
12.2: Vectorized Arithmetic Operators
- Page ID
- 39279

As with NumPy ndarrays, you can apply arithmetic operators like + and * to entire Serieses at a time, which is not only easy code to write but also runs blazing fast. But the Pandas Series is even smarter than that.
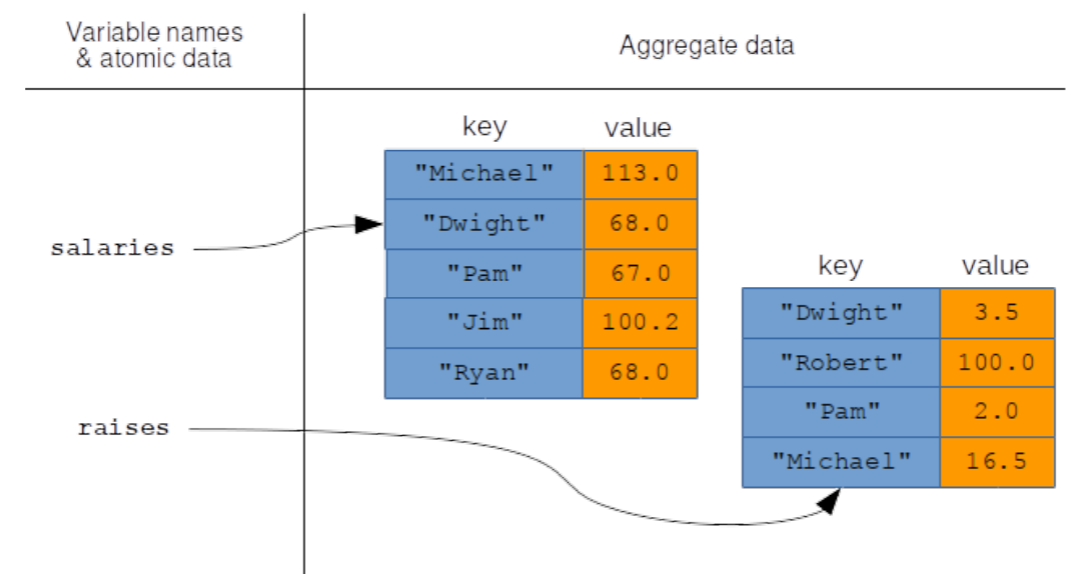
Figure \(\PageIndex{1}\): Two Serieses in memory
Consider the memory picture in Figure 12.1. Here we have two Serieses, one pointed to by a salaries variable and the other by raises, which are of different sizes and which have overlapping, but not identical, sets of keys. What do you suppose Pandas would do if we executed this code?
Code \(\PageIndex{1}\) (Python):
new_salaries = salaries + raises
The answer, happily, is the smartest possible thing it could do. Pandas gets neither confused nor stifled by the fact that the keys are in different orders in the two Serieses, and instead it does what you surely want: add corresponding elements, with matching keys, and produce a new Series with all of those sums.
The actual result in this case is in Figure 12.2.2, and the output is here:
Code \(\PageIndex{2}\) (Python):
new_salaries = salaries + raises
print(new_salaries)
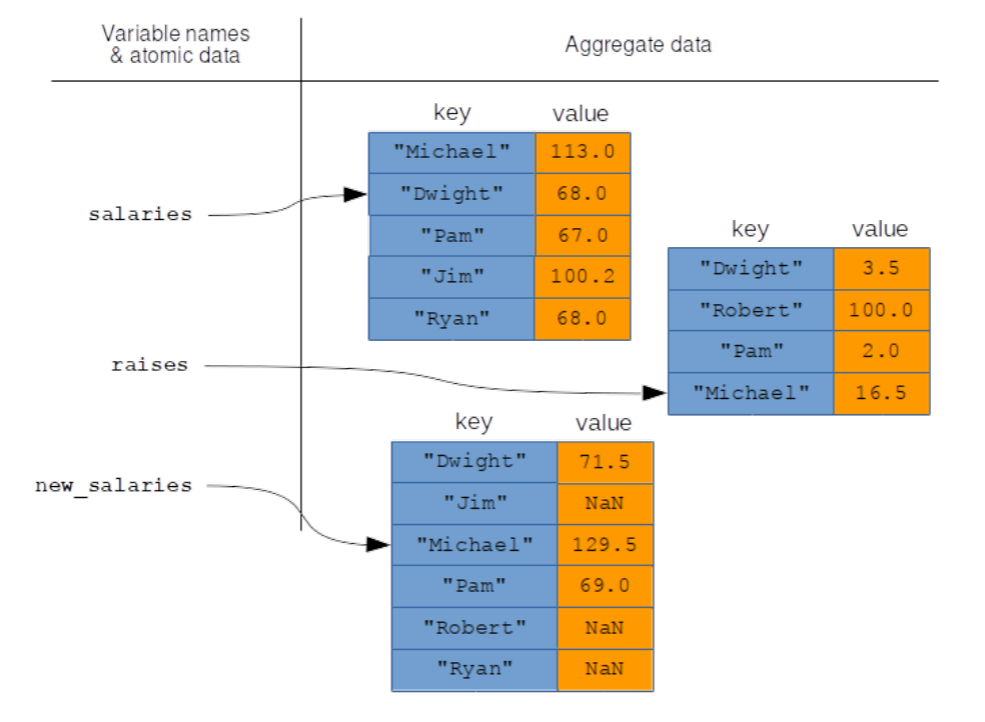
Figure \(\PageIndex{2}\): The result of +’ing two Serieses that don’t have all the same keys.
