
6.1: Appendix C- High Performance Microprocessors
- Page ID
- 13449

Introduction
High Performance Microprocessors
It has been said that history is rewritten by the victors. It is clear that high performance RISC-based microprocessors are defining the current history of high performance computing. We begin our study with the basic building blocks of modern high performance computing: the high performance RISC microprocessors.
A complex instruction set computer (CISC) instruction set is made up of powerful primitives, close in functionality to the primitives of high-level languages like C or FORTRAN. It captures the sense of “don’t do in software what you can do in hardware.” RISC, on the other hand, emphasizes low-level primitives, far below the complexity of a high-level language. You can compute anything you want using either approach, though it will probably take more machine instructions if you’re using RISC. The important difference is that with RISC you can trade instruction-set complexity for speed.
To be fair, RISC isn’t really all that new. There were some important early machines that pioneered RISC philosophies, such as the CDC 6600 (1964) and the IBM 801 project (1975). It was in the mid-1980s, however, that RISC machines first posed a direct challenge to the CISC installed base. Heated debate broke out — RISC versus CISC — and even lingers today, though it is clear that the RISC1 approach is in greatest favor; late-generation CISC machines are looking more RISC-like, and some very old families of CISC, such as the DEC VAX, are being retired.
This chapter is about CISC and RISC instruction set architectures and the differences between them. We also describe newer processors that can execute more than one instruction at a time and can execute instructions out of order.
Why CISC?
You might ask, “If RISC is faster, why did people bother with CISC designs in the first place?” The short answer is that in the beginning, CISC was the right way to go; RISC wasn’t always both feasible and affordable. Every kind of design incorporates trade-offs, and over time, the best systems will make them differently. In the past, the design variables favored CISC.
Space and Time
To start, we’ll ask you how well you know the assembly language for your work-station. The answer is probably that you haven’t even seen it. Why bother? Compilers and development tools are very good, and if you have a problem, you can debug it at the source level. However, 30 years ago, “respectable” programmers understood the machine’s instruction set. High-level language compilers were commonly available, but they didn’t generate the fastest code, and they weren’t terribly thrifty with memory. When programming, you needed to save both space and time, which meant you knew how to program in assembly language. Accordingly, you could develop an opinion about the machine’s instruction set. A good instruction set was both easy to use and powerful. In many ways these qualities were the same: “powerful” instructions accomplished a lot, and saved the programmer from specifying many little steps — which, in turn, made them easy to use. But they had other, less apparent (though perhaps more important) features as well: powerful instructions saved memory and time.
Back then, computers had very little storage by today’s standards. An instruction that could roll all the steps of a complex operation, such as a do-loop, into single opcode2 was a plus, because memory was precious. To put some stakes in the ground, consider the last vacuum-tube computer that IBM built, the model 704 (1956). It had hardware floating-point, including a division operation, index registers, and instructions that could operate directly on memory locations. For instance, you could add two numbers together and store the result back into memory with a single command. The Philco 2000, an early transistorized machine (1959), had an operation that could repeat a sequence of instructions until the contents of a counter was decremented to zero — very much like a do-loop. These were complex operations, even by today’s standards. However, both machines had a limited amount of memory — 32-K words. The less memory your program took up, the more you had available for data, and the less likely that you would have to resort to overlaying portions of the program on top of one another.
Complex instructions saved time, too. Almost every large computer following the IBM 704 had a memory system that was slower than its central processing unit (CPU). When a single instruction can perform several operations, the overall number of instructions retrieved from memory can be reduced. Minimizing the number of instructions was particularly important because, with few exceptions, the machines of the late 1950s were very sequential; not until the current instruction was completed did the computer initiate the process of going out to memory to get the next instruction.3 By contrast, modern machines form something of a bucket brigade — passing instructions in from memory and figuring out what they do on the way — so there are fewer gaps in processing.
If the designers of early machines had had very fast and abundant instruction memory, sophisticated compilers, and the wherewithal to build the instruction “bucket brigade” — cheaply — they might have chosen to create machines with simple instruction sets. At the time, however, technological choices indicated that instructions should be powerful and thrifty with memory.
Beliefs About Complex Instruction Sets
So, given that the lot was cast in favor of complex instruction sets, computer architects had license to experiment with matching them to the intended purposes of the machines. For instance, the do-loop instruction on the Philco 2000 looked like a good companion for procedural languages like FORTRAN. Machine designers assumed that compiler writers could generate object programs using these powerful machine instructions, or possibly that the compiler could be eliminated, and that the machine could execute source code directly in hardware.
You can imagine how these ideas set the tone for product marketing. Up until the early 1980s, it was common practice to equate a bigger instruction set with a more powerful computer. When clock speeds were increasing by multiples, no increase in instruction set complexity could fetter a new model of computer enough so that there wasn’t still a tremendous net increase in speed. CISC machines kept getting faster, in spite of the increased operation complexity.
