
0.12: Fork and Exec
- Page ID
- 81536
Fork and Exec
New processes are created by the two related interfaces
fork and
exec.
Fork
When you come to metaphorical "fork in the road" you
generally have two options to take, and your decision effects
your future. Computer programs reach this fork in the road when
they hit the fork() system
call.
At this point, the operating system will create a new process that is exactly the same as the parent process. This means all the state that was talked about previously is copied, including open files, register state and all memory allocations, which includes the program code.
The return value from the system call is the only way the process can determine if it was the existing process or a new one. The return value to the parent process will be the Process ID (PID) of the child, whilst the child will get a return value of 0.
At this point, we say the process has
forked and we have the
parent-child relationship as described above.
Exec
Forking provides a way for an existing process to start a new one, but what about the case where the new process is not part of the same program as parent process? This is the case in the shell; when a user starts a command it needs to run in a new process, but it is unrelated to the shell.
This is where the exec
system call comes into
play. exec will
replace the contents of the currently
running process with the information from a program
binary.
Thus the process the shell follows when launching a new
program is to firstly fork,
creating a new process, and then
exec (i.e. load into memory and
execute) the program binary it is supposed to run.
How Linux actually handles fork and exec
clone
In the kernel, fork is actually implemented by a
clone system call. This
clone interfaces effectively
provides a level of abstraction in how the Linux kernel can
create processes.
clone allows you to
explicitly specify which parts of the new process are copied
into the new process, and which parts are shared between the
two processes. This may seem a bit strange at first, but
allows us to easily implement threads
with one very simple interface.
Threads
While
fork copies all of the
attributes we mentioned above, imagine if everything was
copied for the new process except for
the memory. This means the parent and child share the same
memory, which includes program code and data.
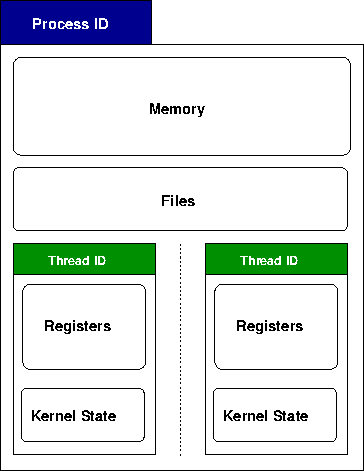
This hybrid child is called a thread. Threads have a number of advantages over where you might use fork
Separate processes can not see each others memory. They can only communicate with each other via other system calls.
Threads however, share the same memory. So you have the advantage of multiple processes, with the expense of having to use system calls to communicate between them.
The problem that this raises is that threads can very easily step on each others toes. One thread might increment a variable, and another may decrease it without informing the first thread. These type of problems are called concurrency problems and they are many and varied.
To help with this, there are userspace libraries that help programmers work with threads properly. The most common one is called
POSIX threadsor, as it more commonly referred topthreadsSwitching processes is quite expensive, and one of the major expenses is keeping track of what memory each process is using. By sharing the memory this overhead is avoided and performance can be significantly increased.
There are many different ways to implement threads. On the one hand, a userspace implementation could implement threads within a process without the kernel having any idea about it. The threads all look like they are running in a single process to the kernel.
This is suboptimal mainly because the kernel is being withheld information about what is running in the system. It is the kernels job to make sure that the system resources are utilised in the best way possible, and if what the kernel thinks is a single process is actually running multiple threads it may make suboptimal decisions.
Thus the other method is that the kernel has full
knowledge of the thread. Under Linux, this is established
by making all processes able to share resources via the
clone system call. Each
thread still has associated kernel resources, so the kernel
can take it into account when doing resource
allocations.
Other operating systems have a hybrid method, where some threads can be specified to run in userspace only ("hidden" from the kernel) and others might be a light weight process, a similar indication to the kernel that the processes is part of a thread group.
Copy on write
As we mentioned, copying
the entire memory of one process to another when
fork is called is an
expensive operation.
One optimisation is called copy on write. This means that similar to threads above, the memory is actually shared, rather than copied, between the two processes when fork is called. If the processes are only going to be reading the memory, then actually copying the data is unnecessary.
However, when a process writes to its memory, it needs to be a private copy that is not shared. As the name suggests, copy on write optimises this by only doing the actual copy of the memory at the point when it is written to.
Copy on write also has a big advantage for
exec. Since
exec will simply be
overwriting all the memory with the new program, actually
copying the memory would waste a lot of time. Copy on write
saves us actually doing the copy.
The init process
We discussed the overall goal of the init process previously, and we are now in a position to understand how it works.
On boot the kernel starts the init process, which then forks and execs the systems boot scripts. These fork and exec more programs, eventually ending up forking a login process.
The other job of the init
process is "reaping". When a process calls
exit with a return code, the
parent usually wants to check this code to see if the child
exited correctly or not.
However, this exit code is part of the process which has
just called exit. So the
process is "dead" (e.g. not running) but still needs to stay
around until the return code is collected. A process in this
state is called a zombie (the traits of
which you can contrast with a mystical zombie!)
A process stays as a zombie until the parent collects the
return code with the wait call.
However, if the parent exits before collecting this return code,
the zombie process is still around, waiting aimlessly to give
its status to someone.
In this case, the zombie child will be reparented to the init process which has a special handler that reaps the return value. Thus the process is finally free and the descriptor can be removed from the kernels process table.
Zombie example
1 $ cat zombie.c
#include <stdio.h>
#include <stdlib.h>
5 int main(void)
{
pid_t pid;
printf("parent : %d\n", getpid());
10
pid = fork();
if (pid == 0) {
printf("child : %d\n", getpid());
15 sleep(2);
printf("child exit\n");
exit(1);
}
20 /* in parent */
while (1)
{
sleep(1);
}
25 }
ianw@lime:~$ ps ax | grep [z]ombie
16168 pts/9 S 0:00 ./zombie
16169 pts/9 Z 0:00 [zombie] <defunct>Above we create a zombie process. The parent process will sleep forever, whilst the child will exit after a few seconds.
Below the code you can see the results of running the
program. The parent process (16168) is in state
S for sleep (as we expect)
and the child is in state Z
for zombie. The ps output also
tells us that the process is
defunct in the process
description.[16]
[16] The square brackets around the "z" of "zombie" are a little trick to remove the grep processes itself from the ps output. grep interprets everything between the square brackets as a character class, but because the process name will be "grep [z]ombie" (with the brackets) this will not match!