
0.32: ELF
- Page ID
- 81556
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)ELF
ELF is an extremely flexible format for representing binary code in a system. By following the ELF standard you can represent a kernel binary just as easily as a normal executable or a system library. The same tools can be used to inspect and operate on all ELF files and developers who understand the ELF file format can translate their skills to most modern UNIX systems.
ELF extends on COFF and gives the header sufficient flexibility to define an arbitrary number of sections, each with its own properties. This facilitates easier dynamic linking and debugging.
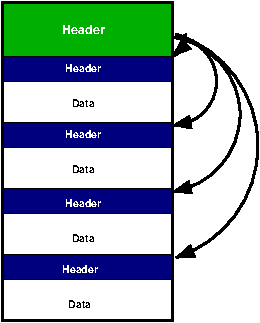
ELF File Header
Overall, the file has a file header which describes the file in general and then has pointers to each of the individual sections that make up the file. Example 8.1, “The ELF Header” shows the description as given in the API documentation for ELF32 (the 32-bit form of ELF). This is the layout of the C structure which defines a ELF header.
1 typedef struct {
unsigned char e_ident[EI_NIDENT];
Elf32_Half e_type;
Elf32_Half e_machine;
5 Elf32_Word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
10 Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
15 Elf32_Half e_shstrndx;
} Elf32_Ehdr;
1 $ readelf --header /bin/ls ELF Header: Magic: 7f 45 4c 46 01 02 01 00 00 00 00 00 00 00 00 00 5 Class: ELF32 Data: 2's complement, big endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 10 Type: EXEC (Executable file) Machine: PowerPC Version: 0x1 Entry point address: 0x10002640 Start of program headers: 52 (bytes into file) 15 Start of section headers: 87460 (bytes into file) Flags: 0x0 Size of this header: 52 (bytes) Size of program headers: 32 (bytes) Number of program headers: 8 20 Size of section headers: 40 (bytes) Number of section headers: 29 Section header string table index: 28 [...] 25
Example 8.2, “The ELF Header, as shown by readelf” shows a human readable form as present by the readelf program, which is part of GNU binutils.
The e_ident array is
the first thing at the start of any ELF file, and always
starts with a few "magic" bytes. The first byte is 0x7F and
then the next three bytes are "ELF". You can inspect an ELF
binary to see this for yourself with something like the
hexdump command.
1 ianw@mingus:~$ hexdump -C /bin/ls | more 2 00000000 7f 45 4c 46 01 02 01 00 00 00 00 00 00 00 00 00 |.ELF............| 3 4 ... (rest of the program follows) ...
Note the 0x7F to start, then the ASCII encoded "ELF" string. Have a look at the standard and see what the rest of the array defines and what the values are in a binary.
Next we have some flags for the type of machine this
binary is created for. The first thing we can see is that ELF
defines different type sized versions, one for 32 bit and one
for 64 bit versions; here we inspect the 32 bit version. The
difference is mostly that on 64 bit machines addresses
obviously required to be held in 64 bit variables. We can see
that the binary has been created for a big endian machine that
uses 2's complement to represent negative numbers. Skipping
down a bit we can see the
Machine tells us this is a
PowerPC binary.
The apparently innocuous entry point address seems straight forward enough; this is the address in memory that the program code starts at. Beginning C programmers are told that main() is the first program called in your program. Using the entry point address we can actually verify that it isn't.
1 $ cat test.c
#include <stdio.h>
int main(void)
5 {
printf("main is : %p\n", &main);
return 0;
}
10 $ gcc -Wall -o test test.c
$ ./test
main is : 0x10000430
15 $ readelf --headers ./test | grep 'Entry point'
Entry point address: 0x100002b0
$ objdump --disassemble ./test | grep 100002b0
100002b0 <_start>:
20 100002b0: 7c 29 0b 78 mr r9,r1
In Example 8.4, “Investigating the entry point” we can see that the
entry point is actually a function called
_start. Our program didn't
define this at all, and the leading underscore suggests that
it is in a separate namespace. We
examine how a program starts up in detail in the section called “Starting the program”.
After that the header contains pointers to where in the file other important parts of the ELF file start, like a table of contents.
Symbols and Relocations
The ELF specification provides for symbol
tables which are simply mappings of strings
(symbols) to locations in the file. Symbols are required for
linking; for example assigning a value to a variable
foo declared as
extern int foo; would require
the linker to find the address of
foo, which would involve
looking up "foo" in the symbol table and finding the
address.