As it turned out, assembly language programmers used the complicated machine instructions, but compilers generally did not. It was difficult enough to get a compiler to recognize when a complicated instruction could be used, but the real problem was one of optimizations: verbatim translation of source constructs isn’t very efficient. An optimizing compiler works by simplifying and eliminating redundant computations. After a pass through an optimizing compiler, opportunities to use the complicated instructions tend to disappear.
Fundamental of RISC
A RISC machine could have been built in 1960. (In fact, Seymour Cray built one in 1964 — the CDC 6600.) However, given the same costs of components, technical barriers, and even expectations for how computers would be used, you would probably still have chosen a CISC design — even with the benefit of hindsight.
The exact inspiration that led to developing high performance RISC microprocessors in the 1980s is a subject of some debate. Regardless of the motivation of the RISC designers, there were several obvious pressures that affected the development of RISC:
- The number of transistors that could fit on a single chip was increasing. It was clear that one would eventually be able to fit all the components from a processor board onto a single chip.
- Techniques such as pipelining were being explored to improve performance. Variable-length instructions and variable-length instruction execution times (due to varying numbers of microcode steps) made implementing pipelines more difficult.
- As compilers improved, they found that well-optimized sequences of stream- lined instructions often outperformed the equivalent complicated multi-cycle instructions. (See Appendix A, Processor Architectures, and Appendix B, Looking at Assembly Language.)
The RISC designers sought to create a high performance single-chip processor with a fast clock rate. When a CPU can fit on a single chip, its cost is decreased, its reliability is increased, and its clock speed can be increased. While not all RISC processors are single-chip implementation, most use a single chip.
To accomplish this task, it was necessary to discard the existing CISC instruction sets and develop a new minimal instruction set that could fit on a single chip. Hence the term reduced instruction set computer. In a sense reducing the instruction set was not an “end” but a means to an end.
For the first generation of RISC chips, the restrictions on the number of components that could be manufactured on a single chip were severe, forcing the designers to leave out hardware support for some instructions. The earliest RISC processors had no floating-point support in hardware, and some did not even support integer multiply in hardware. However, these instructions could be implemented using software routines that combined other instructions (a microcode of sorts).
These earliest RISC processors (most severely reduced) were not overwhelming successes for four reasons:
- It took time for compilers, operating systems, and user software to be retuned to take advantage of the new processors.
- If an application depended on the performance of one of the software-implemented instructions, its performance suffered dramatically.
- Because RISC instructions were simpler, more instructions were needed to accomplish the task.
- Because all the RISC instructions were 32 bits long, and commonly used CISC instructions were as short as 8 bits, RISC program executables were often larger.
As a result of these last two issues, a RISC program may have to fetch more memory for its instructions than a CISC program. This increased appetite for instructions actually clogged the memory bottleneck until sufficient caches were added to the RISC processors. In some sense, you could view the caches on RISC processors as the microcode store in a CISC processor. Both reduced the overall appetite for instructions that were loaded from memory.
While the RISC processor designers worked out these issues and the manufacturing capability improved, there was a battle between the existing (now called CISC) processors and the new RISC (not yet successful) processors. The CISC processor designers had mature designs and well-tuned popular software. They also kept adding performance tricks to their systems. By the time Motorola had evolved from the MC68000 in 1982 that was a CISC processor to the MC68040 in 1989, they referred to the MC68040 as a RISC processor.4
However, the RISC processors eventually became successful. As the amount of logic available on a single chip increased, floating-point operations were added back onto the chip. Some of the additional logic was used to add on-chip cache to solve some of the memory bottleneck problems due to the larger appetite for instruction memory. These and other changes moved the RISC architectures from the defensive to the offensive.
RISC processors quickly became known for their affordable high-speed floating- point capability compared to CISC processors.5 This excellent performance on scientific and engineering applications effectively created a new type of computer system, the workstation. Workstations were more expensive than personal computers but their cost was sufficiently low that workstations were heavily used in the CAD, graphics, and design areas. The emerging workstation market effectively created three new computer companies in Apollo, Sun Microsystems, and Silicon Graphics.
Some of the existing companies have created competitive RISC processors in addition to their CISC designs. IBM developed its RS-6000 (RIOS) processor, which had excellent floating-point performance. The Alpha from DEC has excellent performance in a number of computing benchmarks. Hewlett-Packard has developed the PA-RISC series of processors with excellent performance. Motorola and IBM have teamed to develop the PowerPC series of RISC processors that are used in IBM and Apple systems.
By the end of the RISC revolution, the performance of RISC processors was so impressive that single and multiprocessor RISC-based server systems quickly took over the minicomputer market and are currently encroaching on the traditional mainframe market.
