
2.2: Floating-Point Numbers
- Page ID
- 13422

Introduction
Often when we want to make a point that nothing is sacred, we say, “one plus one does not equal two.” This is designed to shock us and attack our fundamental assumptions about the nature of the universe. Well, in this chapter on floating- point numbers, we will learn that “0.1+0.10.1+0.1 does not always equal 0.20.2” when we use floating-point numbers for computations.
In this chapter we explore the limitations of floating-point numbers and how you as a programmer can write code to minimize the effect of these limitations. This chapter is just a brief introduction to a significant field of mathematics called numerical analysis.
Reality
The real world is full of real numbers. Quantities such as distances, velocities, masses, angles, and other quantities are all real numbers.1 A wonderful property of real numbers is that they have unlimited accuracy. For example, when considering the ratio of the circumference of a circle to its diameter, we arrive at a value of 3.141592.... The decimal value for pi does not terminate. Because real numbers have unlimited accuracy, even though we can’t write it down, pi is still a real number. Some real numbers are rational numbers because they can be represented as the ratio of two integers, such as 1/3. Not all real numbers are rational numbers. Not surprisingly, those real numbers that aren’t rational numbers are called irrational. You probably would not want to start an argument with an irrational number unless you have a lot of free time on your hands.
Unfortunately, on a piece of paper, or in a computer, we don’t have enough space to keep writing the digits of pi. So what do we do? We decide that we only need so much accuracy and round real numbers to a certain number of digits. For example, if we decide on four digits of accuracy, our approximation of pi is 3.142. Some state legislature attempted to pass a law that pi was to be three. While this is often cited as evidence for the IQ of governmental entities, perhaps the legislature was just suggesting that we only need one digit of accuracy for pi. Perhaps they foresaw the need to save precious memory space on computers when representing real numbers.
Representation
Given that we cannot perfectly represent real numbers on digital computers, we must come up with a compromise that allows us to approximate real numbers.2 There are a number of different ways that have been used to represent real numbers. The challenge in selecting a representation is the trade-off between space and accuracy and the tradeoff between speed and accuracy. In the field of high performance computing we generally expect our processors to produce a floating- point result every 600-MHz clock cycle. It is pretty clear that in most applications we aren’t willing to drop this by a factor of 100 just for a little more accuracy. Before we discuss the format used by most high performance computers, we discuss some alternative (albeit slower) techniques for representing real numbers.
Binary Coded Decimal
In the earliest computers, one technique was to use binary coded decimal (BCD). In BCD, each base-10 digit was stored in four bits. Numbers could be arbitrarily long with as much precision as there was memory:
123.45 0001 0010 0011 0100 0101
This format allows the programmer to choose the precision required for each variable. Unfortunately, it is difficult to build extremely high-speed hardware to perform arithmetic operations on these numbers. Because each number may be far longer than 32 or 64 bits, they did not fit nicely in a register. Much of the floating- point operations for BCD were done using loops in microcode. Even with the flexibility of accuracy on BCD representation, there was still a need to round real numbers to fit into a limited amount of space.
Another limitation of the BCD approach is that we store a value from 0–9 in a four-bit field. This field is capable of storing values from 0–15 so some of the space is wasted.
Rational Numbers
One intriguing method of storing real numbers is to store them as rational numbers. To briefly review mathematics, rational numbers are the subset of real numbers that can be expressed as a ratio of integer numbers. For example, 22/7 and 1/2 are rational numbers. Some rational numbers, such as 1/2 and 1/10, have perfect representation as base-10 decimals, and others, such as 1/3 and 22/7, can only be expressed as infinite-length base-10 decimals. When using rational numbers, each real number is stored as two integer numbers representing the numerator and denominator. The basic fractional arithmetic operations are used for addition, subtraction, multiplication, and division, as shown in [Figure 1].

The limitation that occurs when using rational numbers to represent real numbers is that the size of the numerators and denominators tends to grow. For each addition, a common denominator must be found. To keep the numbers from becoming extremely large, during each operation, it is important to find the greatest common divisor (GCD) to reduce fractions to their most compact representation. When the values grow and there are no common divisors, either the large integer values must be stored using dynamic memory or some form of approximation must be used, thus losing the primary advantage of rational numbers.