Closely related to symbols are
relocations. A relocation is simply a
blank space left to be patched up later. In the previous
example, until the address of
foo is known it can not be
used. However, on a 32-bit system, we know the
address of
foo must be a 4-byte value,
so any time the compiler needs to use that address (to say,
assign a value) it can simply leave 4-bytes of blank space and
keep a relocation that essentially says to the linker "place
the real value of "foo" into the 4 bytes at this address". As
mentioned, this requires the symbol "foo" to be resolved.
the section called “Relocations” contains further
information on relocations.
Sections and Segments
The ELF format specifies two "views" of an ELF file — that which is used for linking and that which is used for execution. This affords significant flexibility for systems designers.
We talk about sections in object code waiting to be linked into an executable. One or more sections map to a segment in the executable.
Segments
As we have done before, it is sometimes easier to look at the higher level of abstraction (segments) before inspecting the lower layers.
As we mentioned the ELF file has an header that describes the overall layout of the file. The ELF header actually points to another group of headers called the program headers. These headers describe to the operating system anything that might be required for it to load the binary into memory and execute it. Segments are described by program headers, but so are some other things required to get the executable running.
1 typedef struct {
Elf32_Word p_type;
Elf32_Off p_offset;
Elf32_Addr p_vaddr;
5 Elf32_Addr p_paddr;
Elf32_Word p_filesz;
Elf32_Word p_memsz;
Elf32_Word p_flags;
Elf32_Word p_align;
10 }
The definition of the program header is seen in Example 8.5, “The Program Header”. You might have noticed from
the ELF header definition above how there were fields
e_phoff,
e_phnum and
e_phentsize; these are
simply the offset in the file where the program headers
start, how many program headers there are and how big each
program header is. With these three bits of information you
can easily find and read the program headers.
Program headers more than just segments. The
p_type field defines just
what the program header is defining. For example, if this
field is PT_INTERP the
header is defined as meaning a string pointer to an
interpreter for the binary file. We
discussed compiled versus interpreted languages previously
and made the distinction that a compiler builds a binary
which can be run in a stand alone fashion. Why should it
need an interpreter? As always, the true picture is a
little more complicated. There are several reasons why a
modern system wants flexibility when loading executable
files, and to do this some information can only be
adequately acquired at the actual time the program is set up
to run. We see this in future chapters where we look into
dynamic linking. Consequently some minor changes might need
to be made to the binary to allow it to work properly at
runtime. Thus the usual interpreter of a binary file is the
dynamic loader, so called because it
takes the final steps to complete loading of the executable
and prepare the binary image for running.
Segments are described with a value of
PT_LOAD in the
p_type field. Each segment
is then described by the other fields in the program header.
The p_offset field tells
you how far into the file on disk the data for the segment
is. The p_vaddr field
tells you what address that data is to live at in virtual
memory (p_addr describes
the physical address, which is only really useful for small
embedded systems that do not implement virtual memory). The
two flags p_filesz and
p_memsz work to tell you
how big the segment is on disk and how big it should be in
memory. If the memory size is greater than the disk size,
then the overlap should be filled with zeros. In this way
you can save considerable space in your binaries by not
having to waste space for empty global variables. Finally
p_flags indicates the
permissions on the segment. Execute, read and write
permissions can be specified in any combination; for example
code segments should be marked as read and execute only,
data sections as read and write with no execute.
There are a few other segment types defined in the program headers, they are described more fully in the standards specification.
Sections
As we have mentioned, sections make up segments. Sections are a way to organise the binary into logical areas to communicate information between the compiler and the linker. In some special binaries, such as the Linux kernel, sections are used in more specific ways (see the section called “Custom sections”).
We've seen how segments ultimately come down to a blob of data in a file on disk with some descriptions about where it should be loaded and what permissions it has. Sections have a similar header to segments, as shown in Example 8.6, “Sections ”.
1 typedef struct {
Elf32_Word sh_name;
Elf32_Word sh_type;
Elf32_Word sh_flags;
5 Elf32_Addr sh_addr;
Elf32_Off sh_offset;
Elf32_Word sh_size;
Elf32_Word sh_link;
Elf32_Word sh_info;
10 Elf32_Word sh_addralign;
Elf32_Word sh_entsize;
}
Sections have a few more types defined for the
sh_type field; for example
a section of type
SH_PROGBITS is defined as a
section that hold binary data for use by the program. Other
flags say if this section is a symbol table (used by the
linker or debugger for example) or maybe something for the
dynamic loader. There are also more attributes, such as the
allocate attribute which flags that
this section will need memory allocated for it.
Below we will examine the program listed in Example 8.7, “Sections ”.
