
5.1: ChainedHashTable - Hashing with Chaining
- Page ID
- 8456

A ChainedHashTable data structure uses hashing with chaining to store data as an array, \(\mathtt{t}\), of lists. An integer, \(\mathtt{n}\), keeps track of the total number of items in all lists (see Figure \(\PageIndex{1}\)):
List<T>[] t;
int n;
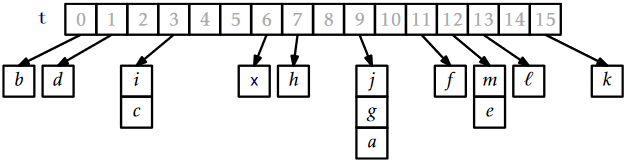
The hash value of a data item \(\mathtt{x}\), denoted \(\mathtt{hash(x)}\) is a value in the range \(\{0,\ldots,\texttt{t.length}-1\}\). All items with hash value \(\mathtt{i}\) are stored in the list at \(\mathtt{t[i]}\). To ensure that lists don't get too long, we maintain the invariant
\[ \mathtt{n} \le \texttt{t.length} \nonumber\]
so that the average number of elements stored in one of these lists is \(\mathtt{n}/\texttt{t.length} \le 1\).
To add an element, \(\mathtt{x}\), to the hash table, we first check if the length of \(\mathtt{t}\) needs to be increased and, if so, we grow \(\mathtt{t}\). With this out of the way we hash \(\mathtt{x}\) to get an integer, \(\mathtt{i}\), in the range \(\{0,\ldots,\texttt{t.length}-1\}\), and we append \(\mathtt{x}\) to the list \(\mathtt{t[i]}\):
boolean add(T x) {
if (find(x) != null) return false;
if (n+1 > t.length) resize();
t[hash(x)].add(x);
n++;
return true;
}
Growing the table, if necessary, involves doubling the length of \(\mathtt{t}\) and reinserting all elements into the new table. This strategy is exactly the same as the one used in the implementation of ArrayStack and the same result applies: The cost of growing is only constant when amortized over a sequence of insertions (see Lemma 2.1.1 in Section 2.1.2).
Besides growing, the only other work done when adding a new value \(\mathtt{x}\) to a ChainedHashTable involves appending \(\mathtt{x}\) to the list \(\mathtt{t[hash(x)]}\). For any of the list implementations described in Chapters 2 or 3, this takes only constant time.
To remove an element, \(\mathtt{x}\), from the hash table, we iterate over the list \(\mathtt{t[hash(x)]}\) until we find \(\mathtt{x}\) so that we can remove it:
T remove(T x) {
Iterator<T> it = t[hash(x)].iterator();
while (it.hasNext()) {
T y = it.next();
if (y.equals(x)) {
it.remove();
n--;
return y;
}
}
return null;
}
This takes \(O(\mathtt{n}_{\mathtt{hash(x)}})\) time, where \(\mathtt{n}_{\mathtt{i}}\) denotes the length of the list stored at \(\mathtt{t[i]}\).
Searching for the element \(\mathtt{x}\) in a hash table is similar. We perform a linear search on the list \(\mathtt{t[hash(x)]}\):
T find(Object x) {
for (T y : t[hash(x)])
if (y.equals(x))
return y;
return null;
}
Again, this takes time proportional to the length of the list \(\mathtt{t[hash(x)]}\).
The performance of a hash table depends critically on the choice of the hash function. A good hash function will spread the elements evenly among the \(\texttt{t.length}\) lists, so that the expected size of the list \(\mathtt{t[hash(x)]}\) is \(O(\mathtt{n}/\texttt{t.length)} = O(1)\). On the other hand, a bad hash function will hash all values (including \(\mathtt{x}\)) to the same table location, in which case the size of the list \(\mathtt{t[hash(x)]}\) will be \(\mathtt{n}\). In the next section we describe a good hash function.
\(\PageIndex{1}\) Multiplicative Hashing
Multiplicative hashing is an efficient method of generating hash values based on modular arithmetic (discussed in Section 2.3) and integer division. It uses the \(\textrm{div}\) operator, which calculates the integral part of a quotient, while discarding the remainder. Formally, for any integers \(a\ge 0\) and \(b\ge 1\), \(a\textrm{ div } b = \lfloor a/b\rfloor\).
