
4.4: Pushdown Automata
- Page ID
- 6732

In the previous chapter, we saw that there is a neat correspondence between regular expressions and finite automata. That is, a language is generated by a regular expression if and only if that language is accepted by a finite automaton. Finite automata come in two types, deterministic and nonde- terministic, but the two types of finite automata are equivalent in terms of their ability to recognize languages. So, the class of regular languages can be defined in two ways: either as the set of languages that can be generated by regular expressions or as the set of languages that can be recognized by finite automata (either deterministic or nondeterministic).
In this chapter, we have introduced the class of context-free languages, and we have considered how context-free grammars can be used to generate context-free languages. You might wonder whether there is any type of automaton that can be used to recognize context-free languages. In fact, there is: The abstract machines known as pushdown automata can be used to define context-free languages. That is, a language is context-free if and only if there is a pushdown automaton that accepts that language.
A pushdown automaton is essentially a finite automaton with an auxiliary data structure known as a stack. A stack consists of a finite list of symbols. Symbols can be added to and removed from the list, but only at one end of the list. The end of the list where items can be added and removed is called the top of the stack. The list is usually visualized as a vertical “stack” of symbols, with items being added and removed at the top. Adding a symbol at the top of the stack is referred to as pushing a symbol onto the stack, and removing a symbol is referred to as popping an item from the stack. During each step of its computation, a pushdown automaton is capable of doing several push and pop operations on its stack (this in addition to possibly reading a symbol from the input string that is being processed by the automaton).
Before giving a formal definition of pushdown automata, we will look at how they can be represented by transition diagrams. A diagram of a pushdown automaton is similar to a diagram for an NFA, except that each transition in the diagram can involve stack operations. We will use a label of the form σ, x/y on a transition to mean that the automaton consumes σfrom its input string, pops x from the stack, and pushes y onto the stack.σ can be either ε or a single symbol. x and y are strings, possibly empty. (When a string \(x=a_{1} a_{2} \dots a_{k}\) is pushed onto a stack, the symbols are pushed in the order \(a_{k}, \ldots, a_{1},\) so that \(a_{1}\) ends up on the top of the stack; for \(y=b_{1} b_{2} \ldots b_{n}\) to be popped from the stack, \(b_{1}\) must be the top symbol on the stack, followed by \(b_{2},\) etc.) For example, consider the following transition diagram for a pushdown automaton:
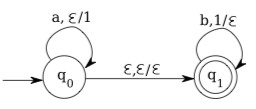
This pushdown automaton has start state q0 and one accepting state, \(q_{1} .\) It can read strings over the alphabet \(\Sigma=\{a, b\} .\) The transition from \(q_{0}\) to \(q_{0},\) labeled with \(a, \varepsilon / 1,\) means that if the machine is in state \(q_{0},\) then it can read an a from its input string, pop nothing from the stack, push 1 onto the stack, and remain in state \(q_{0} .\) Similarly, the transition from \(q_{1}\) to \(q_{1}\) means that if the machine is in state \(q_{1},\) it can read a \(b\) from its input string, pop a 1 from the stack, and push nothing onto the stack. Finally, the transition from state \(q_{0}\) to \(q_{1},\) labeled with \(\varepsilon, \varepsilon / \varepsilon,\) means that the machine can transition from state \(q_{0}\) to state \(q_{1}\) without reading, pushing, or popping anything.
Note that the automation can follow transition b, 1/ε only if the next symbol in the input string is b and if 1 is on the top of the stack. When it makes the transition, it consumes the b from input and pops the 1 from the stack. Since in this case, the automaton pushes ε (that is, no symbols at all) onto the stack, the net change in the stack is simply to pop the 1.
We have to say what it means for this pushdown automaton to accept a string. For \(w \in\{a, b\}^{*},\) we say that the pushdown automaton accepts \(w\) if and only if it is possible for the machine to start in its start state, \(q_{0},\) read all of \(w,\) and finish in the accepting state, \(q_{1},\) with an empty stack. Note in particular that it is not enough for the machine to finish in an accepting state—it must also empty the stack.
