
0.27: Compiling
- Page ID
- 81551
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Compiling
The process of compiling
The first step of compiling a source file to an executable file is converting the code from the high level, human understandable language to assembly code. We know from previous chapters than assembly code works directly with the instructions and registers provided by the processor.
The compiler is the most complex step of process for a number of reasons. Firstly, humans are very unpredictable and have their source code in many different forms. The compiler is only interested the actual code, however humans need things like comments and whitespace (spaces, tabs, indents, etc) to understand code. The process that the compiler takes to convert the human-written source code to its internal representation is called parsing.
C code
With C code, there is actually a step
before parsing the source code called the
pre-processor. The pre-processor is at
its core a text replacement program. For example, any
variable declared as #define variable
text will have
variable replaced with
text. This preprocessed code
is then passed into the compiler.
Syntax
Any computing language has a particular
syntax that describes the rules of the
language. Both you and the compiler know the syntax rules, and
all going well you will understand each other. Humans, being as
they are, often forget the rules or break them, leading the
compiler to be unable to understand your intentions. For
example, if you were to leave the closing bracket off a
if condition, the compiler does
not know where the actual conditional is.
Syntax is most often described in Backus-Naur Form (BNF)[21] which is a language with which you can describe languages!
Assembly Generation
The job of the compiler is to translate the higher level language into assembly code suitable for the target being compiled for. Obviously each different architecture has a different instruction set, different numbers of registers and different rules for correct operation.
Alignment
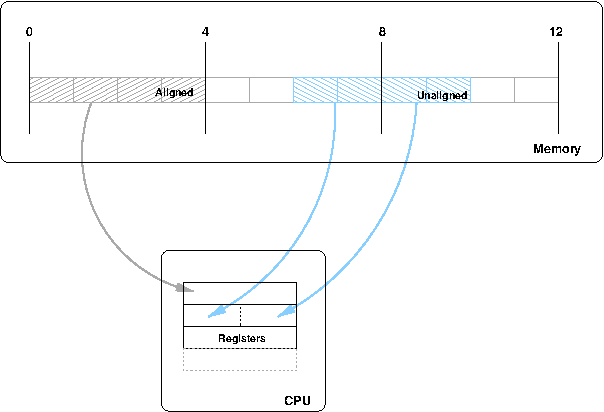
Alignment of variables in memory is an important consideration for the compiler. Systems programmers need to be aware of alignment constraints to help the compiler create the most efficient code it can.
CPUs can generally not load a value into a register from an arbitrary memory location. It requires that variables be aligned on certain boundaries. In the example above, we can see how a 32 bit (4 byte) value is loaded into a register on a machine that requires 4 byte alignment of variables.
The first variable can be directly loaded into a register, as it falls between 4 byte boundaries. The second variable, however, spans the 4 byte boundary. This means that at minimum two loads will be required to get the variable into a single register; firstly the lower half and then the upper half.
Some architectures, such as x86, can handle unaligned loads in hardware and the only symptoms will be lower performance as the hardware does the extra work to get the value into the register. Others architectures can not have alignment rules violated and will raise an exception which is generally caught by the operating system which then has to manually load the register in parts, causing even more overheads.
Structure Padding
Programmers need to consider alignment especially when
creating structs. Whilst the
compiler knows the alignment rules for the architecture it is
building for, at times programmers can cause sub-optimal
behaviour.
The C99 standard only says that structures will be ordered in memory in the same order as they are specified in the declaration, and that in an array of structures all elements will be the same size.
1 $ cat struct.c
#include <stdio.h>
struct a_struct {
5 char char_one;
char char_two;
int int_one;
};
10 int main(void)
{
struct a_struct s;
15 printf("%p : s.char_one\n" \
"%p : s.char_two\n" \
"%p : s.int_one\n", &s.char_one,
&s.char_two, &s.int_one);
20 return 0;
}
$ gcc -o struct struct.c
25
$ gcc -fpack-struct -o struct-packed struct.c
$ ./struct
0x7fdf6798 : s.char_one
30 0x7fdf6799 : s.char_two
0x7fdf679c : s.int_one
$ ./struct-packed
0x7fcd2778 : s.char_one
35 0x7fcd2779 : s.char_two
0x7fcd277a : s.int_one
In the example above, we contrive a structure that has
two bytes (chars followed
by a 4 byte integer. The compiler pads the structure as
below.

In the other example we direct the compiler
not to pad structures and
correspondingly we can see that the integer starts directly
after the two chars.
Cache line alignment
We talked previously about aliasing in the cache, and how several addresses may map to the same cache line. Programmers need to be sure that when they write their programs they do not cause bouncing of cache lines.
This situation occurs when a program constantly accesses two areas of memory that map to the same cache line. This effectively wastes the cache line, as it gets loaded in, used for a short time and then must be kicked out and the other cache line loaded into the same place in the cache.
Obviously if this situation repeats the performance will be significantly reduced. The situation would be relieved if the conflicting data was organised in slightly different ways to avoid the cache line conflict.
One possible way to detect this sort of situation is profiling. When you profile your code you "watch" it to analyse what code paths are taken and how long they take to execute. With profile guided optimisation (PGO) the compiler can put special extra bits of code in the first binary it builds, which runs and makes a record of the branches taken, etc. You can then recompile the binary with the extra information to possibly create a better performing binary. Otherwise the programmer can look at the output of the profile and possibly detect situations such as cache line bouncing. (XXX somewhere else?)
