
10.4: Dealing with Confounding Factors
- Page ID
- 39267

Confounding factors are evil, and we must deal with them seriously. There are essentially two ways to do that: one that requires us to be smart, and one that requires us to have money.
Controlling for a Confounding Factor
If we anticipate that a certain variable may be a confounding factor, we can control for it. There are several techniques for this, some of which you’ll learn in your statistics class, but the simplest one to understand involves stratification.
Let’s make a silly example this time. We’ll go back to the earlier pinterest theme. I think I’ve noticed over the past few years that the heavy pinterest users I know seem to almost always have long hair. I’ve developed a hypothesis about this, which involves theories about how protein filaments in follicles with longer protrusions lead to certain chemical changes in the brain. These mind alterations, if unchecked, lead to increased creativity, craftiness, and a desire to share artistic creations with other like-minded individuals. Further, these aesthetic desires manifest themselves in increased usage of the pinterest.com website, as measured in number of logins per day.
My theory is thus reflected in the causal diagram in Figure 10.4.1. Study it carefully.
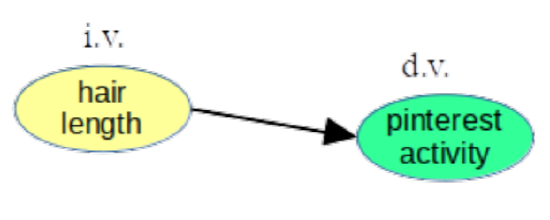
Figure \(\PageIndex{1}\): A theory about how hair length impacts the number of times a person logs on to pinterest each day.
Now of course this follicle stuff is bogus. I’m using an extreme example to make a point. Quick, can you come up with a possible confounding factor? Yeah, drr: gender. It’s undoubtedly true that women tend to (but don’t always) have longer hair than men, and it’s undoubtedly true that pinterest.com is a website that tends to appeal to (but not exclusively to) women. And causality-wise, the arrows obviously flow from gender, not to it: the pinterest login screen doesn’t change your gender, and a man won’t turn into a woman simply by growing his hair long (although a transgender woman might grow her hair long as a signal of her underlying gender change.)
Put that all together, and you get the much more plausible causal diagram in Figure 10.4.2.
Now then. Controlling for a confounding variable through stratification is done by considering the objects of the study in groups, comparing only those who have the same (or similar) value for the confounding variable.
In this case, we would separate the men from the women in our study. Looking at just the men, we would ask, “is longer hair associated with frequency of pinterest logins?” Then we would do the same, looking at just the women. Only if Python reported that both of these separate groups illustrated such a trend would we (tentatively) conclude, “hair length itself does play a role in causing pinterest activity, even when controlling for gender.”
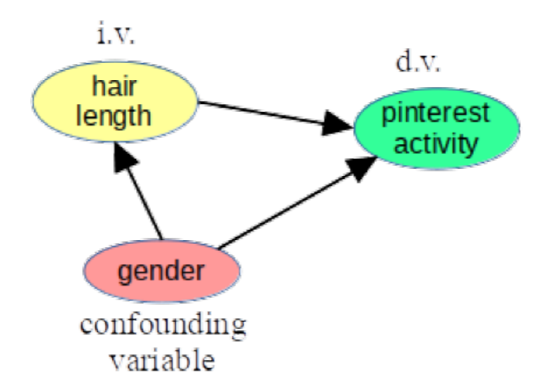
Figure \(\PageIndex{2}\): An alternative theory that holds that a person’s gender influences both their long-haired-ness and their pinterest-ness.
Do the thought experiment to see if you agree. I know the whole follicle theory struck you as dumb (and hopefully, a little funny) to begin with. “Of course,” you said to yourself, “it’s gender, not hair length, that’s drawing users to pinterest, dummy!” But suppose we did perform that stratification technique, and discovered that the association actually did hold in both cases. Would that give it more credence in your mind? It ought to. By stratifying, we’ve eliminated gender from the picture entirely, and now we’re faced with the facts that those with longer hair – regardless of gender – log on to pinterest more often.