Characterizing RISC
RISC is more of a design philosophy than a set of goals. Of course every RISC processor has its own personality. However, there are a number of features commonly found in machines people consider to be RISC:
- Instruction pipelining
- Pipelining floating-point execution
- Uniform instruction length
- Delayed branching
- Load/store architecture
- Simple addressing modes
This list highlights the differences between RISC and CISC processors. Naturally, the two types of instruction-set architectures have much in common; each uses registers, memory, etc. And many of these techniques are used in CISC machines too, such as caches and instruction pipelines. It is the fundamental differences that give RISC its speed advantage: focusing on a smaller set of less powerful instructions makes it possible to build a faster computer.
However, the notion that RISC machines are generally simpler than CISC machines isn’t correct. Other features, such as functional pipelines, sophisticated memory systems, and the ability to issue two or more instructions per clock make the latest RISC processors the most complicated ever built. Furthermore, much of the complexity that has been lifted from the instruction set has been driven into the compilers, making a good optimizing compiler a prerequisite for machine performance.
Let’s put ourselves in the role of computer architect again and look at each item in the list above to understand why it’s important.
Pipelines
Everything within a digital computer (RISC or CISC) happens in step with a clock: a signal that paces the computer’s circuitry. The rate of the clock, or clock speed, determines the overall speed of the processor. There is an upper limit to how fast you can clock a given computer.
A number of parameters place an upper limit on the clock speed, including the semiconductor technology, packaging, the length of wires tying the pieces together, and the longest path in the processor. Although it may be possible to reach blazing speed by optimizing all of the parameters, the cost can be prohibitive. Furthermore, exotic computers don’t make good office mates; they can require too much power, produce too much noise and heat, or be too large. There is incentive for manufacturers to stick with manufacturable and marketable technologies.
Reducing the number of clock ticks it takes to execute an individual instruction is a good idea, though cost and practicality become issues beyond a certain point. A greater benefit comes from partially overlapping instructions so that more than one can be in progress simultaneously. For instance, if you have two additions to perform, it would be nice to execute them both at the same time. How do you do that? The first, and perhaps most obvious, approach, would be to start them simultaneously. Two additions would execute together and complete together in the amount of time it takes to perform one. As a result, the throughput would be effectively doubled. The downside is that you would need hardware for two adders in a situation where space is usually at a premium (especially for the early RISC processors).
Other approaches for overlapping execution are more cost-effective than side-by-side execution. Imagine what it would be like if, a moment after launching one operation, you could launch another without waiting for the first to complete. Perhaps you could start another of the same type right behind the first one — like the two additions. This would give you nearly the performance of side-by-side execution without duplicated hardware. Such a mechanism does exist to varying degrees in all computers — CISC and RISC. It’s called a pipeline. A pipeline takes advantage of the fact that many operations are divided into identifiable steps, each of which uses different resources on the processor.6

[Figure 1] shows a conceptual diagram of a pipeline. An operation entering at the left proceeds on its own for five clock ticks before emerging at the right. Given that the pipeline stages are independent of one another, up to five operations can be in flight at a time as long as each instruction is delayed long enough for the previous instruction to clear the pipeline stage. Consider how powerful this mechanism is: where before it would have taken five clock ticks to get a single result, a pipeline produces as much as one result every clock tick.
Pipelining is useful when a procedure can be divided into stages. Instruction processing fits into that category. The job of retrieving an instruction from memory, figuring out what it does, and doing it are separate steps we usually lump together when we talk about executing an instruction. The number of steps varies, depending on whose processor you are using, but for illustration, let’s say there are five:
- Instruction fetch: The processor fetches an instruction from memory.
- Instruction decode: The instruction is recognized or decoded.
- Operand Fetch: The processor fetches the operands the instruction needs. These operands may be in registers or in memory.
- Execute: The instruction gets executed.
- Writeback: The processor writes the results back to wherever they are supposed to go —possibly registers, possibly memory.
Ideally, instruction
- Will be entering the operand fetch stage as instruction
- enters instruction decode stage and instruction
- starts instruction fetch, and so on.
Our pipeline is five stages deep, so it should be possible to get five instructions in flight all at once. If we could keep it up, we would see one instruction complete per clock cycle.
Simple as this illustration seems, instruction pipelining is complicated in real life. Each step must be able to occur on different instructions simultaneously, and delays in any stage have to be coordinated with all those that follow. In [Figure 2] we see three instructions being executed simultaneously by the processor, with each instruction in a different stage of execution.

For instance, if a complicated memory access occurs in stage three, the instruction needs to be delayed before going on to stage four because it takes some time to calculate the operand’s address and retrieve it from memory. All the while, the rest of the pipeline is stalled. A simpler instruction, sitting in one of the earlier stages, can’t continue until the traffic ahead clears up.
Now imagine how a jump to a new program address, perhaps caused by an if statement, could disrupt the pipeline flow. The processor doesn’t know an instruction is a branch until the decode stage. It usually doesn’t know whether a branch will be taken or not until the execute stage. As shown in [Figure 3], during the four cycles after the branch instruction was fetched, the processor blindly fetches instructions sequentially and starts these instructions through the pipeline.
