
4.3: Parsing and Parse Trees
- Page ID
- 6731

Suppose that G is a grammar for the language L. That is, L = L(G). The grammar G can be used to generate strings in the language L. In practice, though, we often start with a string which might or might not be in L, and the problem is to determine whether the string is in the language and, if so, how it can be generated by G. The goal is to find a derivation of the string, using the production rules of the grammar, or to show that no such derivation exists. This is known as parsing the string. When the string is a computer program or a sentence in a natural language, parsing the string is an essential step in determining its meaning.
As an example that we will use throughout this section, consider the language that consists of arithmetic expressions containing parentheses, the binary operators + and ∗, and the variables x, y, and z. Strings in this language include x, x+y∗z, and ((x+y)∗y)+z∗z. Here is a context-free grammar that generates this language:
\(E \longrightarrow E+E\)
\(E \longrightarrow E * E\)
\(E \longrightarrow(E)\)
\(E \longrightarrow x\)
\(E \longrightarrow y\)
\(E \longrightarrow z\)
Call the grammar described by these production rules \(G_{1} .\) The grammar \(G_{1}\) says that x, y, and z are expressions, and that you can make new expressions by adding two expressions, by multiplying two expressions, and by enclosing an expression in parentheses. (Later, we’ll look at other grammars for the same language ones that turn out to have certain advantages over \(G_{1} . )\)
Consider the string x + y ∗ z. To show that this string is in the language \(L\left(G_{1}\right),\) we can exhibit a derivation of the string from the start symbol \(E\) For example:
\(E \Longrightarrow E+E\)
\(\Longrightarrow E+E * E\)
\(\Longrightarrow E+y * E\)
\(\Longrightarrow x+y * E\)
\(\Longrightarrow x+y * z\)
This derivation shows that the string x+y∗z is in fact in L(G1). Now, this string has many other derivations. At each step in the derivation, there can be a lot of freedom about which rule in the grammar to apply next. Some of this freedom is clearly not very meaningful. When faced with the string E + E ∗ E in the above example, the order in which we replace the E’swith the variables x, y, and z doesn’t much matter. To cut out some of this meaningless freedom, we could agree that in each step of a derivation, the non-terminal symbol that is replaced is the leftmost non-terminal symbol in the string. A derivation in which this is true is called a left derivation. The following left derivation of the string x+y∗z uses the same production rules as the previous derivation, but it applies them in a different order:
\(E \Longrightarrow E+E\)
\(\Longrightarrow x+E\)
\(\Longrightarrow x+E * E\)
\(\Longrightarrow x+y * E\)
\(\Longrightarrow x+y * z\)
It shouldn’t be too hard to convince yourself that any string that has a derivation has a left derivation (which can be obtained by changing the order in which production rules are applied).
We have seen that the same string might have several different derivations. We might ask whether it can have several different left derivations. The answer is that it depends on the grammar. A context-free grammar \(G\) is said to be ambiguous if there is a string \(w \in L(G)\) such that \(w\) has more than one left derivation according to the grammar G.
Our example grammar \(G_{1}\) is ambiguous. In fact, in addition to the left derivation given above, the string x+y∗z has the alternative left derivation
\(\begin{aligned} E & \Longrightarrow E * E \\ & \Longrightarrow E+E * E \\ & \Longrightarrow x+E * E \\ & \Longrightarrow x+y * E \\ & \Longrightarrow x+y * z \end{aligned}\)
In this left derivation of the string x + y ∗ z, the first production rule that is applied is \(E \longrightarrow E * E .\) The first \(E\) on the right-hand side eventually yields “x + y” while the second yields “z”. In the previous left derivation, the first production rule that was applied was \(E \longrightarrow E+E,\) with the first \(E\) on the right yielding “x” and the second E yielding “y ∗ z”. If we think in terms of arithmetic expressions, the two left derivations lead to two different interpretations of the expression x + y ∗ z. In one interpretation, the x + yis a unit that is multiplied by z. In the second interpretation, the y ∗ z is a unit that is added to x. The second interpretation is the one that is correct according to the usual rules of arithmetic. However, the grammar allows either interpretation. The ambiguity of the grammar allows the string to be parsed in two essentially different ways, and only one of the parsings is consistent with the meaning of the string. Of course, the grammar for English is also ambiguous. In a famous example, it’s impossible to tell whether a “pretty girls’ camp” is meant to describe a pretty camp for girls or a camp for pretty girls.
