
23: Functions (2 of 2)
- Page ID
- 83009

Like many things in life, writing functions is best learned by example. This chapter will feature several more of them that you can learn from and imitate.
Basketball scoring: bb_pts()
Continuing the sports theme, the total points a basketball player scores is related to the number of shots she makes of various kinds. Typically, the “box score” of a game (see example in Figure 23.1) reports three scoring stats: (1) the total number of “field goals”1 a player made and attempted, (2) the number of these field goals, if any, that were for three points2, and (3) the number of free throws (“easy” penalty shots) the player attempted and made.
Confusingly, (1) includes (2). In other words, if the first number is 4 and the second is 1, the player didn’t score 4 regular two-point baskets and 1 three-pointer, but rather 3 two-point baskets and 1 three-pointer.
In Figure 23.1, the FGM-A column gives the first of these three categories, 3PM-A the second, and FTM-A the third. The PTS column gives the total number of points that player scored. (For example, Molly Sharman made 5 of her 8 attempted field goals, one of which was for three points, and she also converted both free throw attempts.)

All that took a lot longer to explain than the corresponding Python function:
Code \(\PageIndex{1}\) (Python):
def bb_pts(fgm, threep_fgm, ftm):
return ((fgm - threep_fgm) * 2) + (threep_fgm * 3) + ftm
torys_pts = bb_pts(6, 0, 1)
print("Tory scored {} points.".format(torys_pts))
print("Emily scored {} points.".format(bb_pts(6,5,5)))
print("Lady Eagles scored {} points!".format(bb_pts(28,8,11)))
Output:
Strictly speaking you don’t need all those bananas (regular PEMDAS order-of-operations applies) but I think it’s a good idea to include them for clarity and grouping.
“Exceptions”: mean_no_outliers() and quiz_avg()
Sometimes we want to take the straight average of a data set, but other times we may want to filter out any strange or exceptional cases. Let’s say we’re computing the average age of a classroom of college students, but we want to remove any adult learners over 30 since that would skew the result. We could do this sort of thing with a function like this:
Code \(\PageIndex{2}\) (Python):
def mean_no_outliers(a, low_cutoff, high_cutoff):
return a[(a >= low_cutoff) & (a <= high_cutoff)].mean()
our_class = np.array([20,18,19,18,22,21,76,20,22,22,21,18])
print("The average age (excluding outliers) is {}.".format(
mean_no_outliers(our_class, 0, 30)))
Output:
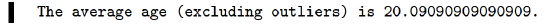
We’ve provided two arguments to the function besides the data set itself: a lower and upper bound. Anything falling outside that range will be filtered out. In the example function call, we passed 0 for the low_cutoff since we didn’t desire to filter anything at the low end. (If we wanted to, say, also remove children from the data set, we could have set that to 16 or so.)
By the way, you might find the number of decimal places printed to be unsightly. If so, we could enhance our function by rounding the result to (say) two decimals with NumPy’s round() function:
Code \(\PageIndex{3}\) (Python):
def mean_no_outliers(a, low_cutoff, high_cutoff):
return np.round(a[
(a >= low_cutoff) & (a <= high_cutoff)].mean(),2)
print("The average age (excluding outliers) is {}.".format(
mean_no_outliers(our_class, 0, 30)))
Output:
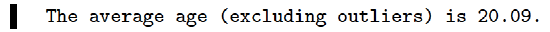
At this point you might think this function is getting pretty big for a one-liner. I agree. Let’s split it up and use some temporary variables to make it more readable:
Code \(\PageIndex{4}\) (Python):
def mean_no_outliers(a, low_cutoff, high_cutoff):
filtered_data = a[(a >= low_cutoff) & (a <= high_cutoff)]
filtered_average = np.round(filtered_data)
return np.round(filtered_average,2)
Much clearer!
A related but different example would be to remove a fixed number of data points from the end, instead of data points outside a specified range. For instance, in my classes, I often give students (say) eight quizzes during a semester, and drop the lowest two scores. That could be done with:
Code \(\PageIndex{5}\) (Python):
def quiz_avg(quizzes):
dropped_lowest_two = np.sort(quizzes)[2:]
return dropped_lowest_two.mean()
filberts_quizzes = np.array([7,9,10,7,0,8,4,10])
print("Filbert's avg score was {}.".format(quiz_avg(filberts_quizzes)))
Output:
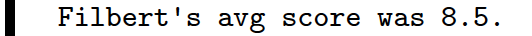
Filbert’s 0 and 4 were dropped, leaving him with a pretty good semester score.
The trick to this implementation is sorting the quiz scores. Once you do that, it’s easy to pick out the top six to take the average, since the lowest two scores will be at the beginning of the (sorted) array. Two notes here:
• We use the np.sort() function, not the .sort() method, since we don’t want to permanently change the order of quizzes. We only need a temporarily sorted copy so we can omit the lowest two entries.
• That business in the boxies (“[2:]”) is a slice (recall section 9.2 on p. 76) which says “only give me entries number 2 through the end of the array.” And that’s exactly what the doctor ordered to omit the first two.
Searching for values: any_zeros()
I’ll end this chapter with an example which, like the “preferred language” example on p. 214, flummoxes nearly every beginning student.
Suppose students in a DATA 101 course are given labs to complete, each one worth up to 20 points. (This is purely hypothetical, as you can see.) At the midway point of the semester, the instructor would like a quick list of any students who failed to turn in one of the labs, so he can harass them for their own good.
Here’s the gradebook DataFrame this professor is using:
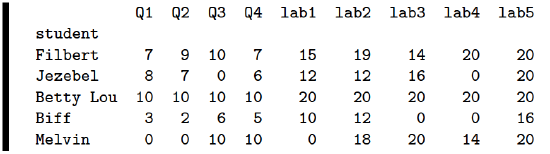
Let’s write a function called print_harass_list() whose job is to tell this professor which students he should check up on. We’ll write it as follows:
Code \(\PageIndex{6}\) (Python):
def print_harass_list(gradebook):
for row in gradebook.itertuples():
if any_zeros(np.array([row.lab1, row.lab2, row.lab3, row.lab4, row.lab5])):
print("Better check up on {}.".format(row.Index))
Note that we’ve pushed some of the work on to a new function, any_zeros(), that we haven’t written yet. This is good organizational style. Now print_harass_list() can do the job of iterating through the DataFrame rows, extracting the lab scores, and printing a message if necessary, whereas it defers to any_zeros() to inspect the lab scores and determine the presence of any zeros.
It doesn’t work until we actually write the second function, of course, so here goes. Heads up, since this is the part that perplexes students. The following implementation of any_zeros() looks perfectly reasonable, yet is dead WRONG:
Code \(\PageIndex{7}\) (Python):
def any_zeros_WRONG(labs):
for lab in labs:
if lab == 0:
return True
else:
return False
It looks so correct! And yet it is not. Check out the result:
Code \(\PageIndex{8}\) (Python):
print_harass_list(gradebook)
Output:

Clearly we need to check up on Jezebel and Biff as well (look at their scores for labs 3 and 4), yet they inexplicably didn’t get printed. Here’s what’s WRONG with that any_zeros() attempt. Stare carefully at that loop and realize that the body of the loop is comprised of a single if/else statement. And remember our cardinal rule from the grey box on p. 214: either the if body or the else body will always be executed.
That means that this loop is destined to only execute exactly once! It doesn’t matter how long the labs array is. It effectively looks only at the first element, and decides based solely on that whether or not the entire array has any zeros in it!
The correct version of any_zeros() would look like this:
Code \(\PageIndex{9}\) (Python):
def any_zeros(labs):
for lab in labs:
if lab == 0:
return True
return False
At first glance, it may appear unchanged, but look again. First of all, there’s no else anymore. Second of all, the “return False” line is indented evenly with the word for. This means that “return False” is not part of the loop at all: it will only run after the entire loop has executed.
That turns out to make all the difference. The function will dutifully go through each element of the labs array, inspecting each one to see whether it’s zero. As soon as it finds a zero, it returns True, since then its job is done. Only after inspecting the entire array, and coming up empty on its zero quest, does this function then have the audacity to return False, meaning “nope! Clean as a whistle.” The result:
Output:

Postlude: thinking algorithmically
Getting tripped up on that last example is, I believe, usually a case of thinking holistically rather than thinking algorithmically. Math classes have trained people to think holistically, by which I mean looking at (say) a bunch of equations and viewing them as “all equally true, all at once.” And this is the correct way to think mathematically. If I give you five simultaneous equations that state relationships among variables, they aren’t really in any order. They’re just “five true things.”
But programming requires you to think algorithmically. You have to execute the code in your head, step by step, and realize the consequences. The appealing symmetry of the WRONG any_zeros() function is appealing because you’re looking at it as a whole: “it’s looping (seemingly) through all the elements, with zeros being an indicator of Trueness and non-zeros being an indicator of Falseness. What’s not to like?” The error, as you saw, is that when running through the data step-by-step, there are immense ramifications of returning early. That’s only apparent if you think of the code executing sequentially as it goes. You have to pretend you’re the computer, not a mathematician.
1A “field goal” in basketball just means “a regular basket” – i.e., not a free throw penalty shot.
2In most leagues, a basket is worth 2 points unless the shooter was farther than a certain distance from the hoop when she shot it, in which case it’s worth 3.