
8.7: Exercises
- Page ID
- 7034

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Exercise \(\PageIndex{1}\)
Why can one not simply convert each database table into an OWL class and assume the bottom-up process is completed?
Exercise \(\PageIndex{2}\)
Name two modeling considerations going from conceptual data model to ontology.
Exercise \(\PageIndex{3}\)
Name the type of relations in a thesaurus.
Exercise \(\PageIndex{4}\)
What are some of the issues one has to deal with when developing an ontology bottom-up using a thesaurus?
Exercise \(\PageIndex{5}\)
What are the two ways one can use NLP for ontology development?
Exercise \(\PageIndex{6}\)
Machine learning was said to use inductive methods. Recall what that means and how it differs from deductive methods.
Exercise \(\PageIndex{7}\)
The least common subsumer and most specific concept use non-standard reasoning services that helps with ontology development. Describe in your own words what they do.
Exercise \(\PageIndex{8}\)
Examine Figure 7.7.2 and answer the following questions.
a. Represent the depicted knowledge in an OWL ontology.
b. Can you represent all knowledge? If not: what not?
c. Are there any problems with the original conceptual data model? If so, which one(s)?
.png?revision=1&size=bestfit&width=1004&height=458)
Figure 7.7.1: Example of a content OP represented informally on the left in UML class diagram style notion and formally on the right. There is a further extension to this OPD described in [VKC+16] as well as several instantiations.
.png?revision=1&size=bestfit&width=940&height=420)
Figure 7.7.2: A small conceptual model in ICom (from its website http://www.inf.unibz.it/∼franconi/∼icom; see [FFT12] for further details about the tool); blob: mandatory, open arrow: functional; square with star: disjoint complete, square with cross: disjoint, closed arrow (grey triangle): subsumption.
- Answer
-
Phone points conceptual data model to ontology:
(a) A sample formalization is available at the book’s resources page as
phonepoints.owl.(b) Yes, all of it it can be represented.
(c) Yes, there are problems. See Figure 7.7.3 for a graphical rendering that
MobileCallandCellare unsatisfiable; verify this with your version of the ontology. Observe that it also deduced that \(\texttt{PhonePoint}\equiv\texttt{LandLine}\)..png?revision=1&size=bestfit&width=1120&height=488)
Figure 7.7.3: Answer to Exercise 7.7.8-c: red: inconsistent class, green: ‘positive’ deduction
Exercise \(\PageIndex{9}\)
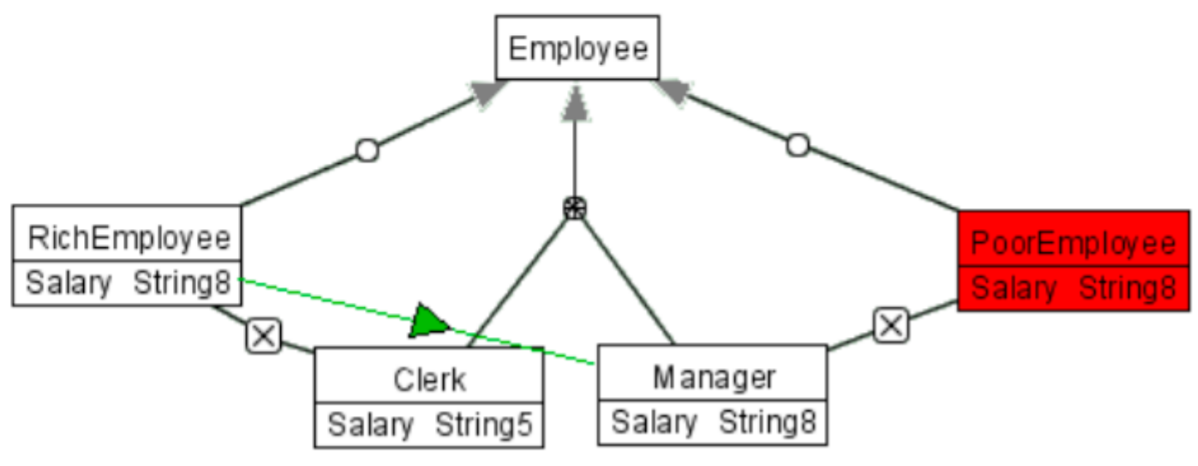
Figure 7.7.4 shows a very simple conceptual data model in roughly UML class diagram notation: a partition [read: disjoint, complete] of employees between clerks and managers, plus two more subclasses of employee, namely rich employee and poor employee, that are disjoint from the clerk and the manager classes, respectively (box with cross). All the subclasses have the salary attribute restricted to a string of length 8, except for the clerk entity that has the salary attribute restricted to be a string of length 5. Another conceptual data model, in ORM2 notation (which is a so-called attribute-free language), is depicted in Figure 7.7.5, which is roughly similar.