It’s not difficult to see that with this definition, the language accepted by our pushdown automaton is \(\left\{a^{n} b^{n} | n \in \mathbb{N}\right\} .\) In fact, given the string \(w=a^{k} b^{k},\) the machine can process this string by following the transition from \(q_{0}\) to \(q_{0} k\) times. This will consume all the \(a^{\prime} s\) and will push \(k\) 1's onto the stack. The machine can then jump to state \(q_{1}\) and follow the transition from \(q_{1}\) to \(q_{1}\) k times. Each time it does so, it consumes one b from the input and pops one 1 from the stack. At the end, the input has been completely consumed and the stack is empty. So, the string wis accepted by the automaton. Conversely, this pushdown automaton only accepts strings of the form \(a^{k} b^{k},\) since the only way that the automaton can finish in the accepting state, \(q_{1},\) is to follow the transition from \(q_{0}\) to \(q_{0}\) some number of times, reading a’s as it does so, then jump at some point to \(q_{1},\) and then follow the transition from \(q_{1}\) to \(q_{1}\) some number of times, reading b’s as it does so. This means that an accepted string must be of the form \(a^{k} b^{\ell}\) for some \(k, \ell \in \mathbb{N} .\) However, in reading this string, the automaton pushes k 1’s onto the stack and pops l 1’s from the stack. For the stack to end up empty, l must equal k, which means that in fact the string is of the form \(a^{k} b^{k},\) as claimed.
Here are two more examples. These pushdown automata use the capa- bility to push or pop more than one symbol at a time:
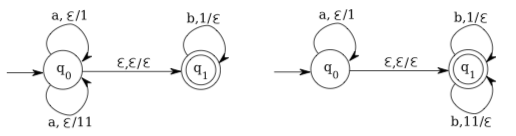
The atomaton on the left accepts the language \(\left\{a^{n} b^{m} | n \leq m \leq 2 * n\right\}\) Each time it reads an a, it pushes either one or two 1’s onto the stack, so that after reading n a’s, the number of 1’s on the stack is between n and 2∗n. If the machine then jumps to state \(q_{1}\), it must be able to read exactly enough b’s to empty the stack, so any string accepted by this machine must be of the form \(a^{n} b^{m}\) with \(n \leq m \leq 2 * n .\) Conversely, any such string can be accepted by the machine. Similarly, the automaton on the right above accepts the language \(\left\{a^{n} b^{m} | n / 2 \leq m \leq n\right\} .\) To accept \(a^{n} b^{m},\) it must push n 1’a onto the stack and then pop one or two 1’s for each b; this can succeed only if the number of b’s is between n/2 and n.
Note that an NFA can be considered to be a pushdown automaton that does not make any use of its stack. This means that any language that can be accepted by an NFA (that is, any regular language) can be accepted by a pushdown automaton. Since the language \(\left\{a^{n} b^{n} | n \in \mathbb{N}\right\}\) is context-free but
not regular, and since it is accepted by the above pushdown automaton, we see that pushdown automata are capable of recognizing context-free languages that are not regular and so that pushdown automata are strictly more powerful than finite automata.
Although it is not particularly illuminating, we can give a formal definition of pushdown automaton. The definition does at least make it clear that the set of symbols that can be used on the stack is not necessarily the same as the set of symbols that can be used as input.
Definition 4.4.
A pushdown automaton M is specified by six components \(M=\left(Q, \Sigma, \Lambda, q_{0}, \partial, F\right)\) where
- Q is a finite set of states.
- Σ is an alphabet. Σ is the input alphabet for M.
- Λ is an alphabet. Λ is the stack alphabet for M.
- \(q_{0} \in Q\) is the start state of \(M\)
- \(F \subseteq Q\) is the set of final or accepting states in \(M\)
- ∂ is the set of transitions in M. ∂ can be taken to be a finite subset of the set \(\left(Q \times(\Sigma \cup\{\varepsilon\}) \times \Lambda^{*}\right) \times\left(Q \times \Lambda^{*}\right) .\) An element \(\left(\left(q_{1}, \sigma, x\right),\left(q_{2}, y\right)\right)\) of ∂ represents a transition from state \(q_{1}\) to state \(q_{2}\) in which \(M\) reads σ from its input string, pops x from the stack, and pushes y onto the stack.
