
12.4: Data Partitioning
- Page ID
- 93723
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
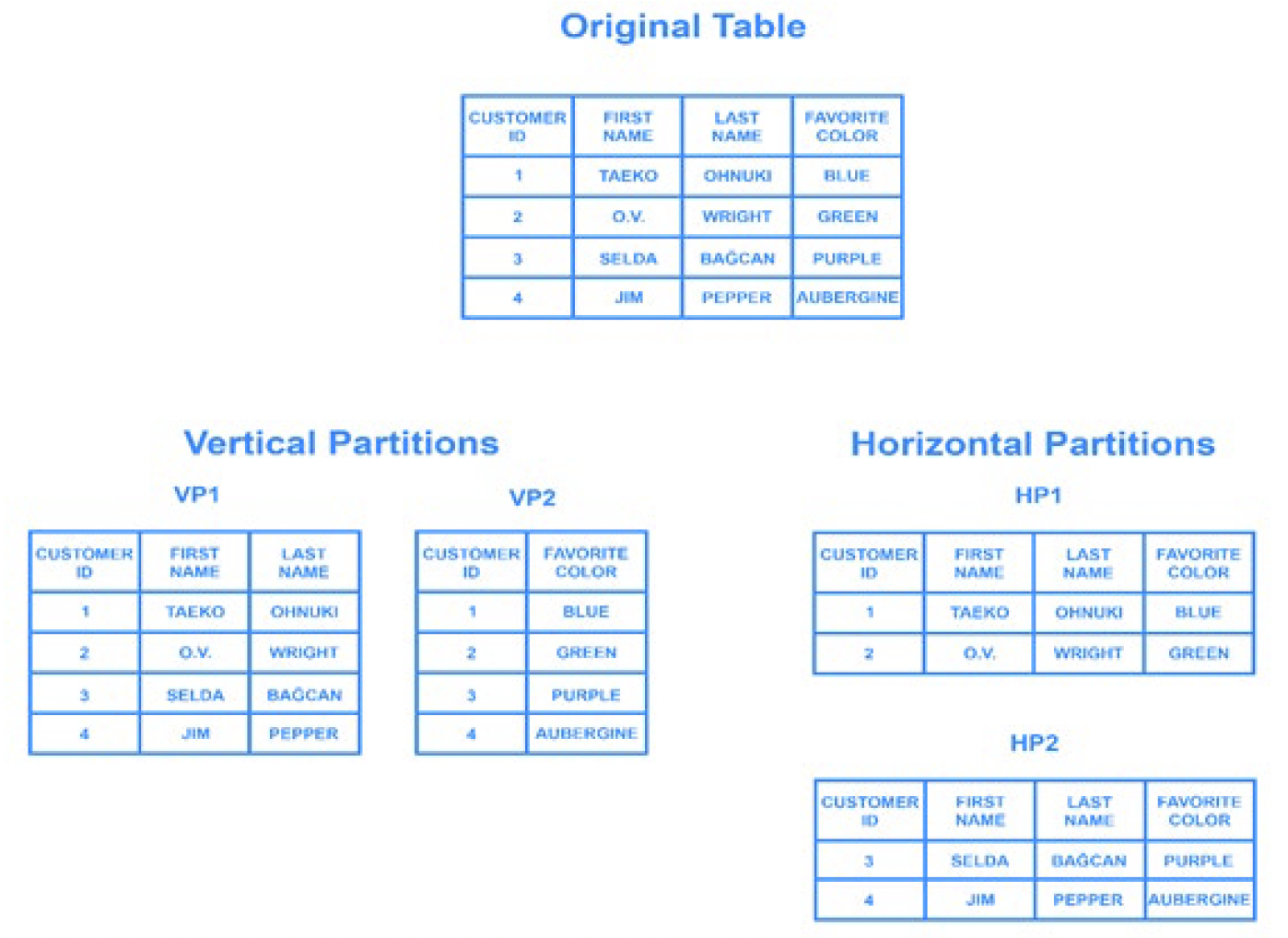
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Partitioning is a concept in databases in which very large tables and data are partitioned into smaller, individual tables, and queries which helps the data process more quickly and efficiently. One form of partitioning is called horizontal partitioning. Horizontal partitioning is the classification of the rows based on common characteristics into several, separate tables. For example, students with scores less than 70 might be stored in the FAIL table, while students who scored greater than 70 might be stored in the PASS table. The two partitioned tables would be FAIL and PASS. In doing so, the database is partitioned into two tables, both of which will be processed more quickly than a single table. The two typical methods of horizontal partitioning are to partition a sole column value and to partition the date (as the date helps organize the query chronologically). The keyword SELECT represents a horizontal partition in SQL. Below is an example of what horizontal partitioning would look like in SQL in which the first name, last name, class number and grade are specifically chosen as desired values:
SELECT viewClassGradeReport.[FirstName],
viewClassGradeReport.[LastName],
viewClassGradeReport.[ClassName],
viewClassGradeReport.[Grade] FROM viewClassGradeReport;
The Oracle DBMS (Database Management System) provides support for multiple forms of partitioning. The first one is range partitioning. In range partitioning, each partitioned portion is characterized by a range of values for one or multiple columns, such as IDs or dates. For instance, rows for a column titled COUNTRY containing India, Sri Lanka, Pakistan, Nepal, and Bangladesh could be a partition for South Asian countries
The next form of partitioning is hash partitioning. Hash partitioning is the spreading of data in even partitions autonomous of the key value. Hash partitioning outperforms the uneven distributions or rows.