Space - Speed Trade off
What the compiler has done above is traded off using some extra memory to gain a speed improvement in running our code. The compiler knows the rules of the architecture and can make decisions about the best way to align data, possibly by trading off small amounts of wasted memory for increased (or perhaps even just correct) performance.
Consequently as a programmer you should never make assumptions about the way variables and data will be laid out by the compiler. To do so is not portable, as a different architecture may have different rules and the compiler may make different decisions based on explicit commands or optimisation levels.
Making Assumptions
Thus, as a C programmer you need to be familiar with what you can assume about what the compiler will do and what may be variable. What exactly you can assume and can not assume is detailed in the C99 standard; if you are programming in C it is certainly worth the investment in becoming familiar with the rules to avoid writing non-portable or buggy code.
1 $ cat stack.c
#include <stdio.h>
struct a_struct {
5 int a;
int b;
};
int main(void)
10 {
int i;
struct a_struct s;
printf("%p\n%p\ndiff %ld\n", &i, &s, (unsigned long)&s - (unsigned long)&i);
return 0;
15 }
$ gcc-3.3 -Wall -o stack-3.3 ./stack.c
$ gcc-4.0 -o stack-4.0 stack.c
$ ./stack-3.3
20 0x60000fffffc2b510
0x60000fffffc2b520
diff 16
$ ./stack-4.0
25 0x60000fffff89b520
0x60000fffff89b524
diff 4
In the example above, taken from an Itanium machine, we can see that the padding and alignment of the stack has changed considerably between gcc versions. This type of thing is to be expected and must be considered by the programmer.
Generally you should ensure that you do not make assumptions about the size of types or alignment rules.
C Idioms with alignment
There are a few common sequences of code that deal with alignment; generally most programs will consider it in some ways. You may see these "code idioms" in many places outside the kernel when dealing with programs that deal with chunks of data in some form or another, so it is worth investigating.
We can take some examples from the Linux kernel, which often has to deal with alignment of pages of memory within the system.
1 [ include/asm-ia64/page.h ] /* * PAGE_SHIFT determines the actual kernel page size. 5 */ #if defined(CONFIG_IA64_PAGE_SIZE_4KB) # define PAGE_SHIFT 12 #elif defined(CONFIG_IA64_PAGE_SIZE_8KB) # define PAGE_SHIFT 13 10 #elif defined(CONFIG_IA64_PAGE_SIZE_16KB) # define PAGE_SHIFT 14 #elif defined(CONFIG_IA64_PAGE_SIZE_64KB) # define PAGE_SHIFT 16 #else 15 # error Unsupported page size! #endif #define PAGE_SIZE (__IA64_UL_CONST(1) << PAGE_SHIFT) #define PAGE_MASK (~(PAGE_SIZE - 1)) 20 #define PAGE_ALIGN(addr) (((addr) + PAGE_SIZE - 1) & PAGE_MASK)
Above we can see that there are a number of different options for page sizes within the kernel, ranging from 4KB through 64KB.
The PAGE_SIZE macro
is fairly self explanatory, giving the current page size
selected within the system by shifting a value of 1 by the
shift number given (remember, this is the equivalent of
saying
2n
where n is the
PAGE_SHIFT).
Next we have a definition for
PAGE_MASK. The
PAGE_MASK allows us to find
just those bits that are within the current page, that is
the offset of an address
within its page.
XXX continue short discussion
Optimisation
Once the compiler has an internal representation of the code, the really interesting part of the compiler starts. The compiler wants to find the most optimised assembly language output for the given input code. This is a large and varied problem and requires knowledge of everything from efficient algorithms based in computer science to deep knowledge about the particular processor the code is to be run on.
There are some common optimisations the compiler can look at when generating output. There are many, many more strategies for generating the best code, and it is always an active research area.
General Optimising
The compiler can often see that a particular piece of code can not be used and so leave it out optimise a particular language construct into something smaller with the same outcome.
Unrolling loops
If code contains a loop, such as a
for or
while loop and the compiler
has some idea how many times it will execute, it may be more
efficient to unroll the loop so that it
executes sequentially. This means that instead of doing the
inside of the loop and then branching back to the start to do
repeat the process, the inner loop code is duplicated to be
executed again.
Whilst this increases the size of the code, it may allow the processor to work through the instructions more efficiently as branches can cause inefficiencies in the pipeline of instructions coming into the processor.
Inlining functions
Similar to unrolling loops, it is possible to put embed
called functions within the callee. The programmer can
specify that the compiler should try to do this by specifying
the function as inline in the
function definition. Once again, you may trade code size for
sequentially in the code by doing this.
Branch Prediction
Any time the computer comes across an
if statement there are two
possible outcomes; true or false. The processor wants to keep
its incoming pipes as full as possible, so it can not wait for
the outcome of the test before putting code into the
pipeline.
Thus the compiler can make a prediction about what way
the test is likely to go. There are some simple rules the
compiler can use to guess things like this, for example
if (val == -1) is probably
not likely to be true, since -1 usually
indicates an error code and hopefully that will not be
triggered too often.
Some compilers can actually compile the program, have the user run it and take note of which way the branches go under real conditions. It can then re-compile it based on what it has seen.
[21] In fact the most common form is Extended Backus-Naur Form, or EBNF, as it allows some extra rules which are more suitable for modern languages.