We can then define the language L(M ) accepted by a pushdown automaton \(M=\left(Q, \Sigma, \Lambda, q_{0}, \partial, F\right)\) to be the set \(L(M)=\left\{w \in \Sigma^{*} | \text { starting from }\right.\) state \(q_{0},\) it is possible for \(M\) to read all of \(w\) and finish in some state in \(F\) with an empty stack}. With this definition, the class of languages accepted by pushdown automata is the same as the class of languages generated by context-free grammars.
theorem 4.6
Let Σ be an alphabet, and let L be a language over L. Then L is context-free if and only if there is a pushdown automaton whose input alphabet is Σ such that L = L(M).
We will not prove this theorem, but we do discuss how one direction can be proved. Suppose that L is a context-free language over an alphabet \Sigma. Let \(G=(V, \Sigma, P, S)\) be a context-free grammar for \(L .\) Then we can construct a pushdown automaton M that accepts L. In fact, we can take \(M=\left(Q, \Sigma, \Lambda, q_{0}, \partial, F\right)\) where \(Q=\left\{q_{0}, q_{1}\right\}, \Lambda=\Sigma \cup V, F=\left\{q_{1}\right\},\) and \(\partial\) M = (Q,Σ,Λ,q0,∂,F) where Q = {q0,q1}, Λ = Σ∪V, F = {q1}, and ∂contains transitions of the forms.
1. \(\left(\left(q_{0}, \varepsilon, \varepsilon\right),\left(q_{1}, S\right)\right)\)
2. \(\left(\left(q_{1}, \sigma, \sigma\right),\left(q_{1}, \varepsilon\right)\right),\) for \(\sigma \in \Sigma ;\) and
3.\(\left(\left(q_{1}, \varepsilon, A\right),\left(q_{1}, x\right)\right),\) for each production \(A \longrightarrow x\) in \(G\)
The transition \(\left(\left(q_{0}, \varepsilon, \varepsilon\right),\left(q_{1}, S\right)\right)\) lets \(M\) move from the start state \(q_{0}\) to the accepting state q1 while reading no input and pushing S onto the stack. This is the only possible first move by M.
A transition of the form \(\left(\left(q_{1}, \sigma, \sigma\right),\left(q_{1}, \varepsilon\right)\right),\) for \(\sigma \in \Sigma\) allows M to readσ from its input string, provided there is a σ on the top of the stack. Note that if σ is at the top of the stack, then this transition is only transition that applies. Effectively, any terminal symbol that appears at the top of the stack must be matched by the same symbol in the input string, and the transition rule allows M to consume the symbol from the input string and remove it from the stack at the same time.
A transition of the third form, \(\left(\left(q_{1}, \varepsilon, A\right),\left(q_{1}, x\right)\right)\) can be applied if and only if the non-terminal symbol A is at the top of the stack. M consumes no input when this rule is applied, but A is replaced on the top of the stack by the string on the right-hand side of the production rule \(A \longrightarrow x .\) Since the grammar G can contain several production rules that have A as their left-hand side, there can be several transition rules in M that apply when A is on the top of the stack. This is the only source of nondeterminism inM; note that is also the source of nondeterminism in G.