The next partitioning is known as list partitioning. List partitioning is a technique where a list of distinct values is defined as the partitioning key in the characterization for each partition.
The best use of list partitioning is when one requires specifically to highlight rows established on discrete values. For instance, a global distributor may only want data regarding deliveries to China and Japan while ignoring deliveries to other nations.
Oracle provides another form of partitioning known as composite partitioning. Composite partitioning is a combination of the general data allocation methods in which a table is partitioned using one allocation method, and then each partition is subdivided into smaller partitions through another general allocation method.
The counterpart of horizontal partitioning, vertical partitioning is another form of partitioning. Vertical partitioning, as opposed to horizontal partitioning, is the distribution of columns based on their commonalities and separating them into independent tables. Vertical partitioning helps identify the dynamic data from the stable, immutable data. Vertical partitioning is represented with the keyword PROJECT.
Partitioning is a useful tool that helps with the design of the database and has many advantages. Partitioning is practical and helps manage the table because partitioning helps identify the area where maintenance is needed and saves storage space. Partitioning is also secure, as only the relevant and necessary data can be specifically chosen and accessed by the user. Another benefit of implementing partitioning is that backing up and securing files is easier due to their smaller size, and if one file is corrupted, the other is still accessible. Partitioning works similarly with cars and replaceable parts: if one piece of equipment is damaged, the rest of the car will still be functioning. Partitioning also helps with balancing the load. The partitioned files can be designated to different storage locations, reducing conflict and maximizing performance.
Although partitioning proves to be quite handy, it does have its drawbacks. The first drawback of partitioning is the inconsistency of the access speed that it provides. All partitions are not identical; therefore, depending on the data the specific partition consists, access speeds will differ. Another drawback is complexity. Due to the complex nature of partitions, the code required to program will need to be more complex and challenging to maintain. The final disadvantage of partitioning is the excess storage space and time. Data can be replicated multiple times, which in turn takes up storage and can affect the time taken to process.
Partitioning is a useful tool that helps with the design of the database and has many advantages. Partitioning is practical and helps manage the table because partitioning helps identify the area where maintenance is needed and saves storage space. Partitioning is also secure, as only the relevant and necessary data can be specifically chosen and accessed by the user. Another benefit of implementing partitioning is that backing up and securing files is easier due to their smaller size, and if one file is corrupted, the other is still accessible. Partitioning works similarly with cars and replaceable parts: if one piece of equipment is damaged, the rest of the car will still be functioning. Partitioning also helps with balancing the load. The partitioned files can be designated to different storage locations, reducing conflict and maximizing performance.
Although partitioning proves to be quite handy, it does have its drawbacks. The first drawback of partitioning is the inconsistency of the access speed that it provides. All partitions are not identical; therefore, depending on the data the specific partition consists, access speeds will differ. Another drawback is complexity. Due to the complex nature of partitions, the code required to program will need to be more complex and challenging to maintain. The final disadvantage of partitioning is the excess storage space and time. Data can be
Sharding, by Digital Ocean, Copyright 2020 by Digital Ocean
The user view, in a database, is a tool that helps visualize the tables in a database. Using the user view, physical tables can be partitioned coherently. The main intention of utilizing the user view is that it simplifies query editing and develops a secure database. In Oracle, a form of user view is offered called partition view, which displays physically partitioned tables that can be logically merged into one using the SQL union operator. This manner of partitioning does have its limitations. Firstly, there should not be any global index. Second, the physical tables should be independently handled. Lastly, fewer choices are at your disposal with partition view.