
26.1 Labeled and Unlabeled examples
- Page ID
- 88785

In the activity of classification, the target variable we aim to predict is categorical. We sometimes also call this variable the label. Since this is a supervised process, we are provided with example objects of study that have known “true answers.” These are called labeled examples. The goal of the activity is to produce good predictions of the labels for other, unlabeled examples. A program that can make such predictions, after having studied the labeled examples, is called a classifier.
The predicted label can be seen as the “output” from our classifier. All of the other variables are essentially the inputs to our process, which we use to make our predictions. These variables are called features (or sometimes, attributes).
In terms of Pandas data structures, all these labeled examples will normally come packaged in a DataFrame. Each row of the DataFrame will be one labeled example, with its features as columns and its target/label as a column (traditionally, the rightmost one).
This is illustrated in Figure 26.1. Here we have some labeled examples for a data set on NFL fans. Each row represents one fan, and shows various features of their existence – how old they are, where they were born, where they live now, and how many years they’ve lived in their current residence. The rightmost column gives the target: the team to whom this fan has sworn their allegiance. Our aim would be to predict which team a fan might root for, based on what we know about them. Lest you think this example is frivolous, consider that a sporting goods company might want to send catalogs (paper or electronic) to potential customers, and it would probably boost sales if the cover image of the catalog featured a model wearing apparel from the customer’s favorite team, rather than their rival.
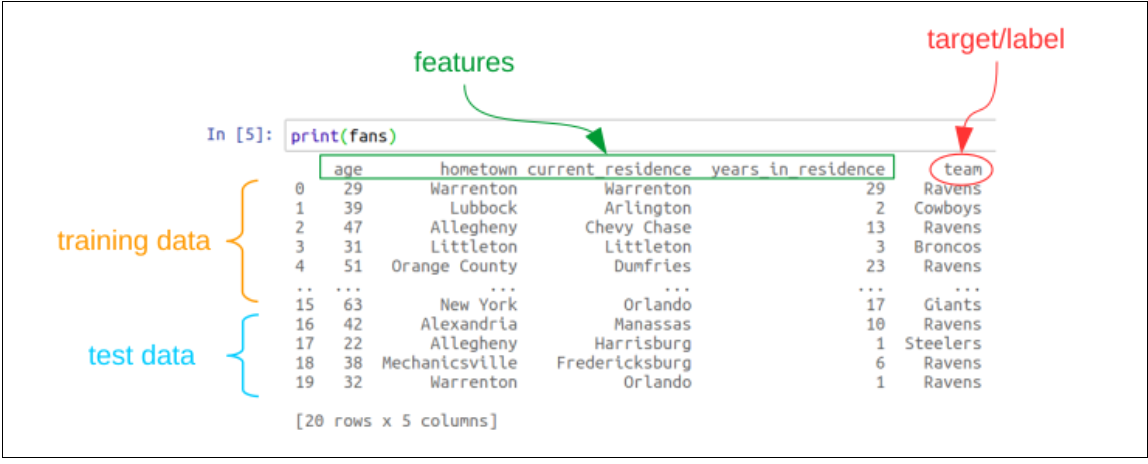
You’ll also see in the figure that I’ve split the rows up into two groups. The first group is called the training data, and the second, the test data. (Normally we’ll shuffle all the rows before assigning them, so that we don’t put all the top rows of the DataFrame in the training set and all the bottom ones in the test set. But that’s harder to show in a picture.)