The proof that L(M) = L(G) follows from the fact that a computation of \(M\) that accepts a string \(w \in \Sigma^{*}\) corresponds in a natural way to a left derivation of w from G’s start symbol, S. Instead of giving a proof of this fact, we look at an example. Consider the following context-free grammar:
\(S \longrightarrow A B\)
\(A \longrightarrow a A b\)
\(A \longrightarrow \varepsilon\)
\(B \longrightarrow b B\)
\(B \longrightarrow b\)
This grammar generates the language \(\left\{a^{n} b^{m} | m>n\right\} .\) The pushdown automaton constructed from this grammar by the procedure given above has the following set of transition rules:
\(\left(\left(q_{0}, \varepsilon, \varepsilon\right),\left(q_{1}, S\right)\right)\)
\(\left(\left(q_{1}, a, a\right),\left(q_{1}, \varepsilon\right)\right)\)
\(\left(\left(q_{1}, b, b\right),\left(q_{1}, \varepsilon\right)\right)\)
\(\left(\left(q_{1}, \varepsilon, S\right),\left(q_{1}, A B\right)\right)\)
\(\left(\left(q_{1}, \varepsilon, S\right),\left(q_{1}, a A b\right)\right)\)
\(\left(\left(q_{1}, \varepsilon, A\right),\left(q_{1}, a B\right)\right)\)
\(\left(\left(q_{1}, \varepsilon, B\right),\left(q_{1}, b B\right)\right)\)
\(\left(\left(q_{1}, \varepsilon, B\right),\left(q_{1}, b\right)\right)\)
Suppose that the automaton is run on the input aabbbb. We can trace the sequence of transitions that are applied in a computation that accepts this input, and we can compare that computation to a left derivation of the string:
|
Transition |
Input Consumed |
Stack |
Derivation |
| \(\left(\left(q_{0}, \varepsilon, \varepsilon\right),\left(q_{1}, S\right)\right)\) | S | ||
| \(\left(\left(q_{1}, \varepsilon, S\right),\left(q_{1}, A B\right)\right)\) | AB | \(S \Longrightarrow A B\) | |
| \(\left(\left(q_{1}, \varepsilon, A\right),\left(q_{1}, a A b\right)\right)\) |
aAbB |
\(\Longrightarrow a A b B\) | |
| \(\left(\left(q_{1}, a, a\right),\left(q_{1}, \varepsilon\right)\right)\) | a |
AbB |
|
| \(\left(\left(q_{1}, \varepsilon, A\right),\left(q_{1}, a A b\right)\right)\) | a |
aAbbB |
\(\Longrightarrow a a A b b B\) |
| \(\left(\left(q_{1}, a, a\right),\left(q_{1}, \varepsilon\right)\right)\) | aa |
AbbB |
|
| \(\left(\left(q_{1}, \varepsilon, A\right),\left(q_{1}, \varepsilon\right)\right)\) | aa |
bbB |
\(\Longrightarrow a a b b B\) |
| \(\left(\left(q_{1}, b, b\right),\left(q_{1}, \varepsilon\right)\right)\) | aab |
bB |
|
| \(\left(\left(q_{1}, b, b\right),\left(q_{1}, \varepsilon\right)\right)\) | aabb |
B |
|
| \(\left(\left(q_{1}, \varepsilon, B\right),\left(q_{1}, b B\right)\right)\) | aabb |
bB |
\(\Longrightarrow a a b b b B\) |
| \(\left(\left(q_{1}, b\right),\left(q_{1}, b, \varepsilon\right)\right)\) | aabbb | B | |
| \(\left(\left(q_{1}, \varepsilon, B\right),\left(q_{1}, b\right)\right)\) | aabbb |
b |
\(\Longrightarrow a a b b b b\) |
| \(\left(\left(q_{1}, b, b\right),\left(q_{1}, \varepsilon\right)\right)\) | aabbbb |
Note that at all times during this computation, the concatenation of the input that has been consumed so far with the contents of the stack is equal to one of the strings in the left derivation. Application of a rule of the form \(\left(\left(q_{1}, \sigma, \sigma\right),\left(q_{1}, \varepsilon\right)\right)\) has the effect of removing one terminal symbol from the “Stack” column to the “Input Consumed” column. Application of a rule of the form \(\left(\left(q_{1}, \varepsilon, A\right),\left(q_{1}, x\right)\right)\) has the effect of applying the next step in the left derivation to the non-terminal symbol on the top of the stack. (In the “Stack” column, the pushdown automaton’s stack is shown with its top on the left.) In the end, the entire input string has been consumed and the stack is empty, which means that the string has been accepted by the pushdown automaton. It should be easy to see that for any context free grammar G, the same correspondence will always hold between left derivations and computations performed by the pushdown automaton constructed from G.
The computation of a pushdown automaton can involve nondeterminism. That is, at some point in the computation, there might be more than one transition rule that apply. When this is not the case—that is, when there is no circumstance in which two different transition rules apply— then we say that the pushdown automaton is deterministic. Note that a deterministic pushdown automaton can have transition rules of the form \(\left(\left(q_{i}, \varepsilon, x\right),\left(q_{j}, y\right)\right)\) (or even \(\left(\left(q_{i}, \varepsilon, \varepsilon\right),\left(q_{j}, y\right)\right)\) if that is the only transition from state \(q_{i} )\). Note also that is is possible for a deterministic pushdown automaton to get “stuck”; that is, it is possible that no rules apply in some circumstances even though the input has not been completely consumed or the stack is not empty. If a deterministic pushdown automaton gets stuck while reading a string x, then x is not accepted by the automaton.