When dealing with artificial languages such as programming languages, it's better to avoid ambiguity. The grammar \(G_{1}\) is perfectly correct in that it generates the correct set of strings, but in a practical situation where we are interested in the meaning of the strings, \(G_{1}\) is not the right grammar for the job. There are other grammars that generate the same language as \(G_{1} .\) Some of them are unambiguous grammars that better reflect the meaning of the strings in the language. For example, the language \(L\left(G_{1}\right)\) is also generated by the BNF grammar
E ::= T [ + T ] . . .
T ::= F [ ∗ F ] . . .
F ::= “(” E “)” | x | y | z
This grammar can be translated into a standard context-free grammar, which I will call \(G_{2} :\)
\(E \longrightarrow T A\)
\(A \longrightarrow+T A\)
\(A \longrightarrow \varepsilon\)
\(T \longrightarrow F B\)
\(B \longrightarrow * F B\)
\(B \longrightarrow \varepsilon\)
\(F \longrightarrow(E)\)
\(F \longrightarrow x\)
\(F \longrightarrow y\)
\(F \longrightarrow z\)
The language generated by \(G_{2}\) consists of all legal arithmetic expressions made up of parentheses, the operators + and −, and the variables x, y, and z. That is, \(L\left(G_{2}\right)=L\left(G_{1}\right) .\) However, \(G_{2}\) is an unambiguous grammar. Consider, for example, the string \(x+y * z .\) Using the grammar \(G_{2},\) the only left derivation for this string is:
\(E \Longrightarrow T A\)
\(\Longrightarrow F B A\)
\(\Longrightarrow x B A\)
\(\Longrightarrow x A\)
\(\Longrightarrow x+T A\)
\(\Longrightarrow x+F B A\)
\(\Longrightarrow x+y B A\)
\(\Longrightarrow x+y * F B A\)
\(\Longrightarrow x+y * z B A\)
\(\Longrightarrow x+y * z A\)
\(\Longrightarrow x+y * z\)
There is no choice about the first step in this derivation, since the only production rule with E on the left-hand side is \(E \longrightarrow T A\). ince the only production rule with E on the left-hand side is E −→ TA. Similarly, the second step is forced by the fact that there is only one rule for rewriting aT . In the third step, we must replace an F . There are four ways to rewriteF, but only one way to produce the x that begins the string x + y ∗ z, so we apply the rule \(F \longrightarrow x .\) Now, we have to decide what to do with the \(B\) in \(x B A .\) There two rules for rewriting \(B, B \longrightarrow * F B\) and \(B \longrightarrow \varepsilon\). However, the first of these rules introduces a non-terminal, ∗, which does not match the string we are trying to parse. So, the only choice is to apply the production rule \(B \longrightarrow \varepsilon\) . In the next step of the derivation, we must apply the rule \(A \longrightarrow+T A\) in order to account for the \(+\) in the string x + y ∗ z. Similarly, each of the remaining steps in the left derivation is forced.
The fact that \(G_{2}\) is an unambiguous grammar means that at each step in a left derivation for a string w, there is only one production rule that can be applied which will lead ultimately to a correct derivation of w. However, \(G_{2}\) actually satisfies a much stronger property: at each step in the left derivation of w, we can tell which production rule has to be applied by looking ahead at the next symbol in \(w .\) We say that \(G_{2}\) is an \(L L(1)\) grammar. (This notation means that we can read a string from Left to right and construct a Left derivation of the string by looking ahead at most 1 character in the string.) Given an LL(1) grammar for a language, it is fairly straightforward to write a computer program that can parse strings in that language. If the language is a programming language, then parsing is one of the essential steps in translating a computer program into machine language. LL(1) grammars and parsing programs that use them are often studied in courses in programming languages and the theory of compilers.
Not every unambiguous context-free grammar is an LL(1) grammar. Consider, for example, the following grammar, which I will call \(G_{3}\) :
\(E \longrightarrow E+T\)
\(E \longrightarrow T\)
\(T \longrightarrow T * F\)
\(T \longrightarrow F\)
\(F \longrightarrow(E)\)
\(F \longrightarrow x\)
\(F \longrightarrow y\)
\(F \longrightarrow z\)
This grammar generates the same language as \(G_{1}\) and \(G_{2},\) and it is unambiguous. However, it is not possible to construct a left derivation for a string according to the grammar \(G_{3}\) by looking ahead one character in the string at each step. The first step in any left derivation must be either \(E \Longrightarrow E+T\) or \(E \Rightarrow T .\) But how can we decide which of these is the correct first step? Consider the strings (x+y)∗z and (x+y)∗z+z∗x, which are both in the language \(L\left(G_{3}\right) .\) For the string \((x+y) * z,\) the first step in a left derivation must be \(E \Longrightarrow T,\) while the first step in a left derivation of \((x+y) * z+z * x\) must be \(E \Longrightarrow E+T .\) However, the first seven characters of the strings are identical, so clearly looking even seven characters ahead is not enough to tell us which production rule to apply. In fact, similar examples show that looking ahead any given finite number of characters is not enough.
