
1.1: Defining Data Science
- Page ID
- 39257

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)When people ask me what data science is, here’s my go-to definition: deriving knowledge from data. But interpreting that phrase entails dissecting the difference between “knowledge” and “data,” two related but different terms. And that brings me to the data-to-wisdom hierarchy, depicted in Figure 1.1.1. Let’s break it down.
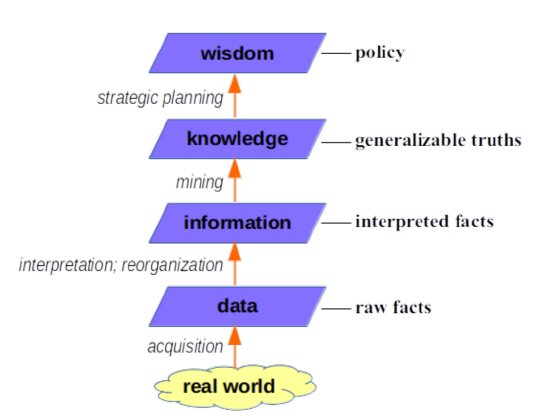
Figure \(\PageIndex{1}\): The data-to-wisdom hierarchy.
The Real World
Ultimately, what we’re interested in is not data, but aspects of the real world – album sales and video views, stock prices and employment rates, hurricane trajectories and virus hot spots, or whatever. Data science can’t really get off the ground until some sort of data acquisition takes place that records measurements of the real world in electronic form.
This sounds obvious, but it’s important to keep in mind, actually. No matter how much time we spend working with data, it’s never the data that actually matters – it’s the real-world phenomenon the data represents. It might seem strange to say that “data” is merely incidental to a data scientist, but it’s true. And I’ve definitely seen more than one data scientist get so locked on to the data that they forget this basic truth.
One important observation is that decisions about exactly which data to acquire from the real world are often crucial in how things are interpreted later on. To take an example close to home, let’s say we’re gathering information on college professors so we can gauge which universities have the highest performing faculty, and how this might be changing over the years. We choose some representative set of criteria to measure for each faculty member to get a rough assessment of their performance. Let’s say we choose three things: the number of research papers the professor publishes each year, the total amount of research funding they’ve been granted, and the average student evaluation score of the courses they teach. That seems like a good first cut at assessing “faculty performance.” We then go on our merry data science way, finding correlations, making data visualizations, and drawing conclusions.
This is all fine and dandy, provided we always keep in mind that it was those three qualities, and only those three, that we gathered in the first place. If our study gains any traction, and university professors find they have a vested interest in being ranked high in our yearly study, we’ll discover that they act to maximize only the categories that are being collected. We didn’t gather data on how many university committees they served on, or how many independent studies they supervised, or how many advisees they had, etc.
Those metrics will inevitably become minimized in importance, because they weren’t part of what we lifted out of the real world and onto the bottom rung of our lofty chain.
The moral is: what we measure matters, often more than we realize. Our country’s GDP and the Dow Jones Industrial Average are easy things to quantify, and so we often do. And thus they gain great importance in analyses of the economy. But are they actually the most important indicators? Does focusing on them leave out other, perhaps more vital, benchmarks? I’ll just leave you with that question for now.
Data
Have you ever gotten blood work done, say for an annual physical? I have. I like to look over the numbers when the doctor hands me the results, just to chuckle and wonder what they all mean. To me, a non-physician, they’re all pretty much gobbledy-gook. They tell me my TBC is 4.93 x10E6/µL, that I have 5.7 Absolute Neutrophils, and a slightly out-of-range NT-proBNP (just 53.49 pg/mL, whatever the heck that means).
When I use the word data in the context of the hierarchy, this is what I mean: recorded measurements, often (but not always) quantitative, that have not yet been interpreted. They may be very precise, but they’re also quite meaningless without the context in which to understand them. They’d even be meaningless to a physician if I didn’t provide the labels; try telling your doctor that you have 4.93 “something” and see whether he/she freaks out.
The good news is that when we’re at the data stage of the hierarchy, we at least have the stuff in an electronic form so we can start to do something with it. We also often make choices at this stage about how to organize the data, choosing the appropriate type of atomic and/or aggregate data structures that we’ll discuss in detail in Chapters 3 and beyond. This will allow us to bring our analysis equipment to bear on the problem in powerful ways.
Information
Data becomes information when it informs us of something; i.e., when we know what it means. Getting large amounts of data organized, formatted, and labeled the right way are jobs for the data scientist, since turning that morass into useful knowledge is impossible without those steps. When the aspects of the real world that we’ve collected are properly structured and conceptually meaningful, we’re in business.
Knowledge
Now knowledge is where the real action is. As shown in Figure 1.1.1, knowledge consists of generalizable truths.
Here’s what I mean. Information is about specific individuals or occurrences. When we say “Chandra is a female bank teller, and earns $48,000 a year,” or “Alex is a male bank teller, and earns $69,000 a year,” we have in our information repository some individual facts. They can be looked up and consulted when necessary, as you’ll learn in the first part of this book.
But if we say “women make less money than men do, even at the same jobs,” we’re in a different realm entirely. We have now generalized from specific facts to more wide-reaching tendencies. In the language of our discipline, we’ve moved from information to knowledge.
Properly gleaning knowledge from information is a trickier business than interpreting individual data points. There are established rules, some of them mathematical, for determining when an apparent pattern is actually reliable, what kinds of relationships can be detected with data, whether a relationship is causal, and so forth. We’ll build some important foundations with this kind of reasoning in this Crystal Ball volume and its follow-on companion. For now, I only want to make the point that knowledge – as opposed to mere information – opens up a whole new world of understanding. No longer is the world limited to a chaotic collection of individual observations: we can now begin to understand the general ways in which the world works...and perhaps even to change them.
Wisdom
Wisdom is the gold standard. It represents what we do with our knowledge. Let’s say we indeed determine that on average men are paid higher than women in our country, even for the same jobs. What do we do with that realization? Is it okay? Do we want to try and fix it, and if so, how? With laws? Education? Government subsidies? Revolution?
You’ll remember my definition of Data Science on p. 2: deriving knowledge from data. This implies that the “wisdom” level of the hierarchy is really outside the discipline, and belongs to other disciplines instead. And that’s partially true: in some sense, the data scientist’s job stops when the deep truths about the real world are ferreted out and illustrated, leaving it to CEOs, directors, and other policy makers to act on them. But the data scientist is often involved here too, for a simple reason: a decision maker wants to know what’s likely to happen if a particular policy is implemented. Most non-trivial interventions will have results that are hard to predict in advance, as well as unintended side effects. One set of tools in the data scientist’s toolkit is for making principled, calculated predictions about such things, as well as quantifying the level of uncertainty in the predictions. Sometimes, the technique of simulation is used – carrying out experiments on virtual societies or systems to see the likely aggregate effects of different interventions. It’s like having a high-dimensional, multi-faceted crystal ball that lets you play out various scenarios to their logical conclusions.
Starting with the rough and tumble real world and helping produce wise decisions about how humankind can deal with it all: that’s the grand promise of the data science enterprise. And those are the mighty waters you’re about to dip your toes in! I hope you’ll find it as exhilarating as I do.