Matrix Description
It is important that each step in the Winograd FFT can be described using matrices. By expressing cyclic convolution as a bilinear form, a compact form of prime length DFTs can be obtained.
If \(y\) is the cyclic convolution of \(h\) and \(x\), then \(y\) can be expressed as
\[y=C\left [ Ax.\ast Bh \right ] \nonumber \]
where, using the Matlab convention, .* represents point by point multiplication. When \(A\), \(B\) and \(C\) are allowed to be complex, \(A\) and \(B\) are seen to be the DFT operator and \(C\), the inverse DFT. When only real numbers are allowed, \(A\), \(B\) and \(C\) will be rectangular. Using the matrix exchange property this form can be written as
\[y=RB^{T}\left [ C^{T}Rh.\ast Ax \right ] \nonumber \]
where \(R\) is the permutation matrix that reverses order.
When \(h\) is fixed, as it is when considering prime length DFTs, the term \(C^TRh\) can be precomputed and a diagonal matrix \(D\) formed by
\[D=diag{C^{T}Rh} \nonumber \]
This is advantageous because in general, \(C\) is more complicated than \(B\), so the ability to “hide" \(C\) saves computation. Now y=RBTDAxy=RBTDAx" role="presentation" style="position:relative;" tabindex="0">
\[y=RB^{T}DAx\; \; or\; \; y=RA^{T}DAx \nonumber \]
since \(A\) and \(B\) can be the same; they implement a polynomial reduction. The form \(y=R^{T}DAxT\) can also be used for the prime length DFTs, it is only necessary to permute the entries of \(x\) and to ensure that the \(DC\) term is computed correctly. The computation of the \(DC\) term is simple, for the residue of a polynomial modulo \(a-1\) is always the sum of the coefficients. After adding the \(x_0\) term of the original input sequence, to the \(s-1\) residue, the \(DC\) term is obtained. Now
\[DFT\left \{ x \right \}=RA^{T}DAx \nonumber \]
Johnson observes that by permuting the elements on the diagonal of \(D\), the output can be permuted, so that the \(R\) matrix can be hidden in \(D\), and
DFT{x}=ATDAxDFT{x}=ATDAx" role="presentation" style="position:relative;" tabindex="0">\[DFT\left \{ x \right \}=A^{T}DAx \nonumber \]
From the knowledge of this form, once \(A\) is found, \(D\) can be found numerically.
Programming the Design Procedure
Because each of the above steps can be described by matrices, the development of a prime length FFTs is made convenient with the use of a matrix oriented programming language such as Matlab. After specifying the appropriate matrices that describe the desired FFT algorithm, generating code involves compiling the matrices into the desired code for execution.
Each matrix is a section of one stage of the flow graph that corresponds to the DFT program. The four stages are:
- Permutation Stage: Permutes input and output sequence.
- Reduction Stage: Reduces the cyclic convolution to smaller polynomial products.
- Polynomial Product Stage: Performs the polynomial multiplications.
- Multiplication Stage: Implements the point-by-point multiplication in the bilinear form.
Each of the stages can be clearly seen in the flow graphs for the DFTs. Fig. 6.5.1 shows the flow graph for a length \(17\) DFT algorithm that was automatically drawn by the program.
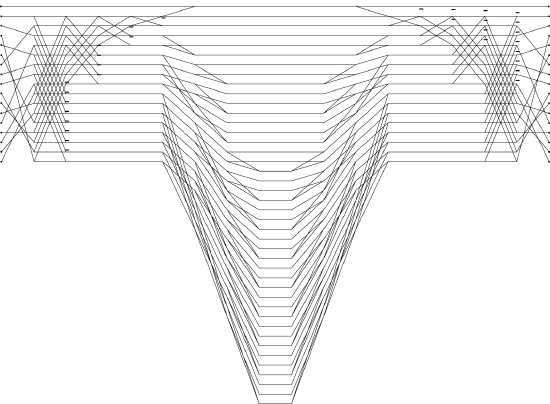
Fig. 6.5.1 Flowgraph of length-17 DFT
The programs that accomplish this process are written in Matlab and C. Those that compute the appropriate matrices are written in Matlab. These matrices are then stored as two ASCII files, with the dimensions in one and the matrix elements in the second. A C program then reads the flies and compiles them to produce the final FFT program in C.