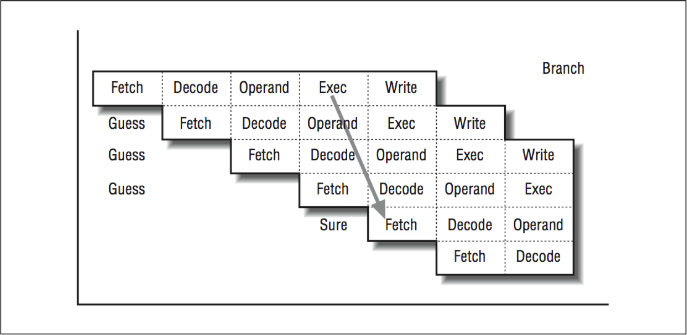
If the branch “falls through,” then everything is in great shape; the pipeline simply executes the next instruction. It’s as if the branch were a “no-op” instruction. However, if the branch jumps away, those three partially processed instructions never get executed. The first order of business is to discard these “in-flight” instructions from the pipeline. It turns out that because none of these instructions was actually going to do anything until its execute stage, we can throw them away without hurting anything (other than our efficiency). Somehow the processor has to be able to clear out the pipeline and restart the pipeline at the branch destination.
Unfortunately, branch instructions occur every five to ten instructions in many programs. If we executed a branch every fifth instruction and only half our branches fell through, the lost efficiency due to restarting the pipeline after the branches would be 20 percent.
You need optimal conditions to keep the pipeline moving. Even in less-than-optimal conditions, instruction pipelining is a big win — especially for RISC processors. Interestingly, the idea dates back to the late 1950s and early 1960s with the UNI- VAC LARC and the IBM Stretch. Instruction pipelining became mainstreamed in 1964, when the CDC 6600 and the IBM S/360 families were introduced with pipelined instruction units — on machines that represented RISC-ish and CISC designs, respectively. To this day, ever more sophisticated techniques are being applied to instruction pipelining, as machines that can overlap instruction execution become commonplace.
Pipelined Floating-Point Operations
Because the execution stage for floating-point operations can take longer than the execution stage for fixed-point computations, these operations are typically pipelined, too. Generally, this includes floating-point addition, subtraction, multiplication, comparisons, and conversions, though it might not include square roots and division. Once a pipelined floating-point operation is started, calculations continue through the several stages without delaying the rest of the processor. The result appears in a register at some point in the future.
Some processors are limited in the amount of overlap their floating-point pipelines can support. Internal components of the pipelines may be shared (for adding, multiplying, normalizing, and rounding intermediate results), forcing restrictions on when and how often you can begin new operations. In other cases, floating- point operations can be started every cycle regardless of the previous floating- point operations. We say that such operations are fully pipelined.
The number of stages in floating-point pipelines for affordable computers has decreased over the last 10 years. More transistors and newer algorithms make it possible to perform a floating-point addition or multiplication in just one to three cycles. Generally the most difficult instruction to perform in a single cycle is the floating-point multiply. However, if you dedicate enough hardware to it, there are designs that can operate in a single cycle at a moderate clock rate.
Uniform Instruction Length
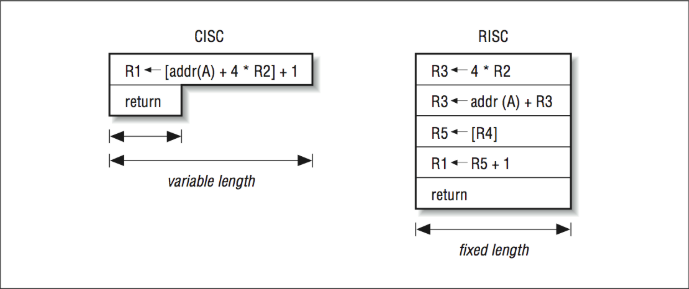
Our sample instruction pipeline had five stages: instruction fetch, instruction decode, operand fetch, execution, and writeback. We want this pipeline to be able to process five instructions in various stages without stalling. Decomposing each operation into five identifiable parts, each of which is roughly the same amount of time, is challenging enough for a RISC computer. For a designer working with a CISC instruction set, it’s especially difficult because CISC instructions come in varying lengths. A simple “return from subroutine” instruction might be one byte long, for instance, whereas it would take a longer instruction to say “add register four to memory location 2005 and leave the result in register five.” The number of bytes to be fetched must be known by the fetch stage of the pipeline as shown in [Figure 4].

