
Computer Architecture
- Page ID
- 81568
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Chapter 3. Computer Architecture
The CPU
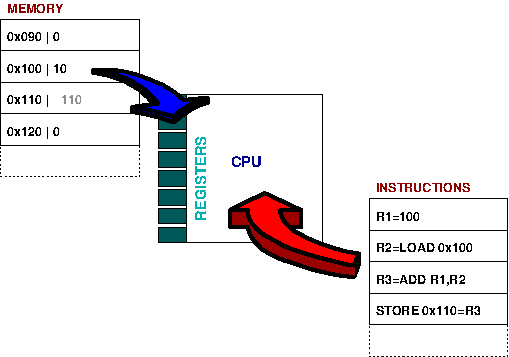
The CPU performs instructions on values held in registers. This example shows firstly setting the value of R1 to 100, loading the value from memory location 0x100 into R2, adding the two values together and placing the result in R3 and finally storing the new value (110) to R4 (for further use).
To greatly simplify, a computer consists of a central processing unit (CPU) attached to memory. The figure above illustrates the general principle behind all computer operations.
The CPU executes instructions read from memory. There are two categories of instructions
Those that load values from memory into registers and store values from registers to memory.
Those that operate on values stored in registers. For example adding, subtracting multiplying or dividing the values in two registers, performing bitwise operations (and, or, xor, etc) or performing other mathematical operations (square root, sin, cos, tan, etc).
So in the example we are simply adding 100 to a value stored in memory, and storing this new result back into memory.
Branching
Apart from loading or storing, the other important operation of a CPU is branching. Internally, the CPU keeps a record of the next instruction to be executed in the instruction pointer. Usually, the instruction pointer is incremented to point to the next instruction sequentially; the branch instruction will usually check if a specific register is zero or if a flag is set and, if so, will modify the pointer to a different address. Thus the next instruction to execute will be from a different part of program; this is how loops and decision statements work.
For example, a statement like if
(x==0) might be implemented by finding the
or of two registers, one
holding x and the other zero;
if the result is zero the comparison is true (i.e. all bits of
x were zero) and the body of
the statement should be taken, otherwise branch past the body
code.
Cycles
We are all familiar with the speed of the computer, given in Megahertz or Gigahertz (millions or thousands of millions cycles per second). This is called the clock speed since it is the speed that an internal clock within the computer pulses.
The pulses are used within the processor to keep it internally synchronised. On each tick or pulse another operation can be started; think of the clock like the person beating the drum to keep the rower's oars in sync.
Fetch, Decode, Execute, Store
Executing a single instruction consists of a particular cycle of events; fetching, decoding, executing and storing.
For example, to do the
add instruction above the CPU
must
Fetch : get the instruction from memory into the processor.
Decode : internally decode what it has to do (in this case add).
Execute : take the values from the registers, actually add them together
Store : store the result back into another register. You might also see the term retiring the instruction.
Looking inside a CPU
Internally the CPU has many different sub components that perform each of the above steps, and generally they can all happen independently of each other. This is analogous to a physical production line, where there are many stations where each step has a particular task to perform. Once done it can pass the results to the next station and take a new input to work on.
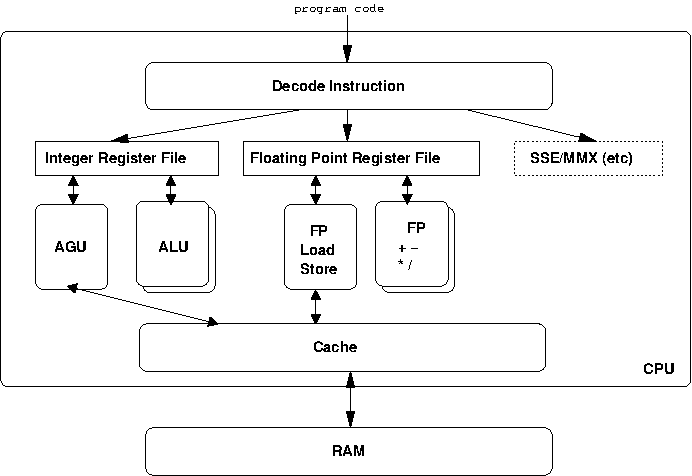
The CPU is made up of many different sub-components, each doing a dedicated task.