The Reduction Stage
The reduction of an \(N^{th}\) degree polynomial, \(X(s)\), modulo the cyclotomic polynomial factors of (\(s^N-1\)) requires only additions for many \(N\), however, the actual number of additions depends upon the way in which the reduction proceeds. The reduction is most efficiently performed in steps. For example,
\[If\; \; N=4\; \; and\; \; ((X(s)))_{s-1},\; \; ((X(s)))_{s+1}\; \; and\; \; ((X(s)))_{s^{2}+1}, \nonumber \]
where the double parenthesis denote polynomial reduction modulo (s-1)(s-1)" role="presentation" style="position:relative;" tabindex="0">
\[(s-1),\; \; (s+1),\; \; and\; \; (s^{2}+1) \nonumber \]
then in the first step
((X(s)))s2-1((X(s)))s2-1" role="presentation" style="position:relative;" tabindex="0">\[((X(s)))_{s^{2}-1}\; \; and\; \; ((X(s)))_{s^{2}+1} \nonumber \]
should be computed.
In the second step,
((Xs)))s-1((Xs)))s-1" role="presentation" style="position:relative;" tabindex="0">\[((X(s)))_{s-1}\; \; and\; \; ((X(s)))_{s+1} \nonumber \]
can be found by reducing ((X(s)))s2-1((X(s)))s2-1" role="presentation" style="position:relative;" tabindex="0">
\[((X(s)))_{s^{2}-1} \nonumber \]
This process is described by the diagram in Fig. 6.5.2 below.
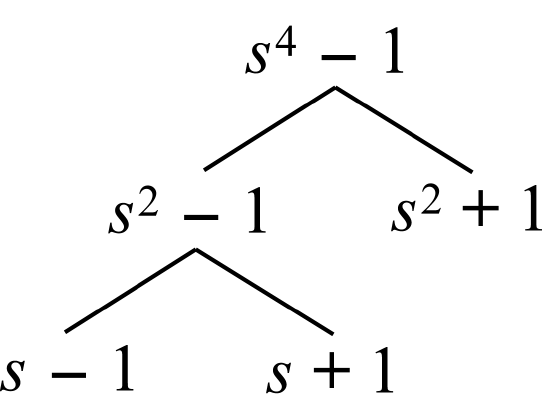
Fig. 6.5.2 Factorization of s4-1 in steps
When \(N\) is even, the appropriate first factorization is
(SN/2-1)(sN/2+1)(SN/2-1)(sN/2+1)" role="presentation" style="position:relative;" tabindex="0">\[(S^{N/2}-1)(S^{N/2}+1) \nonumber \]
However, the next appropriate factorization is frequently less obvious. The following procedure has been found to generate a factorization in steps that coincides with the factorization that minimizes the cumulative number of additions incurred by the steps. The prime factors of \(N\) are the basis of this procedure and their importance is clear from the useful well-known equation:
\[s^{N}-1=\prod _{n\mid N}C_{n}(s) \nonumber \]
where \(C_n(s)\) is the \(n^{th}\) cyclotomic polynomial.
We first introduce the following two functions defined on the positive integers,
\[\psi (N)=the\; smallest\; prime\; factor\; of\; N\; for\; N>1\; and\; \psi (1)=1 \nonumber \]
Suppose \(P(s)\) is equal to either (\(s^N-1\)) or an intermediate noncyclotomic polynomial appearing in the factorization process, for example, (\(a^2-1\)), above. Write \(P(s)\) in terms of its cyclotomic factors,
(sN-1)(sN-1)" role="presentation" style="position:relative;" tabindex="0">\[P(s)=C_{k_{1}}(s)C_{k_{2}}(s)...C_{k_{L}}(s) \nonumber \]
define the two sets, \(G\) and \(G\), by
\[G=\left \{ k_{1},...,k_{L} \right \}\; and\; G=\left \{ k/gcd(G):k\epsilon G \right \} \nonumber \]
and define the two integers, \(t\) and \(T\), by
\[t=min\left \{ \psi (k):k\: \epsilon\: G,\: k>1 \right \}\; \; and\; \; T=max\: nu(k,t):k\: \epsilon \: G \nonumber \]
Then form two new sets,
\[A=\left \{ k\: \epsilon \: G:T\mid k \right \}\; \; and\; \; B=\left \{ k\: \epsilon \: G:T\mid k \right \} \nonumber \]
The factorization of \(P(s)\),
\[P(s)=\left ( \prod _{k\: \epsilon \: A} C_{k}(s)\right )\left ( \prod _{k\: \epsilon \: B} C_{k}(s)\right ) \nonumber \]
has been found useful in the procedure for factoring (\(s^N-1\)). This is best illustrated with an example.