The processor has no way of knowing how long an instruction will be until it reaches the decode stage and determines what it is. If it turns out to be a long instruction, the processor may have to go back to memory and get the portion left behind; this stalls the pipeline. We could eliminate the problem by requiring that all instructions be the same length, and that there be a limited number of instruction formats as shown in [Figure 5]. This way, every instruction entering the pipeline is known a priori to be complete — not needing another memory access. It would also be easier for the processor to locate the instruction fields that specify registers or constants. Altogether because RISC can assume a fixed instruction length, the pipeline flows much more smoothly.
Delayed Branches
As described earlier, branches are a significant problem in a pipelined architecture. Rather than take a penalty for cleaning out the pipeline after a misguessed branch, many RISC designs require an instruction after the branch. This instruction, in what is called the branch delay slot, is executed no matter what way the branch goes. An instruction in this position should be useful, or at least harmless, whichever way the branch proceeds. That is, you expect the processor to execute the instruction following the branch in either case, and plan for it. In a pinch, a no-op can be used. A slight variation would be to give the processor the ability to annul (or squash) the instruction appearing in the branch delay slot if it turns out that it shouldn’t have been issued after all:
ADD R1,R2,R1 add r1 to r2 and store in r1
SUB R3,R1,R3 subtract r1 from r3, store in r3
BRA SOMEWHERE branch somewhere else
LABEL1 ZERO R3 instruction in branch delay slot
...
While branch delay slots appeared to be a very clever solution to eliminating pipeline stalls associated with branch operations, as processors moved toward exe- cuting two and four instructions simultaneously, another approach was needed.7
A more robust way of eliminating pipeline stalls was to “predict” the direction of the branch using a table stored in the decode unit. As part of the decode stage, the CPU would notice that the instruction was a branch and consult a table that kept the recent behavior of the branch; it would then make a guess. Based on the guess, the CPU would immediately begin fetching at the predicted location. As long as the guesses were correct, branches cost exactly the same as any other instruction.
If the prediction was wrong, the instructions that were in process had to be can- celled, resulting in wasted time and effort. A simple branch prediction scheme is typically correct well over 90% of the time, significantly reducing the overall negative performance impact of pipeline stalls due to branches. All recent RISC designs incorporate some type of branch prediction, making branch delay slots effectively unnecessary.
Another mechanism for reducing branch penalties is conditional execution. These are instructions that look like branches in source code, but turn out to be a special type of instruction in the object code. They are very useful because they replace test and branch sequences altogether. The following lines of code capture the sense of a conditional branch:
IF ( B < C ) THEN
A = D
ELSE
A = E
ENDIF
Using branches, this would require at least two branches to ensure that the proper value ended up in A. Using conditional execution, one might generate code that looks as follows:
COMPARE B < C
IF TRUE A = D conditional instruction
IF FALSE A = E conditional instruction
This is a sequence of three instructions with no branches. One of the two assignments executes, and the other acts as a no-op. No branch prediction is needed, and the pipeline operates perfectly. There is a cost to taking this approach when there are a large number of instructions in one or the other branch paths that would seldom get executed using the traditional branch instruction model.
Load/Store Architecture
In a load/store instruction set architecture, memory references are limited to explicit load and store instructions. Each instruction may not make more than one memory reference per instruction. In a CISC processor, arithmetic and logical instructions can include embedded memory references. There are three reasons why limiting loads and stores to their own instructions is an improvement:
- First, we want all instructions to be the same length, for the reasons given above. However, fixed lengths impose a budget limit when it comes to describing what the operation does and which registers it uses. An instruction that both referenced memory and performed some calculation wouldn’t fit within one instruction word.
- Second, giving every instruction the option to reference memory would com- plicate the pipeline because there would be two computations to perform— the address calculation plus whatever the instruction is supposed to do — but there is only one execution stage. We could throw more hardware at it, but by restricting memory references to explicit loads and stores, we can avoid the problem entirely. Any instruction can perform an address calculation or some other operation, but no instruction can do both.
- The third reason for limiting memory references to explicit loads and stores is that they can take more time than other instructions — sometimes two or three clock cycles more. A general instruction with an embedded memory reference would get hung up in the operand fetch stage for those extra cycles, waiting for the reference to complete. Again we would be faced with an instruction pipeline stall.
Explicit load and store instructions can kick off memory references in the pipeline’s execute stage, to be completed at a later time (they might complete immediately; it depends on the processor and the cache). An operation downstream may require the result of the reference, but that’s all right, as long as it is far enough downstream that the reference has had time to complete.
Simple Addressing Modes
Just as we want to simplify the instruction set, we also want a simple set of memory addressing modes. The reasons are the same: complicated address calculations, or those that require multiple memory references, will take too much time and stall the pipeline. This doesn’t mean that your program can’t use elegant data structures; the compiler explicitly generates the extra address arithmetic when it needs it, as long as it can count on a few fundamental addressing modes in hardware. In fact, the extra address arithmetic is often easier for the compiler to optimize into faster forms (see [Section 5.2] and [Section 2.1.6]).