1 #include <stdio.h> int big_big_array[10*1024*1024]; 5 char *a_string = "Hello, World!"; int a_var_with_value = 0x100; int main(void) 10 { big_big_array[0] = 100; printf("%s\n", a_string); a_var_with_value += 20; } 15
Example 8.8, “Sections readelf output ” shows the output of readelf with some parts stripped clarity. Using this output we can analyse each part of our simple program and see where it ends up in the final output binary.
1 $ readelf --all ./sections ELF Header: ... Size of section headers: 40 (bytes) 5 Number of section headers: 37 Section header string table index: 34 Section Headers: [Nr] Name Type Addr Off Size ES Flg Lk Inf Al 10 [ 0] NULL 00000000 000000 000000 00 0 0 0 [ 1] .interp PROGBITS 10000114 000114 00000d 00 A 0 0 1 [ 2] .note.ABI-tag NOTE 10000124 000124 000020 00 A 0 0 4 [ 3] .hash HASH 10000144 000144 00002c 04 A 4 0 4 [ 4] .dynsym DYNSYM 10000170 000170 000060 10 A 5 1 4 15 [ 5] .dynstr STRTAB 100001d0 0001d0 00005e 00 A 0 0 1 [ 6] .gnu.version VERSYM 1000022e 00022e 00000c 02 A 4 0 2 [ 7] .gnu.version_r VERNEED 1000023c 00023c 000020 00 A 5 1 4 [ 8] .rela.dyn RELA 1000025c 00025c 00000c 0c A 4 0 4 [ 9] .rela.plt RELA 10000268 000268 000018 0c A 4 25 4 20 [10] .init PROGBITS 10000280 000280 000028 00 AX 0 0 4 [11] .text PROGBITS 100002b0 0002b0 000560 00 AX 0 0 16 [12] .fini PROGBITS 10000810 000810 000020 00 AX 0 0 4 [13] .rodata PROGBITS 10000830 000830 000024 00 A 0 0 4 [14] .sdata2 PROGBITS 10000854 000854 000000 00 A 0 0 4 25 [15] .eh_frame PROGBITS 10000854 000854 000004 00 A 0 0 4 [16] .ctors PROGBITS 10010858 000858 000008 00 WA 0 0 4 [17] .dtors PROGBITS 10010860 000860 000008 00 WA 0 0 4 [18] .jcr PROGBITS 10010868 000868 000004 00 WA 0 0 4 [19] .got2 PROGBITS 1001086c 00086c 000010 00 WA 0 0 1 30 [20] .dynamic DYNAMIC 1001087c 00087c 0000c8 08 WA 5 0 4 [21] .data PROGBITS 10010944 000944 000008 00 WA 0 0 4 [22] .got PROGBITS 1001094c 00094c 000014 04 WAX 0 0 4 [23] .sdata PROGBITS 10010960 000960 000008 00 WA 0 0 4 [24] .sbss NOBITS 10010968 000968 000000 00 WA 0 0 1 35 [25] .plt NOBITS 10010968 000968 000060 00 WAX 0 0 4 [26] .bss NOBITS 100109c8 000968 2800004 00 WA 0 0 4 [27] .comment PROGBITS 00000000 000968 00018f 00 0 0 1 [28] .debug_aranges PROGBITS 00000000 000af8 000078 00 0 0 8 [29] .debug_pubnames PROGBITS 00000000 000b70 000025 00 0 0 1 40 [30] .debug_info PROGBITS 00000000 000b95 0002e5 00 0 0 1 [31] .debug_abbrev PROGBITS 00000000 000e7a 000076 00 0 0 1 [32] .debug_line PROGBITS 00000000 000ef0 0001de 00 0 0 1 [33] .debug_str PROGBITS 00000000 0010ce 0000f0 01 MS 0 0 1 [34] .shstrtab STRTAB 00000000 0011be 00013b 00 0 0 1 45 [35] .symtab SYMTAB 00000000 0018c4 000c90 10 36 65 4 [36] .strtab STRTAB 00000000 002554 000909 00 0 0 1 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings) I (info), L (link order), G (group), x (unknown) 50 O (extra OS processing required) o (OS specific), p (processor specific) There are no section groups in this file. ... 55 Symbol table '.symtab' contains 201 entries: Num: Value Size Type Bind Vis Ndx Name ... 99: 100109cc 0x2800000 OBJECT GLOBAL DEFAULT 26 big_big_array ... 60 110: 10010960 4 OBJECT GLOBAL DEFAULT 23 a_string ... 130: 10010964 4 OBJECT GLOBAL DEFAULT 23 a_var_with_value ... 144: 10000430 96 FUNC GLOBAL DEFAULT 11 main 65
Firstly, let us look at the variable
big_big_array, which as the
name suggests is a fairly large global array. If we skip
down to the symbol table we can see that the variable is at
location 0x100109cc which
we can correlate to the
.bss section in the section
listing, since it starts just below it at
0x100109c8. Note the size,
and how it is quite large. We mentioned that BSS is a
standard part of a binary image since it would be silly to
require that binary on disk have 10 megabytes of space
allocated to it, when all of that space is going to be zero.
