
3.6: Finite-State Automata and Regular Lan- guages
- Page ID
- 6727

We know now that our two models for mechanical language recognition actually recognize the same class of languages. The question still remains: do they recognize the same class of languages as the class generated mechanically by regular expressions? The answer turns out to be “yes”. There are two parts to proving this: first that every language generated can be recognized, and second that every language recognized can be generated.
Theorem 3.3.
Every language generated by a regular expression can be recognized by an NFA.
Proof. The proof of this theorem is a nice example of a proof by induction on the structure of regular expressions. The definition of regular expression is inductive: \(\Phi, \varepsilon,\) and \(a\)are the simplest regular expressions, and then more complicated regular expressions can be built from these. We will show that there are NFAs that accept the languages generated by the simplest regular expressions, and then show how those machines can be put together to form machines that accept languages generated by more complicated regular expressions.
Consider the regular expression \(\Phi . L(\Phi)=\{ \} .\) Here is a machine that accepts {}:
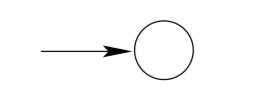
Consider the regular expression \(\varepsilon . L(\varepsilon)=\{\varepsilon\} .\) Here is a machine that accepts \(\{\varepsilon\} :\)
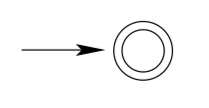
Consider the regular expression a. \(L(a)=\{a\} .\) Here is a machine that accepts \(\{a\} :\)
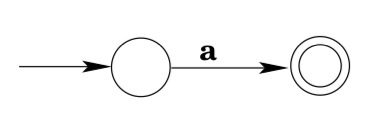
Now suppose that you have NFAs that accept the languages generated by the regular expressions \(r_{1}\) and \(r_{2}\). Building a machine that accepts \(L\left(r_{1} | r_{2}\right)\) is fairly straightforward: take an NFA \(M_{1}\) that accepts \(L\left(r_{1}\right)\) and an NFA \(M_{2}\) that accepts \(L\left(r_{2}\right)\). Introduce a new state qnew, connect it to the start states of \(M_{1}\) and \(M_{2}\) via ε-transitions, and designate it as the start state of the new machine. No other transitions are added. The final states of \(M_{1}\) together with the final states of M2 are designated as the final states of the new machine. It should be fairly clear that this new machine accepts exactly those strings accepted by \(M_{1}\) together with those strings accepted by M2: any string w that was accepted by M1 will be accepted by the new NFA by starting with an ε-transition to the old start state of \(M_{1}\) and then following the accepting path through \(M_{1}\); similarly, any string accepted by \(M_{2}\) will be accepted by the new machine; these are the only strings that will be accepted by the new machine, as on any input w all the new machine can do is make an ε-move to \(M_{1}\)’s (or \(M_{2}\)’s) start state, and from there w will only be accepted by the new machine if it is accepted by \(M_{1}\) (or \(M_{2}\)). Thus, the new machine accepts \(L\left(M_{1}\right) \cup L\left(M_{2}\right)\), which is \(L\left(r_{1}\right) \cup L\left(r_{2}\right)\), which is exactly the definition of \(L\left(r_{1} | r_{2}\right)\).
