meaning not only to you, but to others who may read your code. While it can be tempting to use a lot of short variable names while writing your code, it will be more difficult later to follow what the variable is supposed to represent. You might decide to use short names like queryResult or query_result or something longer like numberOfResumesReceived. While the latter takes longer to type while coding, the name is very clear on what it represents. As spaces are generally prohibited in variable names, these examples show us a few ways to approach longer names. The method you use is up to you, but should be used consistently throughout your code to reduce confusion. Differences in how and where you use capitalization or underscores can be used to represent different types of variables like classes or groups of variables.
Short variable names like a simple x or generic name like temp may have their places in your code, but are best reserved for when they identify a small variable or one which will have a very short shelf life in your code.
Versioning
This is the process of creating multiple versions of your software, instead of continuously overwriting your sole edition of code. By creating different copies of your program as you create new features, you can preserve working copies or even create different versions of your program. This allows you to “roll back” or restore previous versions if unforeseen errors are created in new code, or to allow different features to be tried and discarded over time. Naming conventions for different versions of your code might involve numbers, letters, release stages (i.e. alpha, beta, release candidate, and release) a combination of all of these, or just “development” and “live.”
GitHub
A popular tool for collaborating on projects right now is GitHub.23 Focusing on open source projects, GitHub is a cloud service with locally installed application options that focuses on branching. Branching facilitates multiple working versions with varying features to co-exist in the same project space, giving the developers the ability to selectively merge new code into their project’s official repository. The platform supports code sharing, generating branches, and includes discussion boards, bugs, and feature request areas.
Development Tools
The following tools can be very useful in accelerating project development by reducing repetitive tasks and providing collections of tools to help you write your code. I would encourage you to refrain from using them until you have at least mastered the material in this text, otherwise, you may complicate your debugging tasks or not fully understand what those tools are doing.
Frameworks
Frameworks are compilations of code that you can use to quickly start a site with a collection of features already in place. In a home building analogy, it would be akin to ordering parts of your house already completed, and having special tools in your toolbox for putting the pre-built pieces together.
A typical framework is a set of files that come with their own instructions, and can be so extensive that they take on a life and syntax beyond the language they are written in. They extend the features normally found in the language they are written in by adding their own classes, functions, and capabilities. The goal is that by giving the framework a few commands, we can create much larger processes like a menu system or complete color scheme. Some frameworks focus on the automation of repetitive tasks like generating forms and pages based on tables in a database, or applying in depth style and structure across a website.
Multiple frameworks can be combined in a single project in order to add a combination of features, for example using one framework for the site layout and another for generating database interactions. Each framework will require some time learning how to use its features, just like learning a programming language. This may be an important factor when deciding when and how many to use in your work.
Smarty24
The Smarty template engine targets the separation of application logic and presentation. While it creates delineations between the code necessary to generate the content and the code to present the content, it is not a full model-view-controller design. A smarty template page supports special tags and commands that are part of the smarty engine. These elements help to generate what the end product will look like, after generating the PHP necessary to build the page. Smarty also uses a template caching approach to facilitate delivering pages faster, only updating cached templates when changes to a smarty file or its dependencies are detected.
Yii Framework25
The Yii framework focuses on reducing SQL statement writing, follows Model View Controller methods, and helps create themes, web services, and integration with other platforms. It also includes security, authentication, and unit based approaches to development.
Zend Framework26
The Zend framework is focused heavily on modularity, performance, and maintaining an extensible approach to allow continued integration. This framework is popular at the enterprise level, and includes some of the original creators of PHP on staff. Zend itself is a full service PHP company, providing training, development services, and the continued refinement of the PHP language itself.
Templates
Similar to the idea behind frameworks, templates are sets of files that dictate the basic structure that provides a layout to your site. Templates typically create a grid format you can select from, like two or three columns, fixed or relative width and height, etc. If you are starting a site fresh and putting it into an empty template, there may be some placeholder content and styling as well. Templates are useful for getting the look and feel of a site up and running fast and there is little concern about the particulars of appearance, or whenever the template meets your needs well. When inserting your content dynamically, multiple templates can be used for one site to change the look and feel quickly based on which one is applied. This might be determined by what type of device your guest is using, or what type of authentication they are using.
Templates can be both freestanding, or can be an extension of a content management system or framework.