| Dwight 71.5
| Jim NaN
| Michael 129.5
| Pam 69.0
| Robert NaN
| Ryan NaN
| dtype: float64
Convince yourself that Dwight’s $68,000 salary got added to his $3,500 raise, that Michael’s $113,000 salary was added to his $16,500 raise, etc.
Don’t get freaked out by those NaN entries just yet. The special value “NaN” stands for “not a number,” and basically means that Pandas has to throw up its hands in that case. And with good cause. Jim has a current salary of $100,200 in the first Series, but has no value at all in the second one (no raise for Jim this year? Haven’t decided what his raise will be yet? Something else?) So Pandas does the safe thing, shrugs, and says “dunno.” We say that the Jim entry in the new_salaries Series is a missing value. The same is true for Robert and Ryan, each of whom was present in only one of the two operands.
Now I know what you’re thinking: “can’t Pandas just assume the salary and/or raise is 0 if there’s a missing one?” The answer is that yes it can, but it won’t do so unless you give the go-ahead. Pandas is being cautious here, and doesn’t want to introduce errors into your data stream by false assumptions. (Maybe in your company, for instance, there’s a default entry-level salary that every employee receives who’s unspecified in the salary Series. Or maybe the yearly raise is always assumed to be a flat 2.5% cost-of-living raise unless explicitly specified.)
If we do want Pandas to assume a certain default value, we have to change tactics a bit and go with the add() function (or sub(), mul(), or div()):
Code \(\PageIndex{3}\) (Python):
new_salaries = pd.Series.add(salaries, raises, fill_value=0)
print(new_salaries)
| Dwight 71.5
| Jim 100.2
| Michael 129.5
| Pam 69.0
| Robert 100.0
| Ryan 68.0
| dtype: float64
The fill_value argument is the important one here: it specifies what default value to use if one of the addends is missing a key from the other. Now the result is as in Figure 12.2.3. You can, of course, choose a fill_value other than zero, if you wish.
As with NumPy arrays, we can add (or subtract, or multiply, ...) a single atomic value to a series as well:
Code \(\PageIndex{4}\) (Python):
cost_of_living_increase = salaries * .025
print(cost_of_living_increase)
Figure \(\PageIndex{3}\): Using add() instead, and passing a fill_value.
| Micheal 2.825
| Dwight 1.700
| Pam 1.675
| Jim 2.505
| Ryan 1.700
| dtype: float64
Code \(\PageIndex{5}\) (Python):
salaries = salaries + cost_of_living_increase
print(salaries)
| Micheal 115.825
| Dwight 69.700
| Pam 68.675
| Jim 102.705
| Ryan 69.700
| dtype: float64
It can sometimes be useful to do string concatenation as well, for instance if we had employee first names and last names in two Serieses with their employee ID as the index:
Code \(\PageIndex{6}\) (Python):
firsts = pd.Series(['Hannibal', 'Clarice', 'Multiple', 'Buffalo'], index=[666, 1993, 47, 988])
lasts = pd.Series(['Starling', 'Crawford', 'Lecter', 'Bill', 'Miggs'], index=[1993, 1650, 666, 988, 47])
print(firsts + " " + lasts)
| 47 Multiple Miggs
| 666 Hannibal Lecter
| 988 Buffalo Bill
| 1650 NaN
| 1993 Clarice Starling
| dtype: object