In multiplicative hashing, we use a hash table of size \(2^{\mathtt{d}}\) for some integer \(\mathtt{d}\) (called the dimension). The formula for hashing an integer \(\mathtt{x}\in\{0,\ldots,2^{\mathtt{w}}-1\}\) is
\[ \mathtt{hash(x)} = ((\mathtt{z}\cdot\mathtt{x})\bmod 2^{\mathtt{w}}) \textrm{ div } 2^{\mathtt{w}-\mathtt{d}} \enspace . \nonumber\]
Here, \(\mathtt{z}\) is a randomly chosen odd integer in \(\{1,\ldots,2^{\mathtt{w}}-1\}\). This hash function can be realized very efficiently by observing that, by default, operations on integers are already done modulo \(2^{\mathtt{w}}\) where \(\mathtt{w}\) is the number of bits in an integer.1 (See Figure \(\PageIndex{2}\).) Furthermore, integer division by \(2^{\mathtt{w}-\mathtt{d}}\) is equivalent to dropping the rightmost \(\mathtt{w}-\mathtt{d}\) bits in a binary representation (which is implemented by shifting the bits right by \(\mathtt{w}-\mathtt{d}\) using the \(\mathtt{\text{>>>}}\) operator). In this way, the code that implements the above formula is simpler than the formula itself:
int hash(Object x) {
return (z * x.hashCode()) >>> (w-d);
}

The following lemma, whose proof is deferred until later in this section, shows that multiplicative hashing does a good job of avoiding collisions:
Let \(\mathtt{x}\) and \(\mathtt{y}\) be any two values in \(\{0,\ldots,2^{\mathtt{w}}-1\}\) with \(\mathtt{x}\neq \mathtt{y}\). Then \(\Pr\{\mathtt{hash(x)}=\mathtt{hash(y)}\} \le 2/2^{\mathtt{d}}\).
With Lemma \(\PageIndex{1}\), the performance of \(\mathtt{remove(x)}\), and \(\mathtt{find(x)}\) are easy to analyze:
For any data value \(\mathtt{x}\), the expected length of the list \(\mathtt{t[hash(x)]}\) is at most \(\mathtt{n}_{\mathtt{x}} + 2\), where \(\mathtt{n}_{\mathtt{x}}\) is the number of occurrences of \(\mathtt{x}\) in the hash table.
Proof. Let \(S\) be the (multi-)set of elements stored in the hash table that are not equal to \(\mathtt{x}\). For an element \(\mathtt{y}\in S\), define the indicator variable
\[ I_{\mathtt{y}} = \left\{
\begin{array}{ll}
1 & \mbox{if $\mathtt{hash(x)}= \mathtt{hash(y)}$} \\
0 & \mbox{otherwise}
\end{array}\right. \nonumber\]
and notice that, by Lemma \(\PageIndex{1}\), \(\mathrm{E}[I_{\mathtt{y}}] \le 2/2^{\mathtt{d}}=2/\texttt{t.length}\). The expected length of the list \(\mathtt{t[hash(x)]}\) is given by
\[\begin{align} \mathrm{E}\left[\texttt{t[hash(x)].size()}\right]
&=\mathrm{E}\left[\mathtt{n}_{\mathtt{x}} + \sum_{\mathtt{y}\in S} I_{\mathtt{y}}\right]\nonumber\\
&=\mathtt{n}_{\mathtt{x}} + \sum_{\mathtt{y}\in S} \mathrm{E}[I_{\mathtt{y}} ]\nonumber\\
&\le \mathtt{n}_{\mathtt{x}} + \sum_{\mathtt{y}\in S} 2/\texttt{t.length}\nonumber\\
&\le \mathtt{n}_{\mathtt{x}} + \sum_{\mathtt{y}\in S} 2/\mathtt{n}\nonumber\\
&\le \mathtt{n}_{\mathtt{x}} + (\mathtt{n}-\mathtt{n}_{\mathtt{x}})2/\mathtt{n}\nonumber\\
&\le \mathtt{n}_{\mathtt{x}} + 2 \enspace ,\nonumber
\end{align}\nonumber\]
as required. ![]()
Now, we want to prove Lemma \(\PageIndex{1}\), but first we need a result from number theory. In the following proof, we use the notation \((b_r,\ldots,b_0)_2\) to denote \(\sum_{i=0}^r b_i2^i\), where each \(b_i\) is a bit, either 0 or 1. In other words, \((b_r,\ldots,b_0)_2\) is the integer whose binary representation is given by \(b_r,\ldots,b_0\). We use \(\star\) to denote a bit of unknown value.