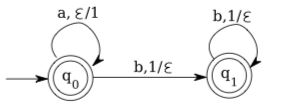
The automaton given at the beginning of this section, which accepts the language \(\left\{a^{n} b^{n} | n \in \mathbb{N}\right\},\) is not deterministic. However, it is easy to construct a deterministic pushdown automaton for this language:
However, consider the language \(\left\{w w^{R} | w \in\{a, b\}^{*}\right\} .\) Here is a pushdown automaton that accepts this language:
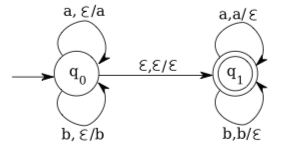
In state \(q_{0},\) this machine copies the first part of its input string onto the stack. In state \(q_{1},\) it tries to match the remainder of the input against the contents of the stack. In order for this to work, it must “guess” where the middle of the string occurs by following the transition from state \(q_{0}\) to state \(q_{1}\). In this case, it is by no means clear that it is possible to construct a deterministic pushdown automaton that accepts the same language.
At this point, it might be tempting to define a deterministic context-free language as one for which there exists a deterministic pushdown automaton which accepts that language. However, there is a technical problem with this definition: we need to make it possible for the pushdown automaton to detect the end of the input string. Consider the language \(\{w | w \in\)\(\{a, b\}^{*} \wedge n_{a}(w)=n_{b}(w) \},\) which consists of strings over the alphabet \(\{a, b\}\) in which the number of a’s is equal to the number of b’s. This language is accepted by the following pushdown automaton:
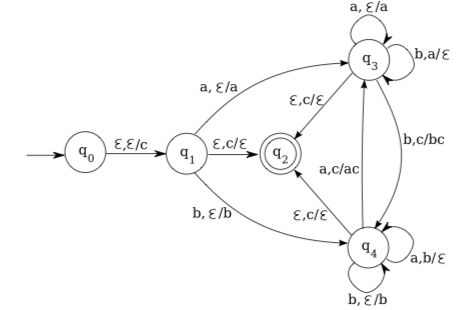
In this automaton, a c is first pushed onto the stack, and it remains on the bottom of the stack until the computation ends. During the process of reading an input string, if the machine is in state \(q_{3},\) then the number of a’s that have been read is greater than or equal to the number of b’s that have been read, and the stack contains (copies of) the excess a’s that have been read. Similarly, if the machine is in state \(q_{4} \), then the number of b’s that have been read is greater than or equal to the number of a’s that have been read, and the stack contains (copies of) the excess b’s that have been read. As the computation proceeds, if the stack contains nothing but a c, then the number of a’s that have been consumed by the machine is equal to the number of b’s that have been consumed; in such cases, the machine can pop the c from the stack—leaving the stack empty—and jump to state \(q_{2} .\) If the entire string has been read at that time, then the string is accepted. This involves nondeterminism because the automaton has to "guess" when to jump to state \(q_{2} ;\) it has no way of knowing whether it has actually reached the end of the string.
Although this pushdown automaton is not deterministic, we can modify it easily to get a deterministic pushdown automaton that accepts a closely related language. We just have to add a special end-of-string symbol to the language. We use the symbol $ for this purpose. The following deterministic automaton accepts the language \(\left\{w \mathfrak{S} | w \in\{a, b\}^{*} \wedge n_{a}(w)=n_{b}(w)\right\} :\)
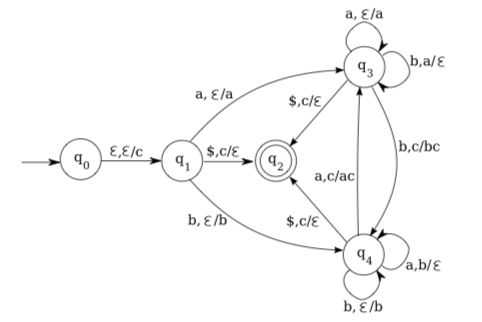
In this modified automaton, it is only possible for the machine to reach the accepting state q2 by reading the end-of-string symbol at a time when the number of a’s that have been consumed is equal to the number of b’s. Taking our cue from this example, we define what it means for a language to be deterministic context-free as follows:
Definition 4.5.