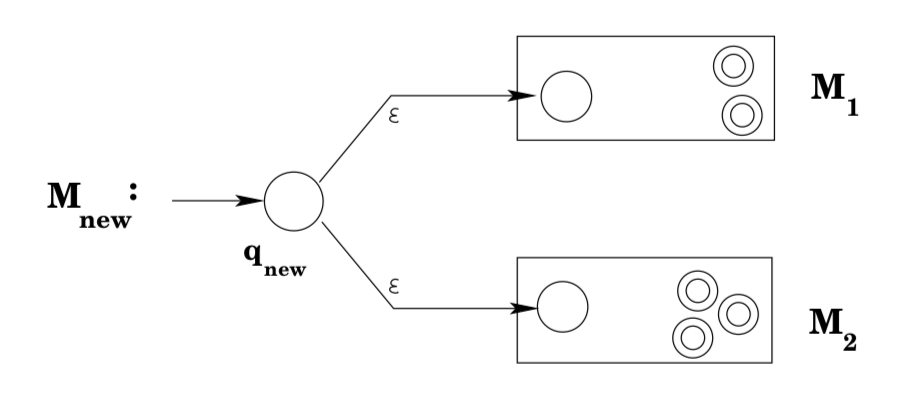
(A pause before we continue: note that for the simplest regular expressions, the machines that we created to accept the languages generated by the regular expressions were in fact DFAs. In our last case above, however, we needed ε-transitions to build the new machine, and so if we were trying to prove that every regular language could be accepted by a DFA, our proof would be in trouble. THIS DOES NOT MEAN that the statement “every regular language can be accepted by a DFA” is false, just that we can’t prove it using this kind of argument, and would have to find an alternative proof.)
Suppose you have machines \(M_{1}\) and \(M_{2}\) that accept \(L\left(r_{1}\right)\) and \(L\left(r_{2}\right)\) respectively. To build a machine that accepts\(L\left(r_{1}\right) L\left(r_{2}\right)\) proceed as follows. Make the start state \(q_{01}\) of \(M_{1}\) be the start state of the new machine. Make the final states of \(M_{2}\) be the final states of the new machine. Add ε- transitions from the final states of \(M_{1}\) to the start state \(q_{02}\) of \(M_{2}\).
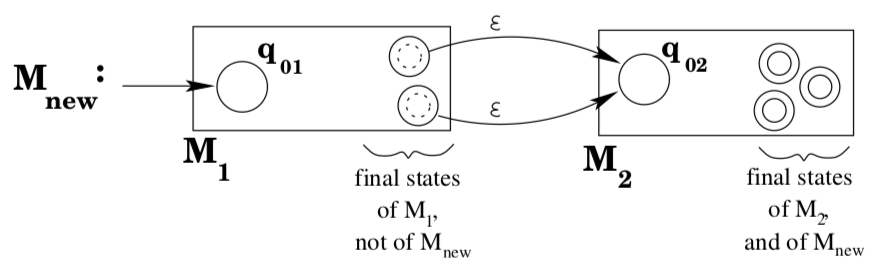
It should be fairly clear that this new machine accepts exactly those strings of the form xy where \(x \in L\left(r_{1}\right)\) and \(y \in L\left(r_{2}\right)\): first of all, any string of this form will be accepted because \(x \in L\left(r_{1}\right)\) implies there is a path that consumes \(x\) from \(q_{01}\) to a final state of \(M_{1} ;\) a \(\varepsilon\) -transition moves to \(q_{02} ;\) then \(y \in L\left(r_{2}\right)\) implies there is a path that consumes \(y\) from \(q_{02}\) to a final state of \(M_{2} ;\) and the final states of \(M_{2}\) are the final states of the new machine, so xy will be accepted. Conversely, suppose z is accepted by the new machine. Since the only final states of the new machine are in the old \(M_{2},\) and the only way to get into \(M_{2}\) is to take a \(\varepsilon\) -transition from a final state of \(M_{1},\) this means that \(z=x y\) where \(x\) takes the machine from its start state to a final state of \(M_{1},\) a \(\varepsilon\) -transition occurs, and then \(y\) takes the machine from \(q_{02}\) to a final state of \(M_{2}\) . Clearly, \(x \in L\left(r_{1}\right)\) and \(y \in L\left(r_{2}\right)\).
We leave the construction of an NFA that accepts \(L\left(r^{*}\right)\) from an \(\mathrm{NFA}\) that accepts L(r) as an exercise.
Theorem 3.4.
Every language that is accepted by a DFA or an NFA is generated by a regular expression.