Bootstrap27
Bootstrap was created by Twitter in order to help them manage their extremely popular service. As it matured, they made it open source to allow others to utilize the toolset. Their framework provides tools for styling, interaction elements like forms and buttons, and navigation elements including drop downs, alert boxes, and more. Using this frame work involves little more than linking to the appropriate JavaScript and CSS files and then referencing the appropriate style classes in your code.
Foundation28
The Foundation system focuses on front end design and follows the principles of responsive web design (see next section). Their approach uses a grid layout to allow flexibility, accelerate prototyping and wire framing, and provides integrated support for multi-platform designs.
Responsive Web Design
As often as possible, this text will focus on coding methods that support responsive web design. This approach replaces the practice of developing several version of your site in order to support different devices. An example of this is when you come across sites with a regular site, a mobile site (for example m.yoursite.com) and then provide an app for each of the tablet platforms, or force tablet users into their mobile or desktop experience.
Instead, we will create one set of files that changes its own layout and appearance based on what we know. By using information made available in the initial http request to our site, we can determine the features the user’s browser supports, width and height of their screen, and more. We can use this information to instruct our CSS files on what rules to apply when styling the page, how much or little to resize elements on our page, what we want to eliminate or hide on smaller screens, and more.
While this approach is still not a perfect solution, it gives us a much-improved ability to support a wide variety of devices without managing several code bases and developing across multiple proprietary platforms.
Integrated Development Environments
This list is by no means comprehensive. These editors are sufficient to get you started. If you wish to continue in web programming, you may elect to invest in a development platform like Adobe Dreamweaver or another professional product that supports more advanced design, or try any number of other IDEs available that focus on a variety of different languages.
You might consider the following programs to help you write your code (listed in no particular order). Each of these has features particular for web development and should be sufficiently capable to get you through the examples in this text.
Jedit29
A free editor based around Java. Works on multiple platforms (Windows, Mac and Linux) and includes syntax highlighting.
Notepad++30
Notepad++ is a source code text editor with syntax highlighting, multiple document handling using tabs, auto-completion of keywords (customizable), regular expressions in the search and replace function, macro recording and playback, brace and indent highlighting, collapsing and expanding of sections of code, and more.
Bluefish31
Supports many programming and markup languages. An open source development project, multi-platform, and runs on Linux, FreeBSD, MacOS-X, Windows, OpenBSD and Solaris.
TextWrangler32
This editor is related to BBEdit. It does not include as many tools, but retains syntax highlighting and the ability to use FTP within the editor.
Application Programming Interfaces
Commonly referred to as APIs, pronounced as the letters of the acronym, application programming interfaces allow us to interact with features and data of a system other than its primary means, whether it is an application or website. Created to address needs of data exchange and integration between systems, APIs provide a controlled method of allowing others to use a system without having direct, unfettered access to the code or database it runs on. Examples of APIs in action are maps on non-google website that are fed from Google Maps with markers, that highlight paths and routes, automate directions, or outline places of interest. All of this is done from within their site or system without you leaving to interact with Google. Another example is the growing popularity of sites for clans or groups of friends in multi-player games that provide results, show game statistics, screen shots, and rankings from a site they create by using the game developer’s API to access their data.
Web-based APIs are, essentially, limited websites. They allow the pages and scripts end users create to communicate with the data source by using a predetermined vocabulary and fixed amount of options. When the user’s message reaches the API, the API completes the requested task such as getting a certain piece of data, or validating credentials, and returns the results, hiding anything the developers do not want revealed, and only provides the features they are comfortable with others using.
The result is that end users are free (within the limits of the API) to create their own systems exactly as they want, interfacing with their own systems, or creating all new systems the developers of the API had not thought of or decided not to pursue. APIs can cut down on the development time of your own system as you can use them to support your project, like our example of embedding Google Maps instead of creating or installing a map system. By combining several disparate systems through their APIs, a mashup is created, which is a new feature, application, or service created by combing several others. APIs are often included as part of a software development kit (SDK) that includes the API, programming tools, and documentation to assist developers in creating applications.
 Figure 19 API Data Flow
Figure 19 API Data Flow
Learn more
Keywords, search terms: Development methods, coding practices, team development
Cisco Networking Example: http://docwiki.cisco.com/wiki/Internetworking_Basics
List and description of all top level domains: http://www.icann.org/en/resources/registries/tlds
Ongoing comparison of hosting providers: http://www.findmyhosting.com/
Software Development Philosophies: http://en.Wikipedia.org/wiki/List_of_software_development_philosophies