Let \(S\) be the set of odd integers in \(\{1,\ldots,2^{\mathtt{w}}-1\}\); let \(q\) and \(i\) be any two elements in \(S\). Then there is exactly one value \(\mathtt{z}\in S\) such that \(\mathtt{z}q\bmod 2^{\mathtt{w}} = i\).
Proof. Since the number of choices for \(\mathtt{z}\) and \(i\) is the same, it is sufficient to prove that there is at most one value \(\mathtt{z}\in S\) that satisfies \(\mathtt{z}q\bmod 2^{\mathtt{w}} = i\).
Suppose, for the sake of contradiction, that there are two such values \(\mathtt{z}\) and \(\mathtt{z'}\), with \(\mathtt{z}>\mathtt{z}'\). Then
\[ \mathtt{z}q\bmod 2^{\mathtt{w}} = \mathtt{z}'q \bmod 2^{\mathtt{w}} = i \nonumber\]
So
\[ (\mathtt{z}-\mathtt{z}')q\bmod 2^{\mathtt{w}} = 0 \nonumber\]
But this means that
\[(\mathtt{z}-\mathtt{z}')q = k 2^{\mathtt{w}} \label{factors} \]
for some integer \(k\). Thinking in terms of binary numbers, we have
\[ (\mathtt{z}-\mathtt{z}')q = k\cdot(1,\underbrace{0,\ldots,0}_{\mathtt{w}})_2 \enspace , \nonumber\]
so that the \(\mathtt{w}\) trailing bits in the binary representation of \((\mathtt{z}-\mathtt{z}')q\) are all 0's.
Furthermore \(k\neq 0\), since \(q\neq 0\) and \(\mathtt{z}-\mathtt{z}'\neq 0\). Since \(q\) is odd, it has no trailing 0's in its binary representation:
\[ q = (\star,\ldots,\star,1)_2 \enspace . \nonumber\]
Since \(\vert\mathtt{z}-\mathtt{z}'\vert < 2^{\mathtt{w}}\), \(\mathtt{z}-\mathtt{z}'\) has fewer than \(\mathtt{w}\) trailing 0's in its binary representation:
\[ \mathtt{z}-\mathtt{z}' = (\star,\ldots,\star,1,\underbrace{0,\ldots,0}_{<\mathtt{w}})_2 \enspace . \nonumber\]
Therefore, the product \((\mathtt{z}-\mathtt{z}')q\) has fewer than \(\mathtt{w}\) trailing 0's in its binary representation:
\[ (\mathtt{z}-\mathtt{z}')q = (\star,\cdots,\star,1,\underbrace{0,\ldots,0}_{<\mathtt{w}})_2 \enspace . \nonumber\]
Therefore \((\mathtt{z}-\mathtt{z}')q\) cannot satisfy (\(\ref{factors}\)), yielding a contradiction and completing the proof. ![]()
The utility of Lemma \(\PageIndex{3}\) comes from the following observation: If \(\mathtt{z}\) is chosen uniformly at random from \(S\), then \(\mathtt{zt}\) is uniformly distributed over \(S\). In the following proof, it helps to think of the binary representation of \(\mathtt{z}\), which consists of \(\mathtt{w}-1\) random bits followed by a 1.
Proof of Lemma \(\PageIndex{1}\).
First we note that the condition \(\mathtt{hash(x)}=\mathtt{hash(y)}\) is equivalent to the statement "the highest-order \(\mathtt{d}\) bits of \(\mathtt{z} \mathtt{x}\bmod2^{\mathtt{w}}\) and the highest-order \(\mathtt{d}\) bits of \(\mathtt{z} \mathtt{y}\bmod 2^{\mathtt{w}}\) are the same." A necessary condition of that statement is that the highest-order \(\mathtt{d}\) bits in the binary representation of \(\mathtt{z}(\mathtt{x}-\mathtt{y})\bmod 2^{\mathtt{w}}\) are either all 0's or all 1's. That is,
\[\mathtt{z}(\mathtt{x}-\mathtt{y})\bmod 2^\mathtt{w}=(
\underbrace{0,\ldots,0}_{\mathtt{d}},
\underbrace{\star,\ldots,\star}_{\mathtt{w}-\mathtt{d}})_2\label{all-zeros}\]
when \(\mathtt{zx}\bmod 2^{\mathtt{w}} > \mathtt{zy}\bmod 2^{\mathtt{w}}\) or
\[\mathtt{z}(\mathtt{x}-\mathtt{y})\bmod 2^\mathtt{w} =
(\underbrace{1,\ldots,1}_{\mathtt{d}},
\underbrace{\star,\ldots,\star}_{\mathtt{w}-\mathtt{d}})_2 \enspace .\label{all-ones}\]
when \(\mathtt{zx}\bmod 2^{\mathtt{w}} < \mathtt{zy}\bmod 2^{\mathtt{w}}\). Therefore, we only have to bound the probability that \(\mathtt{z}(\mathtt{x}-\mathtt{y})\bmod 2^{\mathtt{w}}\) looks like (\(\ref{all-zeros}\)) or (\(\ref{all-ones}\)).