Proving this result is actually fairly involved and not very illuminating. Before presenting a proof, we will give an illustrative example of how one might actually go about extracting a regular expression from an NFA or a DFA. You can go on to read the proof if you are interested.
Example 3.18.
Consider the DFA shown below:
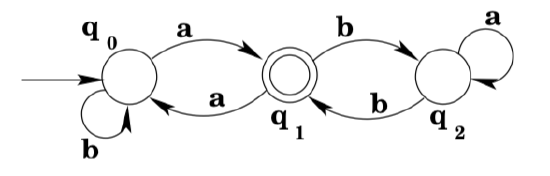
Note that there is a loop from state \(q_{2}\) back to state \(q_{2} :\) any number of a's will keep the machine in state \(q_{2},\) and so we label the transition with the regular expression \(a^{*} .\) We do the same thing to the transition labeled \(b\) from \(q_{0}\). (Note that the result is no longer a DFA, but that doesn’t concern us, we’re just interested in developing a regular expression.)
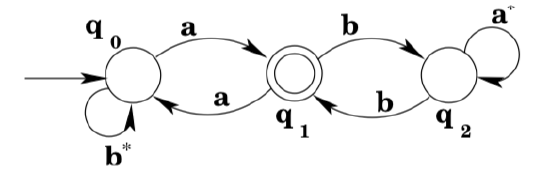
Next we note that there is in fact a loop from \(q_{1}\) to \(q_{1}\) via \(q_{0} .\) A regular expression that matches the strings that would move around the loop is \(a b^{*} a .\) So we add a transition labeled \(a b^{*} a\) from \(q_{1}\) to \(q_{1},\) and remove the now-irrelevant a-transition from \(q_{1}\) to \(q_{0}\). (It is irrelevant because it is not part of any other loop from \(q_{1}\) to \(q_{1}\).)
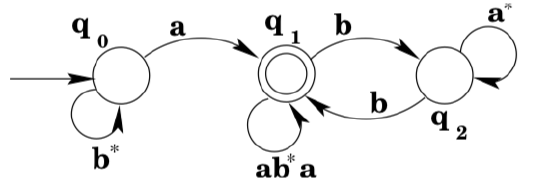
Next we note that there is also a loop from \(q_{1}\) to \(q_{1}\) via \(q_{2} .\) A regular expression that matches the strings that would move around the loop is \(b a^{*} b\). Since the transitions in the loop are the only transitions to or from \(q_{2},\) we simply remove \(q_{2}\) and replace it with a transition from \(q_{1}\) to \(q_{1}\).
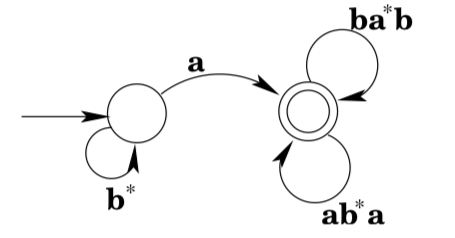
It is now clear from the diagram that strings of the form \(b^{*} a\) get you to state \(q_{1},\) and any number of repetitions of strings that match \(a b^{*} a\) or \(b a^{*} b\) will keep you there. So the machine accepts \(L\left(b^{*} a\left(a b^{*} a | b a^{*} b\right)^{*}\right)\).
Proof of Theorem 3.4. We prove that the language accepted by a DFA is regular. The proof for NFAs follows from the equivalence between DFAs and NFAs.