Figure 3.2, “Inside the CPU” shows a very simple block diagram illustrating some of the main parts of a modern CPU.
You can see the instructions come in and are decoded by the processor. The CPU has two main types of registers, those for integer calculations and those for floating point calculations. Floating point is a way of representing numbers with a decimal place in binary form, and is handled differently within the CPU. MMX (multimedia extension) and SSE (Streaming Single Instruction Multiple Data) or Altivec registers are similar to floating point registers.
A register file is the collective name for the registers inside the CPU. Below that we have the parts of the CPU which really do all the work.
We said that processors are either loading or storing a value into a register or from a register into memory, or doing some operation on values in registers.
The Arithmetic Logic Unit (ALU) is the heart of the CPU operation. It takes values in registers and performs any of the multitude of operations the CPU is capable of. All modern processors have a number of ALUs so each can be working independently. In fact, processors such as the Pentium have both fast and slow ALUs; the fast ones are smaller (so you can fit more on the CPU) but can do only the most common operations, slow ALUs can do all operations but are bigger.
The Address Generation Unit (AGU) handles talking to cache and main memory to get values into the registers for the ALU to operate on and get values out of registers back into main memory.
Floating point registers have the same concepts, but use slightly different terminology for their components.
Pipelining
As we can see above, whilst the ALU is adding registers together is completely separate to the AGU writing values back to memory, so there is no reason why the CPU can not be doing both at once. We also have multiple ALUs in the system, each which can be working on separate instructions. Finally the CPU could be doing some floating point operations with its floating point logic whilst integer instructions are in flight too. This process is called pipelining[5], and a processor that can do this is referred to as a superscalar architecture. All modern processors are superscalar.
Another analogy might be to think of the pipeline like a hose that is being filled with marbles, except our marbles are instructions for the CPU. Ideally you will be putting your marbles in one end, one after the other (one per clock pulse), filling up the pipe. Once full, for each marble (instruction) you push in all the others will move to the next position and one will fall out the end (the result).
Branch instruction play havoc with this model however, since they may or may not cause execution to start from a different place. If you are pipelining, you will have to basically guess which way the branch will go, so you know which instructions to bring into the pipeline. If the CPU has predicted correctly, everything goes fine![6] Conversely, if the processor has predicted incorrectly it has wasted a lot of time and has to clear the pipeline and start again.
This process is usually referred to as a pipeline flush and is analogous to having to stop and empty out all your marbles from your hose!
Branch Prediction
pipeline flush, predict taken, predict not taken, branch delay slots
Reordering
In fact, if the CPU is the hose, it is free to reorder the marbles within the hose, as long as they pop out the end in the same order you put them in. We call this program order since this is the order that instructions are given in the computer program.
1: r3 = r1 * r2 2: r4 = r2 + r3 3: r7 = r5 * r6 4: r8 = r1 + r7
Consider an instruction stream such as that shown in Figure 3.3, “Reorder buffer example” Instruction 2 needs to wait for instruction 1 to complete fully before it can start. This means that the pipeline has to stall as it waits for the value to be calculated. Similarly instructions 3 and 4 have a dependency on r7. However, instructions 2 and 3 have no dependency on each other at all; this means they operate on completely separate registers. If we swap instructions 2 and 3 we can get a much better ordering for the pipeline since the processor can be doing useful work rather than waiting for the pipeline to complete to get the result of a previous instruction.