Let L be a language over an alphabet Σ, and let $ be a symbol that is not in Σ. We say that L is a deterministic context-free language if there is a deterministic pushdown automaton that accepts the language \(L \$\) (which is equal to \(\{w \$ | w \in L\} )\).
There are context-free languages that are not deterministic context-free. This means that for pushdown automata, nondeterminism adds real power. This contrasts with the case of finite automata, where deterministic finite automata and nondeterministic finite automata are equivalent in power in the sense that they accept the same class of languages.
A deterministic context-free language can be parsed efficiently. LL(1) parsing and LR(1) parsing can both be defined in terms of deterministic pushdown automata, although we have not pursued that approach here.
Exercises
1. Identify the context-free language that is accepted by each of the following pushdown automata. Explain your answers.
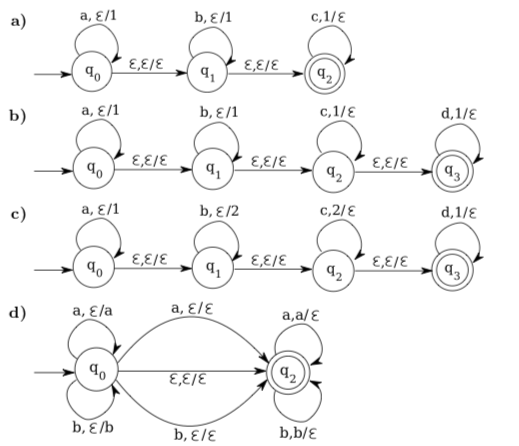
2. Let B be the language over the alphabet {(,)} that consists of strings of parentheses that are balanced in the sense that every left parenthesis has a matching right parenthesis. Examples include (), (())(), ((())())()(()), and the empty string. Find a deterministic pushdown automaton with a single state that accepts the language B. Explain how your automaton works, and explain the circumstances in which it will fail to accept a given string of parentheses.
3. Suppose that L is language over an alphabet Σ. Suppose that there is a deterministic pushdown automaton that accepts L. Show that L is deterministic context-free. That is, show how to construct a deterministic pushdown automaton that accepts the language L$. (Assume that the symbol $ is not in Σ.)
4. Find a deterministic pushdown automaton that accepts the language \(\left\{w c w^{R} | w \in\right.\) \(\{a, b\}^{*} \}\)
5. Show that the language \(\left\{a^{n} b^{m} | n \neq m\right\}\) is deterministic context-free.
6. Show that the language \(L=\left\{w \in\{a, b\}^{*} | n_{a}(w)>n_{b}(w)\right\}\) is deterministic context-free.
7. Let \(M=\left(Q, \Sigma, \Lambda, q_{0}, \partial, F\right)\) be a pushdown automaton. Define \(L^{\prime}(M)\) to be the language \(L^{\prime}(M)=\left\{w \in \Sigma^{*} | \text { it is possible for } M \text { to start in state } q_{0}, \text { read }\right.\) all of w, and end in an accepting state}. L′(M) differs from L(M) in that for \(w \in L^{\prime}(M),\) we do not require that the stack be empty at the end of the computation.
a) Show that there is a pushdown automaton M ′ such that L(M ′ ) =L′(M).
b) Show that a language L is context-free if and only if there is a pushdown automaton M such that L = L′(M).
c) Identify the language L′(M) for each of the automata in Exercise 1.
8. Let L be a regular language over an alphabet Σ, and let K be a context-free language over the same alphabet. Let \(M=\left(Q, \Sigma, q_{0}, \delta, F\right)\) be a DFA that accepts L, and let \(N=\left(P, \Sigma, \Lambda, p_{0}, \partial, E\right) )\) be a pushdown automaton that accepts K. Show that the language \(L \cap K\) is context-free by constructing a pushdown automaton that accepts \(L \cap K\). The pushdown automaton can be constructed as a “cross product” of M and N in which the set of states is Q × P . The construction is analogous to the proof that the intersection of two regular languages is regular, as outlined in Exercise 3.6.7.