Let \(q\) be the unique odd integer such that \((\mathtt{x}-\mathtt{y})\bmod 2^{\mathtt{w}}=q2^r\) for some integer \(r\ge 0\). By Lemma \(\PageIndex{3}\), the binary representation of \(\mathtt{z}q\bmod 2^{\mathtt{w}}\) has \(\mathtt{w}-1\) random bits, followed by a 1:
\[ \mathtt{z}q\bmod 2^{\mathtt{w}} = (\underbrace{b_{\mathtt{w}-1},\ldots,b_{1}}_{\mathtt{w}-1},1)_2 \nonumber\]
Therefore, the binary representation of \(\mathtt{z}(\mathtt{x}-\mathtt{y})\bmod 2^{\mathtt{w}}=\mathtt{z}q2^r\bmod 2^{\mathtt{w}}\) has \(\mathtt{w}-r-1\) random bits, followed by a 1, followed by \(r\) 0's:
\[ \mathtt{z}(\mathtt{x}-\mathtt{y})\bmod 2^{\mathtt{w}}
=\mathtt{z}q2^r \bmod 2^{\mathtt{w}}
=(\underbrace{b_{\mathtt{w}-r-1},\ldots,b_{1}}_{\mathtt{w}-r-1},1,\underbrace{0,0,\ldots,0}_{r})_2 \nonumber\]
We can now finish the proof: If \(r > \mathtt{w}-\mathtt{d}\), then the \(\mathtt{d}\) higher order bits of \(\mathtt{z}(\mathtt{x}-\mathtt{y})\bmod 2^{\mathtt{w}}\) contain both 0's and 1's, so the probability that \(\mathtt{z}(\mathtt{x}-\mathtt{y})\bmod 2^{\mathtt{w}}\) looks like (\(\ref{all-zeros}\)) or (\(\ref{all-ones}\)) is 0. If \(\mathtt{r}=\mathtt{w}-\mathtt{d}\), then the probability of looking like (\(\ref{all-zeros}\)) is 0, but the probability of looking like (\(\ref{all-ones}\)) is \(1/2^{\mathtt{d}-1}=2/2^{\mathtt{d}}\) (since we must have \(b_1,\ldots,b_{d-1}=1,\ldots,1\)). If \(r < \mathtt{w}-\mathtt{d}\), then we must have \(b_{\mathtt{w}-r-1},\ldots,b_{\mathtt{w}-r-\mathtt{d}}=0,\ldots,0\) or \(b_{\mathtt{w}-r-1},\ldots,b_{\mathtt{w}-r-\mathtt{d}}=1,\ldots,1\). The probability of each of these cases is \(1/2^{\mathtt{d}}\) and they are mutually exclusive, so the probability of either of these cases is \(2/2^{\mathtt{d}}\). This completes the proof. ![]()
\(\PageIndex{2}\) Summary
The following theorem summarizes the performance of a ChainedHashTable data structure:
A ChainedHashTable implements the USet interface. Ignoring the cost of calls to \(\mathtt{grow()}\), a ChainedHashTable supports the operations \(\mathtt{add(x)}\), \(\mathtt{remove(x)}\), and \(\mathtt{find(x)}\) in \(O(1)\) expected time per operation.
Furthermore, beginning with an empty ChainedHashTable, any sequence of \(m\) \(\mathtt{add(x)}\) and \(\mathtt{remove(x)}\) operations results in a total of \(O(m)\) time spent during all calls to \(\mathtt{grow()}\).