Example
\(N=36\)
Step 1:
Let
\[P(s)=s^{36}-1 \nonumber \]
Since
\[P=C_{1}C_{2}C_{3}C_{4}C_{6}C_{9}C_{12}C_{18}C_{36} \nonumber \]
\[G=G=\left \{ 1,2,3,4,6,9,12,18,36 \right \} \nonumber \]
\[t=min\; \left \{ 2,3 \right \}=2 \nonumber \]
\[A=\left \{ k\: \epsilon \: G:4\mid k \right \}=\left \{ 1,2,3,6,9,18 \right \} \nonumber \]
\[B=\left \{ k\: \epsilon \: G:4\mid k \right \}=\left \{ 4,12,36 \right \} \nonumber \]
Hence the factorization of \(s^{36}-1\) into two intermediate polynomials is as expected,
\[\prod _{k\: \epsilon \: A} C_{k}(s)=s^{18}-1,\; \; \prod _{k\: \epsilon \: B} C_{k}(s)=s^{18}+1 \nonumber \]
If a \(36^{th}\) degree polynomial, \(X(s)\), is represented by a vector of coefficients,
\[X=(x_{35},...x_{0})'\; then\; ((X(s)))_{s^{18}-1}\; represented\; by\; X'\; and\; ((X(s)))_{s^{18}+1}\; represented\; by\; X'' \nonumber \]
is given by test which entails \(36\) additions.
Step 2:
This procedure is repeated with P(s)=s18-1P(s)=s18-1" role="presentation" style="position:relative;" tabindex="0">
\[P(s)=s^{18}-1 \; and\; P(s)=s^{18}+1 \nonumber \]
We will just show it for the later. Let P(s)=s18+1P(s)=s18+1" role="presentation" style="position:relative;" tabindex="0">
\[P(s)=s^{18}+1 \nonumber \]
Since
\[P=C_{4}C_{12}C_{36} \nonumber \]
\[G=\left \{ 4,12,36 \right \}\; and\; G'=\left \{ 1,3,9 \right \} \nonumber \]
\[t=min\: 3=3 \nonumber \]
\[T=max\: \nu (k,3):k\: \epsilon \: G=max\: 1,3,9=9 \nonumber \]
\[A=\left \{ k\: \epsilon \: G:9\mid k \right \}=\left \{ 4,12\right \} \nonumber \]
\[B=\left \{ k\: \epsilon \: G:9\mid k \right \}=\left \{ 36\right \} \nonumber \]
This yields the two intermediate polynomials
\[s^{6}+1\; \; and\; \; s^{12}-s^{6}+1 \nonumber \]
In the notation used above,
\[\begin{bmatrix} X' & X'' \end{bmatrix}=\begin{bmatrix} I_{6} & -I_{6} & I_{6}\\ I_{6} & I_{6} & \\ -I_{6} & & I_{6} \end{bmatrix}X \nonumber \]
entailing \(24\) additions. Continuing this process results in a factorization in steps.
In order to see the number of additions this scheme uses for numbers of the form \(N=P-1\) (which is relevant to prime length FFT algorithms).
The Polynomial Product Stage
The iterated convolution algorithm can be used to construct an \(N\) point linear convolution algorithm from shorter linear convolution algorithms. Suppose the linear convolution \(y\), of the n point vectors \(x\) and \(h\) (\(h\) known) is described by
\[y=E_{n}^{T}DE_{n}x \nonumber \]
where \(E_n\) is an “expansion" matrix the elements of which are \(\pm 1\)'s and \(0\)'s and \(D\) is an appropriate diagonal matrix. Because the only multiplications in this expression are by the elements of \(D\), the number of multiplications required, \(M(n)\), is equal to the number of rows of \(E_n\). The number of additions is denoted by \(M(n)\).
Given a matrix \(E_{n1}\) and a matrix \(E_{n2}\), the iterated algorithm gives a method for combining \(E_{n1}\) and \(E_{n2}\) to construct a valid expansion matrix, \(E_{n}\), for
\[N\leq n_{1}n_{2} \nonumber \]
Specifically,
\[E_{n_{1},n_{2}}=(I_{m(n_{2})}\otimes E_{n_{1}})(E_{n_{2}}\times I_{n_{1}}) \nonumber \]
The product \(n_1n_2\) may be greater than \(N\), for zeros can be (conceptually) appended to \(x\). The operation count associated with \(E_{n1}E_{n2}\) is
\[A(n_{1},n_{2})=n!A(n_{2})+A(n_{1})M(n_{2}) \nonumber \]
\[M(n_{1},n_{2})=M(n_{1})M(n_{2}) \nonumber \]
Although they are both valid expansion matrices,
\[E_{n_{1},n_{2}}\neq E_{n_{2},n_{1}}\; \; and\; \; A_{n_{1},n_{2}}\neq A_{n_{2},n_{1}} \nonumber \]
Because Mn1,n2≠Mn2,n1Mn1,n2≠Mn2,n1" role="presentation" style="position:relative;" tabindex="0">
\[M_{n_{1},n_{2}}\neq M_{n_{2},n_{1}} \nonumber \]
it is desirable to chose an ordering of factors to minimize the additions incurred by the expansion matrix.