Suppose that \(M\) is a DFA, where \(M=\left(Q, \Sigma, q_{0}, \delta, F\right) .\) Let \(n\) be the number of states in \(M,\) and write \(Q=\left\{q_{0}, q_{1}, \ldots, q_{n-1}\right\}\). We want to consider computations in which M starts in some state \(q_{i},\) reads a string \(w\), and ends in state \(q_{k} .\) In such a computation, \(M\) might go through a series of intermediates states between \(q_{i}\) and \(q_{k} :\)
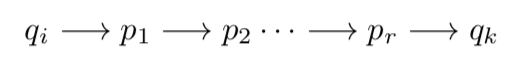
We are interested in computations in which all of the intermediate states—\(p_{1}, p_{2}, \ldots, p_{r}-\) are in the set \(\left\{q_{0}, q_{1}, \ldots, q_{j-1}\right\},\) for some number \(j .\) We define \(R_{i, j, k}\) to be the set of all strings \(w\) in \(\Sigma^{*}\) that are consumed by such a computation. That is, \(w \in R_{i, j, k}\) if and only if when \(M\) starts in state \(q_{i}\) and reads \(w,\) it ends in state \(q_{k},\) and all the intermediate states between \(q_{i}\) and \(q_{k}\) are in the set \(\left\{q_{0}, q_{1}, \ldots, q_{j-1}\right\} . \quad R_{i, j, k}\) is a language over \(\Sigma .\) We show that \(R_{i, j, k}\) for \(0 \leq i<n, 0 \leq j \leq n, 0 \leq k<n\).
Consider the language \(R_{i, 0, k} .\) For \(w \in R_{i, 0, k},\) the set of allowable intermediate states is empty. Since there can be no intermediate states, it follows that there can be at most one step in the computation that starts in state \(q_{i}\), reads \(w,\) and ends in state \(q_{k} .\) So \(,|w|\) can be at most one. This means that \(R_{i, 0, k}\) is finite, and hence is regular. (In fact, \(R_{i, 0, k}=\left\{a \in \Sigma | \delta\left(q_{i}, a\right)=q_{k}\right\}\) for \(i \neq k,\) and \(R_{i, 0, i}=\{\varepsilon\} \cup\left\{a \in \Sigma | \delta\left(q_{i}, a\right)=q_{i}\right\} .\) Note that in many cases, \(R_{i, 0, k}\) will be the empty set.
We now proceed by induction on \(j\) to show that \(R_{i, j, k}\) is regular for all \(i\) and \(k .\) We have proved the base case, \(j=0 .\) Suppose that \(0 \leq j<n\) we already know that \(R_{i, j, k}\) is regular for all \(i\) and all \(k .\) We need to show that \(R_{i, j+1, k}\) is regular for all \(i\) and \(k .\) In fact,
\(R_{i, j+1, k}=R_{i, j, k} \cup\left(R_{i, j, j} R_{j, j, j}^{*} R_{j, j, k}\right)\)
which is regular because \(R_{i, j, k}\) is regular for all \(i\) and \(k,\) and because the union, concatenation, and Kleene star of regular languages are regular. To see that the above equation holds, consider a string \(w \in \Sigma^{*}\). Now, \(w \in R_{i, j+1, k}\) if and only if when \(M\) starts in state \(q_{i}\) and reads \(w,\) it ends in state \(q_{k},\) with all intermediate states in the computation in the set \(\left\{q_{0}, q_{1}, \ldots, q_{j}\right\} .\) Consider such a computation. There are two cases: Either \(q_{j}\) occurs as an intermediate state in the computation, or it does not. If it does not occur, then all the intermediate states are in the set \(\left\{q_{0}, q_{1}, \ldots, q_{j-1}\right\},\) which means that in fact \(w \in R_{i, j, k}\) . If \(q_{j}\) does occur as an intermediate state in the computation, then we can break the com- putation into phases, by dividing it at each point where \(q_{j}\) occurs as an intermediate state. This breaks w into a concatenation \(w=x y_{1} y_{2} \cdots y_{r} z\). The string x is consumed in the first phase of the computation, during which M goes from state qi to the first occurrence of qj; since the intermediate states in this computation are in the set \(\left\{q_{0}, q_{1}, \ldots, q_{j-1}\right\}, x \in R_{i, j, j}\). The string z is consumed by the last phase of the computation, in which M goes from the final occurrence of \(q_{j}\) to \(q_{k},\) so that \(z \in R_{j, j, k}\). And each string \(y_{t}\) is consumed in a phase of the computation in which \(M\) goes from one occurrence of \(q_{j}\) to the next occurrence of \(q_{j},\) so that \(y_{r} \in R_{j, j, j} .\) This means that \(w=x y_{1} y_{2} \cdots y_{r} z \in R_{i, j, j} R_{j, j, j}^{*} R_{j, j, k}\).