a. When you reason over the conceptual data model in Figure 7.7.4, you will find it has an inconsistent class and one new subsumption relation. Which class is inconsistent and what subsumes what (that is not already explicitly declared)? Try to find out manually, and check your answer by representing the diagram in an OWL ontology and run the reasoner to find out.
b. Develop a proper ontology that can handle both conceptual data models. Consider the issue of how deal with attributes and add the information that clerks work for at most 3 projects and managers manage at least one project.
.png?revision=1&size=bestfit&width=987&height=372)
Figure 7.7.4: A small conceptual model in ICom (Source: http://www.inf.unibz.it/∼franconi/∼icom).
.png?revision=1&size=bestfit&width=987&height=678)
Figure 7.7.5: A small conceptual model in ORM2, similar to that in Figure 7.7.4.
- Answer
-
Integration issues:
a. See Figure 7.7.6
.png?revision=1&size=bestfit&width=1122&height=436)
Figure 7.7.6: Answer to Exercise 7.7.9-a.
b. Multiple answers are possible due to various design decisions. E.g.,:
- Did you represent
Salaryas a class and invented a new object property to relate it to the employees, or used it as a name for an OWL data property (preferably the former)? And when a data property, did you use different data types (preferably not)? - Did you add
RichEmployee, or, better,Employeethat has some property of beingrich? - Did you use a foundational ontology, or at least make a distinction between the role and its bearer (
EmployeeandPerson, respectively)?
- Did you represent
Exercise \(\PageIndex{10}\)
Consider the small section of the Educational Resources Information Center thesaurus, below.
a. In which W3C-standardized (Semantic Web) language would you represent it, and why?
b. Are all BT/NT assertions subsumption relations?
c. There is an online tool that provides a semi-automatic approach to developing a domain ontology in OWL starting from SKOS. Find it. Why is it semi-automatic and can that be made fully automatic (and if so, how)?
Popular Culture
BT Culture
NT n/a
RT Globalization
RT Literature
RT Mass Media
RT Media Literacy
RT Films
UF Mass Culture (2004)
Mass Media
BT n/a
NT Films
NT News Media
NT Radio
RT Advertising
RT Propaganda
RT Publications;
UF Multichannel Programing (1966 1980) (2004)
Propaganda
BT Communication (Thought Transfer)
BT Information Dissemination
NT n/a
RT Advertising
RT Deception
RT Mass Media
UF n/a
- Answer
-
Thesauri:
a. Language: SKOS or OWL 2 EL. Why:
- SKOS: was the purpose of it, to have a simple, but formal, language for ‘smooth transition’ and tagging along with the SW
- OWL 2 EL: intended for large, simple, type-level ontologies, and then still some reasoning possible
b. Regarding mass media, films and news media: not necessarily, but to be certain, check yourself what the definition of
Mass Mediais, when something can be calledNews Media, and then assess the differences in their properties.Propagandahas as broader termInformation Dissemination, but a characteristic of propaganda is dissemination of misinformation.
Exercise \(\PageIndex{11}\)
In what way(s) may data mining be useful in bottom-up ontology development? Your answer should include something about the following three aspects:
a. populating the TBox (learning classes and hierarchies, relationships, constraints),
b. populating the ABox (assertions about instances), and
c. possible substitutes or additions to the standard automated reasoning service (consistency checking, instance classification, etc.)
Exercise \(\PageIndex{12}\)
Define a pattern for how to represent attributions with DOLCE’s Quality rather than an OWL data property.
Exercise \(\PageIndex{13}\)
OWL permits only binary object properties, though n-aries can be approximated. Describe how they can be approximated, and how your OP would look like such that, when given to a fellow student, s/he can repeat the modeling of that n-ary exactly the way you did it and add other n-aries in the same way.
- Answer
-
The description of the n-ary ODP can be found in the NeON deliverable D2.5.1 on pp67-68. Also, you may wish to inspect the draft ODPs that have been submitted to the ODP portal (at http://www.ontologydesignpatterns.org).