Now I wrote the word “tentatively” a couple paragraphs ago, because there are still some caveats. For one, we don’t actually know that the causality goes in the stated direction. Removing the gender confounder, we confirmed that there is still an association between hair length and pinterest, but that association might translate into a B → A phenomenon. Perhaps users who log on to pinterest a lot see a lot of long-haired users, and (consciously or not) decide to grow their own hair out as a result? That actually sounds more plausible than the original silly theory. Either way, we can’t confirm the direction just by stratifying.
The other caveat is even more important, because it’s more pervasive: just because we got rid of one confounding variable doesn’t mean there aren’t others. The whole “control for a variable” approach requires us to anticipate in advance what the possible confounding factors would be. This is why I said back on p. 96 that this approach requires the experimenter to be smart.
Running a Controlled Experiment
The other way to deal with confounding variables is to run a controlled experiment instead of an observational study. I jokingly said on p. 96 that this option requires the experimenter to have money. Let me explain.
An observational study is one in which data is produced by naturally occurring processes (we’ll call them data-generating processes, or DGPs) and then collected by the researcher. Crucially, the experimenter plays no role in influencing what any of the variable values are, whether that be the i.v. , the d.v. , other related variables, or even possible confounders. Everything just is what it is, and the researcher is simply observing.
Now at first this sounds like the best of all possible worlds. Scientists are supposed to be objective, and to do everything they can to avoid biasing the results, right? True, but the sad fact is that every observational study has potential confounding factors and there’s simply no foolproof way to account for them all. If you knew them all, you could potentially account for them. But in general we don’t know. It all hinges on our cleverness, which is a bit like rolling the dice.
A controlled experiment, on the other hand, is one in which the researcher decides what the value of the i.v. will be for each object of study. She normally does this randomly, which is why this technique is called randomization.
Now controlled experiments bear some good news and some bad news. First, the good news, which is incredibly good, actually: a controlled experiment automatically eliminates every possible confounding factor, whether you thought of it or not. Wow: magic!
We get this boon because of how the i.v. works. The researcher’s coin flip is the sole determinant of who gets which i.v. value. That means that no other factor can be “upstream” of the coin flip and influence it in any way. And this in turn nullifies all possible confounding factors, since as you recall, a confounder must affect both the i.v. and the d.v.
The catch is that controlled experiments can be very expensive to run, and in many cases can’t be run at all. Consider the barbecue example from p. 92. To carry out a controlled experiment, we would have to:
- Recruit participants to our study, and get their informed consent.
- Pay them some $$ for their trouble.
- For each participant, flip a coin. If it comes up heads, that person must eat barbecue three times per week for the next ten years. If it’s tails, that person must never eat barbecue for the next ten years.
- At the end of the ten years, measure how many barbecuers and non-barbecuers have cancer.
There’s a question of this even being ethical: if we suspect that eating barbecue can cause cancer, is it okay to “force” participants to eat it? Even past that point, however, there’s the expense. Ask yourself: if you were a potential participant in this experiment, how much money would you demand in step 2 to change your lifestyle to this degree? You might love barbecue, or you might hate it, but either way, it’s a coin flip that makes your decision for you. That’s a costly and intrusive change to make.
Other scenarios are even worse, because they’re downright impossible. We can’t flip coins and make (at random) half of our experimental subjects male and the other half female. We can’t (or at least, shouldn’t) randomly decide our participants’ political affiliations, making one random half be Democrats and the others Republicans. And we certainly can’t dictate to the nations of the world to emit large quantities of greenhouse gases in some years and small quantities in others, depending on our coin flip for that year.
Bottom line: if you can afford to gather data from a controlled experiment rather than an observational study, always choose to do so. Unfortunately, it won’t always be possible, and we’ll have to rest on the uneasy assumption that we successfully predicted in advance all the important confounding variables and controlled for them.