However, there is an alternative parsing procedure that will work for \(G_{3}\), This alternative method of parsing a string produces a right derivationof the string, that is, a derivation in which at each step, the non-terminal symbol that is replaced is the rightmost non-terminal symbol in the string. Here, for example, is a right derivation of the string (x + y) ∗ z according to the grammar \(G_{3} :\)
\(E \Longrightarrow T\)
\(\Longrightarrow T * F\)
\(\Longrightarrow T * z\)
\(\Longrightarrow F * z\)
\(\Longrightarrow(E) * z\)
\(\Longrightarrow(E+T) * z\)
\(\Longrightarrow(E+T) * z\)
\(\Longrightarrow(F+F) * z\)
\(\Longrightarrow(F+y) * z\)
\(\Longrightarrow(x+y) * z\)
The parsing method that produces this right derivation produces it from “bottom to top.” That is, it begins with the string (x + y) ∗ z and works backward to the start symbol E, generating the steps of the right derivation in reverse order. The method works because \(G_{3}\) is what is called an \(L R(1)\) grammar. That is, roughly, it is possible to read a string from Left to right and produce a Right derivation of the string, by looking ahead at most 1 symbol at each step. Although LL(1) grammars are easier for people to work with, LR(1) grammars turn out to be very suitable for machine processing, and they are used as the basis for the parsing process in many compilers.
LR(1) parsing uses a shift/reduce algorithm. Imagine a cursor or current position that moves through the string that is being parsed. We can visualize the cursor as a vertical bar, so for the string (x + y) ∗ z, we start with the configuration |(x + y) ∗ z. A shift operation simply moves the cursor one symbol to the right. For example, a shift operation would convert |(x + y) ∗ z to (|x + y) ∗ z, and a second shift operation would convert that to (x| + y) ∗ z. In a reduce operation, one or more symbols immediately to the left of the cursor are recognized as the right-hand side of one of the production rules in the grammar. These symbols are removed and replaced by the left-hand side of the production rule. For example, in the configuration (x| + y) ∗ z, the x to the left of the cursor is the right-hand side of the production rule \(F \longrightarrow x,\) so we can apply a reduce operation corresponds to the last step in the right derivation of the string, \((F+y) * z \Longrightarrow(x+y) * z .\) Now the \(F\) can be recognized as the right-hand side of the production rule \(T \longrightarrow F,\) so we can replace the \(F\) with \(T,\) giving (T|+y)∗z. This corresponds to the next-to-last step in the right derivation, \((T+y) * z \Longrightarrow(F+y) * z\).
At this point, we have the configuration (T | + y) ∗ z. The T could be the right-hand side of the production rule \(E \longrightarrow T .\) However, it could also conceivably come from the rule \(T \longrightarrow T * F .\) How do we know whether to reducetheT toEatthispointortowaitfora∗F tocomealongsothatwe can reduce T ∗ F ? We can decide by looking ahead at the next character after the cursor. Since this character is a + rather than a ∗, we should choose the reduce operation that replaces T with E, giving (E| + y) ∗ z. What makes \(G_{3}\) an LR(1) grammar is the fact that we can always decide what operation to apply by looking ahead at most one symbol past the cursor.
After a few more shift and reduce operations, the configuration becomes (E)| ∗ z, which we can reduce to T | ∗ z by applying the production rules \(F \longrightarrow(E)\) and \(T \longrightarrow F .\) Now, faced with \(T | * z,\) we must once again decide between a shift operation and a reduce operation that applies the rule \(E \longrightarrow T .\) In this case, since the next character is a * rather than a \(+\) we apply the shift operation, giving T ∗|z. From there we get, in succession,T ∗ z|, T ∗ F |, T |, and finally E|. At this point, we have reduced the entire string (x + y) ∗ z to the start symbol of the grammar. The very last step, the reduction of T to E corresponds to the first step of the right derivation, \(E \Longrightarrow T\).