We now know, in particular, that \(R_{0, n, k}\) is a regular language for all \(k .\) But \(R_{0, n, k}\) consists of all strings \(w \in \Sigma^{*}\) such that when \(M\) starts in state \(q_{0}\) and reads \(w,\) it ends in state \(q_{k}\) (with no restriction on the intermediate states in the computation, since every state of M is in the set \(\left\{q_{0}, q_{1}, \ldots, q_{n-1}\right\} ) .\) To finish the proof that \(L(M)\) is regular, it is only necessary to note that
\(L(M)=\bigcup_{q_{k} \in F} R_{0, n, k}\)
which is regular since it is a union of regular languages. This equation is true since a string w is in L(M) if and only if when M starts in state \(q_{0}\) and reads \(w,\) in ends in some accepting state \(q_{k} \in F .\) This is the same as saying \(w \in R_{0, n, k}\) for some \(k\) with \(q_{k} \in F\).
We have already seen that if two languages \(L_{1}\) and \(L_{2}\) are regular, then so are \(L_{1} \cup L_{2}, L_{1} L_{2},\) and \(L_{1}^{*}\) (and of course \(L_{2}^{*} ) .\) We have not yet seen, however, how the common set operations intersection and complementation affect regularity. Is the complement of a regular language regular? How about the intersection of two regular languages?
Both of these questions can be answered by thinking of regular languages in terms of their acceptance by DFAs. Let’s consider first the question of complementation. Suppose we have an arbitrary regular language L. We know there is a DFA M that accepts L. Pause a moment and try to think of a modification that you could make to M that would produce a new machine \(M^{\prime}\) that accepts \(\overline{L} \ldots .\) Okay, the obvious thing to try is to make \(M^{\prime}\) be a copy of \(M\) with all final states of \(M\) becoming non-final states of \(M^{\prime}\) and vice versa. This is in fact exactly right: \(M^{\prime}\) does in fact accept \(\overline{L}\). To verify this, consider an arbitrary string w. The transition functions for the two machines \(M\) and \(M^{\prime}\) are identical, so \(\delta^{*}\left(q_{0}, w\right)\) is the same state in both \(M\) and \(M^{\prime} ;\) if that state is accepting in \(M\) then it is non-accepting in \(M^{\prime},\) so if \(w\) is accepted by \(M\) it is not accepted by \(M^{\prime} ;\) if the state is non-accepting in M then it is accepting in M′, so if w is not accepted byM then it is accepted by M′. Thus M′ accepts exactly those strings that \(M\) does not, and hence accepts \(\overline{L}\).
It is worth pausing for a moment and looking at the above argument a bit longer. Would the argument have worked if we had looked at an arbitrary language L and an arbitrary NFA M that accepted L? That is, if we had built a new machine M′ in which the final and non-final states had been switched, would the new NFA M′ accept the complement of the language accepted by M? The answer is “not necessarily”. Remember that acceptance in an NFA is determined based on whether or not at least one of the states reached by a string is accepting. So any string w with the property that \(\partial^{*}\left(q_{0}, w\right)\) contains both accepting and non-accepting states of M would be accepted both by M and by M′.