Of course, cutting back the number of addressing modes means that some memory references will take more real instructions than they might have taken on a CISC machine. However, because everything executes more quickly, it generally is still a performance win.
Second-Generation RISC Processors
The Holy Grail for early RISC machines was to achieve one instruction per clock. The idealized RISC computer running at, say, 50 MHz, would be able to issue 50 million instructions per second assuming perfect pipeline scheduling. As we have seen, a single instruction will take five or more clock ticks to get through the instruction pipeline, but if the pipeline can be kept full, the aggregate rate will, in fact, approach one instruction per clock. Once the basic pipelined RISC processor designs became successful, competition ensued to determine which company could build the best RISC processor.
Second-generation RISC designers used three basic methods to develop competitive RISC processors:
- Improve the manufacturing processes to simply make the clock rate faster. Take a simple design; make it smaller and faster. This approach was taken by the Alpha processors from DEC. Alpha processors typically have had clock rates double those of the closest competitor.
- Add duplicate compute elements on the space available as we can manufacture chips with more transistors. This could allow two instructions to be executed per cycle and could double performance without increasing clock rate. This technique is called superscalar.
- Increase the number of stages in the pipeline above five. If the instructions can truly be decomposed evenly into, say, ten stages, the clock rate could theoretically be doubled without requiring new manufacturing processes. This technique was called superpipelining. The MIPS processors used this technique with some success.
Superscalar Processors
The way you get two or more instructions per clock is by starting several operations side by side, possibly in separate pipelines. In [Figure 6], if you have an integer addition and a multiplication to perform, it should be possible to begin them simultaneously, provided they are independent of each other (as long as the multiplication does not need the output of the addition as one of its operands or vice versa). You could also execute multiple fixed-point instructions — compares, integer additions, etc. — at the same time, provided that they, too, are independent. Another term used to describe superscalar processors is multiple instruction issue processors.

The number and variety of operations that can be run in parallel depends on both the program and the processor. The program has to have enough usable parallelism so that there are multiple things to do, and the processor has to have an appropriate assortment of functional units and the ability to keep them busy. The idea is conceptually simple, but it can be a challenge for both hardware designers and compiler writers. Every opportunity to do several things in parallel exposes the danger of violating some precedence (i.e., performing computations in the wrong order).
Superpipelined Processors
Roughly stated, simpler circuitry can run at higher clock speeds. Put yourself in the role of a CPU designer again. Looking at the instruction pipeline of your processor, you might decide that the reason you can’t get more speed out of it is that some of the stages are too complicated or have too much going on, and they are placing limits on how fast the whole pipeline can go. Because the stages are clocked in unison, the slowest of them forms a weak link in the chain.
If you divide the complicated stages into less complicated portions, you can increase the overall speed of the pipeline. This is called superpipelining. More instruction pipeline stages with less complexity per stage will do the same work as a pipelined processor, but with higher throughput due to increased clock speed. [Figure 7] shows an eight-stage pipeline used in the MIPS R4000 processor.

Theoretically, if the reduced complexity allows the processor to clock faster, you can achieve nearly the same performance as superscalar processors, yet without instruction mix preferences. For illustration, picture a superscalar processor with two units — fixed- and floating-point — executing a program that is composed solely of fixed-point calculations; the floating-point unit goes unused. This reduces the superscalar performance by one half compared to its theoretical maximum. A superpipelined processor, on the other hand, will be perfectly happy to handle an unbalanced instruction mix at full speed.
Superpipelines are not new; deep pipelines have been employed in the past, notably on the CDC 6600. The label is a marketing creation to draw contrast to superscalar processing, and other forms of efficient, high-speed computing.
Superpipelining can be combined with other approaches. You could have a superscalar machine with deep pipelines (DEC AXP and MIPS R-8000 are examples). In fact, you should probably expect that faster pipelines with more stages will become so commonplace that nobody will remember to call them superpipelines after a while.
RISC Means Fast
We all know that the “R” in RISC means “reduced.” Lately, as the number of components that can be manufactured on a chip has increased, CPU designers have been looking at ways to make their processors faster by adding features. We have already talked about many of the features such as on-chip multipliers, very fast floating-point, lots of registers, and on-chip caches. Even with all of these features, there seems to be space left over. Also, because much of the design of the control section of the processor is automated, it might not be so bad to add just a “few” new instructions here and there. Especially if simulations indicate a 10% overall increase in speed!
So, what does it mean when they add 15 instructions to a RISC instruction set architecture (ISA)? Would we call it “not-so-RISC”? A suggested term for this trend is FISC, or fast instruction set computer. The point is that reducing the number of instructions is not the goal. The goal is to build the fastest possible processor within the manufacturing and cost constraints.8
Some of the types of instructions that are being added into architectures include:
- More addressing modes
- Meta-instructions such as “decrement counter and branch if non-zero”
- Specialized graphics instructions such as the Sun VIS set, the HP graphics instructions, the MIPS Digital Media Extentions (MDMX), and the Intel MMX instructions
Interestingly, the reason that the first two are feasible is that adder units take up so little space, it is possible to put one adder into the decode unit and another into the load/store unit. Most visualization instruction sets take up very little chip area. They often provide “ganged” 8-bit computations to allow a 64-bit register to be used to perform eight 8-bit operations in a single instruction.