Multiple Factors
Note that a valid expansion matrix, \(E_{n}\), can be constructed from \(E_{n_1,n_2}\) and \(E_{n3}\), for
N≤n1n2n3N≤n1n2n3" role="presentation" style="position:relative;" tabindex="0">\[N\leq n_{1}n_{2}n_{3} \nonumber \]
In general, any number of factors can be used to create larger expansion matrices. The operation count associated with is \(E_{n_1,n_2,n_3}\) is
\[A(n_{1},n_{2},n_{3})=n_{1}n_{2}A(n_{3})+n_{1}A(n_{2})M(n_{3})+A(n_{1})M(n_{2})M(n_{3}) \nonumber \]
\[M(n_{1},n_{2},n_{3})=M(n_{1})M(n_{2})M(n_{3}) \nonumber \]
These equations generalize in the predicted way when more factors are considered. Because the ordering of the factors is relevant in the equation for \(A(\cdot )\) but not for \(M(\cdot )\), it is again desirable to order the factors to minimize the number of additions. By exploiting the following property of the expressions for \(A(\cdot )\) and \(M(\cdot )\), the optimal ordering can be found.
Reservation of Optimal Ordering
Suppose
\( A(n_1,n_2,n_3) \le \text{min} \{A(n_{k_1},n_{k_2},n_{k_3}) \: k_1,k_2,k_3 \in \{1,2,3\} \text{ and distinct} \} \), then
| 1. |
\(A(n_1,n_2) \le A(n_2,n_1)\) |
| 2. |
\(A(n_2,n_3) \le A(n_3,n_2)\) |
| 3. |
\(A(n_1,n_3) \le A(n_3,n_1)\) |
The generalization of this property to more than two factos revelas that an optimal ordering of \( \{n_1, \ldots , n_{L-i} \} \) is preserved in an optimal ordering of \( \{n_1, \ldots , n_{L} \} \). Therefore, if \( (n_1, \ldots , n_{L-i}) \) is an optimal odering of \( \{n_1, \ldots , n_{L} \} \), then \( (n_k,n_{k+1}) \) is an optimal ordering of \( \{ n_k,n_{k+1} \} \) and consequently
\[ \dfrac{A(n_k)}{M(n_k)-n_k} \le \dfrac{A(n_{k+1})}{M(n_{k+1})-n_{k+1}} \nonumber \]
for all \(k=1,2,\ldots,L-1\).
This immediately suggests that an optimal ordering of \( \{n_1, \ldots , n_L \} \), to minimize the number of additions incurred by \( E_{n_1, \ldots , n_L}\) simply involves computing the appropriate ratios.
Discussion and Conclusion
We have designed prime length FFTs up to length \(53\) that are as good as the previous designs that only went up to \(19\). Table 1 gives the operation counts for the new and previously designed modules, assuming complex inputs.
It is interesting to note that the operation counts depend on the factorability of \(P−1\). The primes \(11\), \(23\), and \(47\) are all of the form \(1+2P_1\) making the design of efficient FFTs for these lengths more difficult.
Further deviations from the original Winograd approach than we have made could prove useful for longer lengths. We investigated, for example, the use of twiddle factors at appropriate points in the decomposition stage; these can sometimes be used to divide the cyclic convolution into smaller convolutions. Their use means, however, that the 'center* multiplications would no longer be by purely real or imaginary numbers.
| N |
Mult |
Adds |
| 7 |
16 |
72 |
| 11 |
40 |
168 |
| 13 |
40 |
188 |
| 17 |
82 |
274 |
| 19 |
88 |
360 |
| 23 |
174 |
672 |
| 29 |
190 |
766 |
| 31 |
160 |
984 |
| 37 |
220 |
920 |
| 41 |
282 |
1140 |
| 43 |
304 |
1416 |
| 47 |
640 |
2088 |
| 53 |
556 |
2038 |
Operation counts for prime length DFTs
The approach in writing a program that writes another program is a valuable one for several reasons. Programming the design process for the design of prime length FFTs has the advantages of being practical, error-free, and flexible. The flexibility is important because it allows for modification and experimentation with different algorithmic ideas. Above all, it has allowed longer DFTs to be reliably designed.
More details on the generation of programs for prime length FFTs can be found in the 1993 Technical Report.