Exercise \(\PageIndex{14}\)
Inspect the Novel Abilities and Disabilities OntoLogy for ENhancing Accessibility: adolena; Figure 7.7.7 provides a basic informal overview. Can (any of) this be engineered into an ODP? If so, which type(s), how, what information is needed to document an OP?
.png?revision=1&size=bestfit&width=784&height=469)
Figure 7.7.7: Informal view of the ADOLENA ontology.
- Answer
-
One could make a Content ODP out of it: for each
AssistiveDevicethat is added to the ontology, one also has to record theDisabilityitameliorates, itrequiressomeAbilityto use/operate the device, and performs a certainFunction. With that combination, one even can create some sort of an ‘input form’ for domain experts and administrators, which can then hide all the logic entirely, yet as long as they follow the pattern, the information gets represented as intended.Another one that may be useful is the Architectural OP:
adolena.owlnow contains some bits and pieces of both DOLCE (endurant, perdurant, and some of their subclasses) and some terms from BFO (realizable), neither of the two ontologies were imported. The architectural ODP can help cleaning this us and structuring it.
Exercise \(\PageIndex{15}\)
Figure 7.7.1 shows a content OP. How would you evaluate whether this is a good ODP? In doing so, describe your reasoning why it is, or is not, a good ODP.
- Answer
-
One could check the design against a foundational ontology and check whether the instantiations makes sense. There may be more options to evaluate it, as there has not been done much work on ODP quality.
Exercise \(\PageIndex{16}\)
Discuss the feasibility of the following combinations of requirements for an ontology-driven information system (and make an informed guess about the unknowns):
a. Purpose: science; Language: OWL 2 DL, or an extension thereof; Reuse: foundational; Bottom up: form textbook models; Reasoning services: standard and non-standard.
b. Purpose: querying data through an ontology; Language: some OWL 2; Reuse: reference; Bottom up: physical database schemas and tagging; Reasoning services: ontological and querying.
c. Purpose: ontology-driven NLP; Language: OWL 2 EL; Reuse: unknown; Bottom up: a thesaurus and tagging experiments; Reasoning services: mainly just querying.
You may wish to consult [Kee10a] for a table about dependencies, or argue upfront first.
Exercise \(\PageIndex{17}\)
You are an ontology consultant and have to advise the clients on ontology development for the following scenario. What would your advice be, assuming there are sufficient resources to realize it? Consider topics such as language, reasoning services, bottom-up, top-down, methods/methodologies.
A pharmaceutical company is in the process of developing a drug to treat blood infections. There are about 100 candidate-chemicals in stock, categorised according to the BigPharmaChemicalsThesaurus, and they need to find out whether it meets their specification of the ‘ideal’ drug, codename DruTopiate, that has the required features to treat that disease (they already know that DruTopiate must have as part a benzene ring, must be water-soluble, smaller than 1 µm, etc). Instead of finding out by trial-and-error and test all 100 chemicals in the lab in costly experiments, they want to filter out candidate chemicals by automatic classification according to those DruTopiate features, and then experiment only with the few that match the desired properties. This in silico (on-the-computer) biomedical research is intended as a pilot study, and it is hoped that the successes obtained in related works, such as that of the protein phosphatases and ideal rubber molecules, can be achieved also in this case.
- Answer
-
Principally:
- expressive foundational ontology, such as DOLCE or GFO for improved ontology quality and interoperability
- bottom-up onto development from the thesaurus to OWL
- integration/import of existing bio-ontologies
- Domain ontology in OWL taking the classification of the chemicals, define domain & range and, ideally, defined concepts
- Add the instance data (the representation of the chemicals in stock) in the OWL ABox (there are only 100, so no real performance issues), and add a dummy class disjoint from
DruTopiatedestined for the ‘wrong’ chemicals - Take some suitable reasoner for OWL 2 DL (either the ‘standard’ reasoners or names like Fact\(++\))
- Then classify the instances availing of the available reasoning services (run Fact\(++\) etc.): those chemical classified as instances of the ‘ideal chemical’ are the candidate for the lab experiments for the drug to treat blood infections.
- Alternatively: add
DruTopiateas class, add the other chemicals as classes, and any classes subsumed byDruTopiateare the more likely chemicals, it’s parents the less likely chemicals. - Methods and methodologies that can be used: single, controlled ontology development, so something like METHONTOLOGY will do, and for the micro-level development something like OD101, ontospec, or DiDON.