However, when writing very low level code some instructions may require some security about how operations are ordered. We call this requirement memory semantics. If you require acquire semantics this means that for this instruction you must ensure that the results of all previous instructions have been completed. If you require release semantics you are saying that all instructions after this one must see the current result. Another even stricter semantic is a memory barrier or memory fence which requires that operations have been committed to memory before continuing.
On some architectures these semantics are guaranteed for you by the processor, whilst on others you must specify them explicitly. Most programmers do not need to worry directly about them, although you may see the terms.
CISC v RISC
A common way to divide computer architectures is into Complex Instruction Set Computer (CISC) and Reduced Instruction Set Computer (RISC).
Note in the first example, we have explicitly loaded values into registers, performed an addition and stored the result value held in another register back to memory. This is an example of a RISC approach to computing -- only performing operations on values in registers and explicitly loading and storing values to and from memory.
A CISC approach may be only a single instruction taking values from memory, performing the addition internally and writing the result back. This means the instruction may take many cycles, but ultimately both approaches achieve the same goal.
All modern architectures would be considered RISC architectures[7].
There are a number of reasons for this
Whilst RISC makes assembly programming becomes more complex, since virtually all programmers use high level languages and leave the hard work of producing assembly code to the compiler, so the other advantages outweigh this disadvantage.
Because the instructions in a RISC processor are much more simple, there is more space inside the chip for registers. As we know from the memory hierarchy, registers are the fastest type of memory and ultimately all instructions must be performed on values held in registers, so all other things being equal more registers leads to higher performance.
Since all instructions execute in the same time, pipelining is possible. We know pipelining requires streams of instructions being constantly fed into the processor, so if some instructions take a very long time and others do not, the pipeline becomes far to complex to be effective.
EPIC
The Itanium processor, which is used in many example through this book, is an example of a modified architecture called Explicitly Parallel Instruction Computing.
We have discussed how superscaler processors have pipelines that have many instructions in flight at the same time in different parts of the processor. Obviously for this to work as well as possible instructions should be given the processor in an order that can make best use of the available elements of the CPU.
Traditionally organising the incoming instruction stream has been the job of the hardware. Instructions are issued by the program in a sequential manner; the processor must look ahead and try to make decisions about how to organise the incoming instructions.
The theory behind EPIC is that there is more information available at higher levels which can make these decisions better than the processor. Analysing a stream of assembly language instructions, as current processors do, loses a lot of information that the programmer may have provided in the original source code. Think of it as the difference between studying a Shakespeare play and reading the Cliff's Notes version of the same. Both give you the same result, but the original has all sorts of extra information that sets the scene and gives you insight into the characters.
Thus the logic of ordering instructions can be moved from the processor to the compiler. This means that compiler writers need to be smarter to try and find the best ordering of code for the processor. The processor is also significantly simplified, since a lot of its work has been moved to the compiler.[8]
[5] In fact, any modern processor has many more than four stages it can pipeline, above we have only shown a very simplified view. The more stages that can be executed at the same time, the deeper the pipeline.
[6] Processors such as the Pentium use a trace cache to keep a track of which way branches are going. Much of the time it can predict which way a branch will go by remembering its previous result. For example, in a loop that happens 100 times, if you remember the last result of the branch you will be right 99 times, since only the last time will you actually continue with the program.
[7] Even the most common architecture, the Intel Pentium, whilst having an instruction set that is categorised as CISC, internally breaks down instructions to RISC style sub-instructions inside the chip before executing.
[8] Another term often used around EPIC is Very Long Instruction World (VLIW), which is where each instruction to the processor is extended to tell the processor about where it should execute the instruction in its internal units. The problem with this approach is that code is then completely dependent on the model of processor is has been compiled for. Companies are always making revisions to hardware, and making customers recompile their application every single time, and maintain a range of different binaries was impractical.
EPIC solves this in the usual computer science manner by adding a layer of abstraction. Rather than explicitly specifying the exact part of the processor the instructions should execute on, EPIC creates a simplified view with a few core units like memory, integer and floating point.