Out-of-Order Execution: The Post-RISC Architecture
We’re never satisfied with the performance level of our computing equipment and neither are the processor designers. Two-way superscalar processors were very successful around 1994. Many designs were able to execute 1.6–1.8 instructions per cycle on average, using all of the tricks described so far. As we became able to manufacture chips with an ever-increasing transistor count, it seemed that we would naturally progress to four-way and then eight-way superscalar processors. The fundamental problem we face when trying to keep four functional units busy is that it’s difficult to find contiguous sets of four (or eight) instructions that can be executed in parallel. It’s an easy cop-out to say, “the compiler will solve it all.”
The solution to these problems that will allow these processors to effectively use four functional units per cycle and hide memory latency is out-of-order execution and speculative execution. Out-of-order execution allows a later instruction to be processed before an earlier instruction is completed. The processor is “betting” that the instruction will execute, and the processor will have the precomputed “answer” the instruction needs. In some ways, portions of the RISC design philosophy are turned inside-out in these new processors.
Speculative Computation
To understand the post-RISC architecture, it is important to separate the concept of computing a value for an instruction and actually executing the instruction. Let’s look at a simple example:
LD R10,R2(R0) Load into R10 from memory ... 30 Instructions of various kinds (not FDIV) FDIV R4,R5,R6 R4 = R5 / R6
Assume that (1) we are executing the load instruction, (2) R5 and R6 are already loaded from earlier instructions, (3) it takes 30 cycles to do a floating-point divide, and (4) there are no instructions that need the divide unit between the LD and the FDIV. Why not start the divide unit computing the FDIV right now, storing the result in some temporary scratch area? It has nothing better to do. When or if we arrive at the FDIV, we will know the result of the calculation, copy the scratch area into R4, and the FDIV will appear to execute in one cycle. Sound farfetched? Not for a post-RISC processor.
The post-RISC processor must be able to speculatively compute results before the processor knows whether or not an instruction will actually execute. It accomplishes this by allowing instructions to start that will never finish and allowing later instructions to start before earlier instructions finish.
To store these instructions that are in limbo between started and finished, the post-RISC processor needs some space on the processor. This space for instructions is called the instruction reorder buffer (IRB).
The Post-RISC Pipeline
The post-RISC processor pipeline in [Figure 8] looks somewhat different from the RISC pipeline. The first two stages are still instruction fetch and decode. Decode includes branch prediction using a table that indicates the probable behavior of a branch. Once instructions are decoded and branches are predicted, the instructions are placed into the IRB to be computed as soon as possible.

The IRB holds up to 60 or so instructions that are waiting to execute for one reason or another. In a sense, the fetch and decode/predict phases operate until the buffer fills up. Each time the decode unit predicts a branch, the following instructions are marked with a different indicator so they can be found easily if the prediction turns out to be wrong. Within the buffer, instructions are allowed to go to the computational units when the instruction has all of its operand values. Because the instructions are computing results without being executed, any instruction that has its input values and an available computation unit can be computed. The results of these computations are stored in extra registers not visible to the programmer called rename registers. The processor allocates rename registers, as they are needed for instructions being computed.
The execution units may have one or more pipeline stages, depending on the type of the instruction. This part looks very much like traditional superscalar RISC processors. Typically up to four instructions can begin computation from the IRB in any cycle, provided four instructions are available with input operands and there are sufficient computational units for those instructions.
Once the results for the instruction have been computed and stored in a rename register, the instruction must wait until the preceding instructions finish so we know that the instruction actually executes. In addition to the computed results, each instruction has flags associated with it, such as exceptions. For example, you would not be happy if your program crashed with the following message: “Error, divide by zero. I was precomputing a divide in case you got to the instruction to save some time, but the branch was mispredicted and it turned out that you were never going to execute that divide anyway. I still had to blow you up though. No hard feelings? Signed, the post-RISC CPU.” So when a speculatively computed instruction divides by zero, the CPU must simply store that fact until it knows the instruction will execute and at that moment, the program can be legitimately crashed.
If a branch does get mispredicted, a lot of bookkeeping must occur very quickly. A message is sent to all the units to discard instructions that are part of all control flow paths beyond the incorrect branch.
Instead of calling the last phase of the pipeline “writeback,” it’s called “retire.” The retire phase is what “executes” the instructions that have already been computed. The retire phase keeps track of the instruction execution order and retires the instructions in program order, posting results from the rename registers to the actual registers and raising exceptions as necessary. Typically up to four instructions can be retired per cycle.