Now let’s turn to the question of intersection. Given two regular languages L1 and L2, is \(L_{1} \cap L_{2}\) regular? Again, it is useful to think in terms of DFAs: given machines \(M_{1}\) and \(M_{2}\) that accept \(L_{1}\) and \(L_{2}\), can you use them to build a new machine that accepts \(L_{1} \cap L_{2}\)? The answer is yes, and the idea behind the construction bears some resemblance to that behind the NFA-to-DFA construction. We want a new machine where transitions reflect the transitions of both \(M_{1}\) and \(M_{2}\) simultaneously, and we want to accept a string w only if that those sequences of transitions lead to final states in both \(M_{1}\) and \(M_{2}\). So we associate the states of our new ma- chine M with pairs of states from \(M_{1}\) and \(M_{2} .\) For each state \(\left(q_{1}, q_{2}\right)\) in the new machine and input symbol a, define \(\delta\left(\left(q_{1}, q_{2}\right), a\right)\) to be the state \(\left(\delta_{1}\left(q_{1}, a\right), \delta_{2}\left(q_{2}, a\right)\right) .\) The start state \(q_{0}\) of \(M\) is \(\left(q_{01}, q_{02}\right),\) where \(q_{0 i}\) is the start state of \(M_{i} .\) The final states of \(M\) are the the states of the form \(\left(q_{f 1}, q_{f 2}\right)\) where \(q_{f 1}\) is an accepting state of \(M_{1}\) and \(q_{f 2}\) is an accepting state of \(M_{2} .\) You should convince yourself that \(M\) accepts a string \(x\) iff \(x\) is accepted by both \(M_{1}\) and \(M_{2} .\) The results of the previous section and the preceding discussion are summarized by the following theorem:
Theorem 3.5.
The intersection of two regular languages is a regular language.
The union of two regular languages is a regular language.
The concatenation of two regular languages is a regular language. The complement of a regular language is a regular language.
The Kleene closure of a regular language is a regular language.
Exercises
1. Give a DFA that accepts the intersection of the languages accepted by the machines shown below. (Suggestion: use the construction discussed in the chapter just before Theorem 3.5.)

- Complete the proof of Theorem 3.3 by showing how to modify a machine that accepts \(L(r)\) into a machine that accepts \(L\left(r^{*}\right)\).
- Using the construction described in Theorem 3.3, build an NFA that accepts \(L\left((a b | a)^{*}(b b)\right)\).
- Prove that the reverse of a regular language is regular.
- Show that for any DFA or NFA, there is an NFA with exactly one final state that accepts the same language.
- Suppose we change the model of NFAs to allow NFAs to have multiple start states. Show that for any “NFA” with multiple start states, there is an NFA with exactly one start state that accepts the same language.
- Suppose that \(M_{1}=\left(Q_{1}, \Sigma, q_{1}, \delta_{1}, F_{1}\right)\) and \(M_{2}=\left(Q_{2}, \Sigma, q_{2}, \delta_{2}, F_{2}\right)\) are DFAs over the alphabet \(\Sigma .\) It is possible to construct a DFA that accepts the langauge \(L\left(M_{1}\right) \cap L\left(M_{2}\right)\) in a single step. Define the DFA
\(M=\left(Q_{1} \times Q_{2}, \Sigma,\left(q_{1}, q_{2}\right), \delta, F_{1} \times F_{2}\right)\)
where \(\delta\) is the function from \(\left(Q_{1} \times Q_{2}\right) \times \Sigma\) to \(Q_{1} \times Q_{2}\) that is defined by: \(\delta((p 1, p 2), \sigma) )=\left(\delta_{1}\left(p_{1}, \sigma\right), \delta_{2}\left(p_{2}, \sigma\right)\right) .\) Convince yourself that this definition makes sense. (For example, note that states in M are pairs \(\left(p_{1}, p_{2}\right)\) of states, where \(p_{1} \in Q_{1}\) and \(p_{2} \in Q_{2},\) and note that the start state \(\left(q_{1}, q_{2}\right)\) in \(M\) is in fact a state in \(M . )\) Prove that \(L(M)=L\left(M_{1}\right) \cap L\left(M_{2}\right),\) and explain why this shows that the intersection of any two regular languages is regular. This proof—if you can get past the notation—is more direct than the one outlined above.