In summary, LR(1) parsing transforms a string into the start symbol of the grammar by a sequence of shift and reduce operations. Each reduce operation corresponds to a step in a right derivation of the string, and these steps are generated in reverse order. Because the steps in the derivation are generated from “bottom to top,” LR(1) parsing is a type of bottom-up parsing. LL(1) parsing, on the other hand, generates the steps in a left derivation from “top to bottom” and so is a type of top-down parsing.
Although the language generated by a context-free grammar is defined in terms of derivations, there is another way of presenting the generation of a string that is often more useful. A parse tree displays the generation of a string from the start symbol of a grammar as a two dimensional diagram. Here are two parse trees that show two derivations of the string x+y*z ac- cording to the grammar \(G_{1}\), which was given at the beginning of this section:
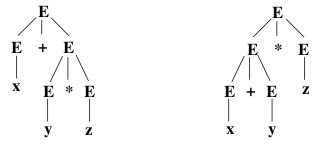
A parse tree is made up of terminal and non-terminal symbols, connected by lines. The start symbol is at the top, or “root,” of the tree. Terminal symbols are at the lowest level, or “leaves,” of the tree. (For some reason, computer scientists traditionally draw trees with leaves at the bottom and root at the top.) A production rule \(A \longrightarrow w\) is represented in a parse tree by the symbol A lying above all the symbols in w, with a line joining A to each of the symbols in w. For example, in the left parse tree above, the root, E, is connected to the symbols E, +, and E, and this corresponds to an application of the production rule \(E \longrightarrow E+E\).It is customary to draw a parse tree with the string of non-terminals in a row across the bottom, and with the rest of the tree built on top of that base. Thus, the two parse trees shown above might be drawn as:
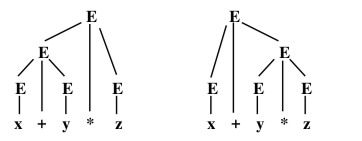
Given any derivation of a string, it is possible to construct a parse tree that shows each of the steps in that derivation. However, two different derivations can give rise to the same parse tree, since the parse tree does not show the order in which production rules are applied. For example, the parse tree on the left, above, does not show whether the production rule \(E \longrightarrow x\) is applied before or after the production rule \(E \longrightarrow y .\) However, if we restrict our attention to left derivations, then we find that each parse tree corresponds to a unique left derivation and vice versa. I will state this fact as a theorem, without proof. A similar result holds for right derivations.
Theorem 4.5.
Let G be a context-free grammar. There is a one-to-one correspondence between parse trees and left derivations based on the grammar G.
Based on this theorem, we can say that a context-free grammar G is ambiguous if and only if there is a string \(w \in L(G)\) which has two parse trees.
Exercises
1. Show that each of the following grammars is ambiguous by finding a string that has two left derivations according to the grammar:
a) \(S \longrightarrow S S\)
\(S \longrightarrow a S b\)
\(S \longrightarrow b S a\)
\(S \longrightarrow \varepsilon\)
b) \(S \longrightarrow A S b\)
\(S \longrightarrow \varepsilon\)
\(A \longrightarrow a A\)
\(A \longrightarrow a\)
2. Consider the string z+(x+y)∗x. Find a left derivation of this string according to each of the grammars \(G_{1}, G_{2},\) and \(G_{3},\) as given in this section.
- Draw a parse tree for the string (x+y)∗z∗x according to each of the grammars \(G_{1}, G_{2},\) and \(G_{3},\) as given in this section.
- Draw three different parse trees for the string ababbaab based on the grammar given in part a) of exercise 1.
- Suppose that the string abbcabac has the following parse tree, according to some grammar G:
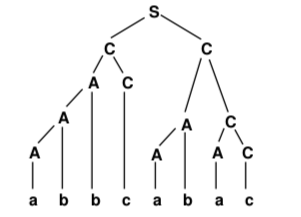
a) List five production rules that must be rules in the grammar G, given that this is a valid parse tree.
b) Give a left derivation for the string abbcabac according to the grammar G.
c) Give a right derivation for the string abbcabac according to the grammar G.
6. Show the full sequence of shift and reduce operations that are used in the LR(1) parsing of the string x + (y) ∗ z according to the grammar G3, and give the corresponding right derivation of the string.
7. This section showed how to use LL(1) and LR(1) parsing to find a derivation of a string in the language L(G) generated by some grammar G. How is it possible to use LL(1) or LR(1) parsing to determine for an arbitrary string wwhether w ∈ L(G) ? Give an example.