So the post-RISC pipeline is actually three pipelines connected by two buffers that allow instructions to be processed out of order. However, even with all of this speculative computation going on, the retire unit forces the processor to appear as a simple RISC processor with predictable execution and interrupts.
Closing Notes
Congratulations for reaching the end of a long chapter! We have talked a little bit about old computers, CISC, RISC, post-RISC, and EPIC, and mentioned supercomputers in passing. I think it’s interesting to observe that RISC processors are a branch off a long-established tree. Many of the ideas that have gone into RISC designs are borrowed from other types of computers, but none of them evolved into RISC — RISC started at a discontinuity. There were hints of a RISC revolution (the CDC 6600 and the IBM 801 project) but it really was forced on the world (for its own good) by CPU designers at Berkeley and Stanford in the 1980s.
As RISC has matured, there have been many improvements. Each time it appears that we have reached the limit of the performance of our microprocessors there is a new architectural breakthrough improving our single CPU performance. How long can it continue? It is clear that as long as competition continues, there is significant performance headroom using the out-of-order execution as the clock rates move from a typical 200 MHz to 500+ MHz. DEC’s Alpha 21264 is planned to have four-way out-of-order execution at 500 MHz by 1998. As of 1998, vendors are beginning to reveal their plans for processors clocked at 1000 MHz or 1 GHz.
Unfortunately, developing a new processor is a very expensive task. If enough companies merge and competition diminishes, the rate of innovation will slow. Hopefully we will be seeing four processors on a chip, each 16-way out-of-order superscalar, clocked at 1 GHz for $200 before we eliminate competition and let the CPU designers rest on their laurels. At that point, scalable parallel processing will suddenly become interesting again.
How will designers tackle some of the fundamental architectural problems, perhaps the largest being memory systems? Even though the post-RISC architecture and the EPIC alleviate the latency problems somewhat, the memory bottleneck will always be there. The good news is that even though memory performance improves more slowly than CPU performance, memory system performance does improve over time. We’ll look next at techniques for building memory systems.
As discussed in [Section 0.2], the exercises that come at the end of most chapters in this book are not like the exercises in most engineering texts. These exercises are mostly thought experiments, without well-defined answers, designed to get you thinking about the hardware on your desk.
Exercises
Exercise \(\PageIndex{1}\)
Speculative execution is safe for certain types of instructions; results can be discarded if it turns out that the instruction shouldn’t have executed. Floating- point instructions and memory operations are two classes of instructions for which speculative execution is trickier, particularly because of the chance of generating exceptions. For instance, dividing by zero or taking the square root of a negative number causes an exception. Under what circumstances will a speculative memory reference cause an exception?
Exercise \(\PageIndex{2}\)
Picture a machine with floating-point pipelines that are 100 stages deep (that’s ridiculously deep), each of which can deliver a new result every nanosecond. That would give each pipeline a peak throughput rate of 1 Gflop, and a worst- case throughput rate of 10 Mflops. What characteristics would a program need to have to take advantage of such a pipeline?
Footnotes
- One of the most interesting remaining topics is the definition of “RISC.” Don’t be fooled into thinking there is one definition of RISC. The best I have heard so far is from John Mashey: “RISC is a label most commonly used for a set of instruction set architecture characteristics chosen to ease the use of aggressive implementation techniques found in high performance processors (regardless of RISC, CISC, or irrelevant).”
- Opcode = operation code = instruction.
- In 1955, IBM began constructing a machine known as Stretch. It was the first computer to process several instructions at a time in stages, so that they streamed in, rather than being fetched in a piecemeal fashion. The goal was to make it 25 times faster than the then brand-new IBM 704. It was six years before the first Stretch was delivered to Los Alamos National Laboratory. It was indeed faster, but it was expensive to build. Eight were sold for a loss of $20 million.
- And they did it without ever taking out a single instruction!
- The typical CISC microprocessor in the 1980s supported floating-point operations in a separate coprocessor.
- Here is a simple analogy: imagine a line at a fast-food drive up window. If there is only one window, one customer orders and pays, and the food is bagged and delivered to the customer before the second customer orders. For busier restaurants, there are three windows. First you order, then move ahead. Then at a second window, you pay and move ahead. At the third window you pull up, grab the food and roar off into the distance. While your wait at the three-window (pipelined) drive-up may have been slightly longer than your wait at the one-window (non-pipelined) restaurant, the pipeline solution is significantly better because multiple customers are being processed simultaneously.
- Interestingly, while the delay slot is no longer critical in processors that execute four instructions simultaneously, there is not yet a strong reason to remove the feature. Removing the delay slot would be nonupwards-compatible, breaking many existing codes. To some degree, the branch delay slot has become “baggage” on those “new” 10-year-old architectures that must continue to support it.
- People will argue forever but, in a sense, reducing the instruction set was never an end in itself, it was a means to an end.