Note that this section has a type of
NOBITS meaning that it does
not have any bytes on disk.
Thus the .bss section
is defined for global variables whose value should be zero
when the program starts. We have seen how the memory size
can be different to the on disk size in our discussion of
segments; variables being in the
.bss section are an
indication that they will be given zero value on program
start.
The a_string variable
lives in the .sdata
section, which stands for small data.
Small data (and the corresponding
.sbss section) are sections
available on some architectures where data can be reached by
an offset from some known pointer. This means a fixed-value
can be added to the base-address, making it faster to get to
data in the sections as there are no extra lookups and
loading of addresses into memory required. Most
architectures are limited to the size of immediate values
you can add to a register (e.g. if performing the
instruction r1 = add r2,
70;, 70 is an immediate
value, as opposed to say, adding two values
stored in registers r1 = add
r2,r3) and can thus only offset a certain
"small" distance from an address. We can also see that our
a_var_with_value lives in
the same place.
main however lives in
the .text section, as we
expect (remember the name "text" and "code" are used
interchangeably to refer to a program in memory.
Sections and Segments together
1 $ readelf --segments /bin/ls Elf file type is EXEC (Executable file) Entry point 0x100026c0 5 There are 8 program headers, starting at offset 52 Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align PHDR 0x000034 0x10000034 0x10000034 0x00100 0x00100 R E 0x4 10 INTERP 0x000154 0x10000154 0x10000154 0x0000d 0x0000d R 0x1 [Requesting program interpreter: /lib/ld.so.1] LOAD 0x000000 0x10000000 0x10000000 0x14d5c 0x14d5c R E 0x10000 LOAD 0x014d60 0x10024d60 0x10024d60 0x002b0 0x00b7c RWE 0x10000 DYNAMIC 0x014f00 0x10024f00 0x10024f00 0x000d8 0x000d8 RW 0x4 15 NOTE 0x000164 0x10000164 0x10000164 0x00020 0x00020 R 0x4 GNU_EH_FRAME 0x014d30 0x10014d30 0x10014d30 0x0002c 0x0002c R 0x4 GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RWE 0x4 Section to Segment mapping: 20 Segment Sections... 00 01 .interp 02 .interp .note.ABI-tag .hash .dynsym .dynstr .gnu.version .gnu.version_ r .rela.dyn .rela.plt .init .text .fini .rodata .eh_frame_hdr 03 .data .eh_frame .got2 .dynamic .ctors .dtors .jcr .got .sdata .sbss .p lt .bss 25 04 .dynamic 05 .note.ABI-tag 06 .eh_frame_hdr 07
Example 8.9, “Sections and Segments” shows how
readelf shows us the
segments and section mappings in the ELF file for the binary
/bin/ls.
Skipping to the bottom of the output, we can see what
sections have been moved into what segments. So, for
example the .interp section
is placed into an INTERP
flagged segment. Notice that readelf tells us it is
requesting the interpreter
/lib/ld.so.1; this is the
dynamic linker which is run to prepare the binary for
execution.
Looking at the two
LOAD segments we can see
the distinction between text and data. Notice how the first
one has only "read" and "execute" permissions, whilst the
next one has read, write and execute permissions? These
describe the code (r/w) and data (r/w/e) segments.
But data should not need to be executable! Indeed, on most architectures (for example, the most common x86) the data section will not be marked as having the data section executable. However, the example output above was taken from a PowerPC machine which has a slightly different programming model (ABI, see below) requiring that the data section be executable [24]. Such is the life of a systems programmer, where rules were made to be broken!
The other interesting thing to note is that the file size is the same as the memory size for the code segment, however memory size is greater than the file size for the data segment. This comes from the BSS section which holds zeroed global variables.
[24] For those that are curious, the PowerPC ABI calls stubs for functions in dynamic libraries directly in the GOT, rather than having them bounce through a separate PLT entry. Thus the processor needs execute permissions for the GOT section, which you can see is embedded in the data segment. This should make sense after reading the dynamic linking chapter!