For mathematical packages such as Maple or Mathematica that need to produce exact results on smaller data sets, the use of rational numbers to represent real numbers is at times a useful technique. The performance and storage cost is less significant than the need to produce exact results in some instances.
Fixed Point
If the desired number of decimal places is known in advance, it’s possible to use fixed-point representation. Using this technique, each real number is stored as a scaled integer. This solves the problem that base-10 fractions such as 0.1 or 0.01 cannot be perfectly represented as a base-2 fraction. If you multiply 110.77 by 100 and store it as a scaled integer 11077, you can perfectly represent the base-10 fractional part (0.77). This approach can be used for values such as money, where the number of digits past the decimal point is small and known.
However, just because all numbers can be accurately represented it doesn’t mean there are not errors with this format. When multiplying a fixed-point number by a fraction, you get digits that can’t be represented in a fixed-point format, so some form of rounding must be used. For example, if you have $125.87 in the bank at 4% interest, your interest amount would be $5.0348. However, because your bank balance only has two digits of accuracy, they only give you $5.03, resulting in a balance of $130.90. Of course you probably have heard many stories of programmers getting rich depositing many of the remaining 0.0048 amounts into their own account. My guess is that banks have probably figured that one out by now, and the bank keeps the money for itself. But it does make one wonder if they round or truncate in this type of calculation.3
Mantissa/Exponent
The floating-point format that is most prevalent in high performance computing is a variation on scientific notation. In scientific notation the real number is represented using a mantissa, base, and exponent: 6.02 × 1023.
The mantissa typically has some fixed number of places of accuracy. The mantissa can be represented in base 2, base 16, or BCD. There is generally a limited range of exponents, and the exponent can be expressed as a power of 2, 10, or 16.
The primary advantage of this representation is that it provides a wide overall range of values while using a fixed-length storage representation. The primary limitation of this format is that the difference between two successive values is not uniform. For example, assume that you can represent three base-10 digits, and your exponent can range from –10 to 10. For numbers close to zero, the “distance” between successive numbers is very small. For the number 1.72×10−101.72×10-10, the next larger number is 1.73×10−101.73×10-10. The distance between these two “close” small numbers is 0.000000000001. For the number 6.33×10106.33×1010, the next larger number is 6.34×10106.34×1010. The distance between these “close” large numbers is 100 million.
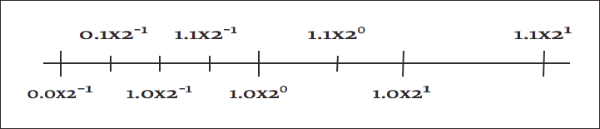
In [Figure 2], we use two base-2 digits with an exponent ranging from –1 to 1.
There are multiple equivalent representations of a number when using scientific notation:
6.00×1056.00×105
0.60×1060.60×106
0.06×1070.06×107
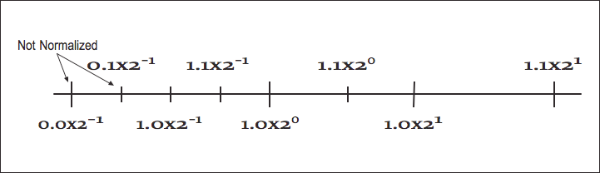
By convention, we shift the mantissa (adjust the exponent) until there is exactly one nonzero digit to the left of the decimal point. When a number is expressed this way, it is said to be “normalized.” In the above list, only 6.00 × 105 is normalized. [Figure 3] shows how some of the floating-point numbers from [Figure 2] are not normalized.
While the mantissa/exponent has been the dominant floating-point approach for high performance computing, there were a wide variety of specific formats in use by computer vendors. Historically, each computer vendor had their own particular format for floating-point numbers. Because of this, a program executed on several different brands of computer would generally produce different answers. This invariably led to heated discussions about which system provided the right answer and which system(s) were generating meaningless results.4
When storing floating-point numbers in digital computers, typically the mantissa is normalized, and then the mantissa and exponent are converted to base-2 and packed into a 32- or 64-bit word. If more bits were allocated to the exponent, the overall range of the format would be increased, and the number of digits of accuracy would be decreased. Also the base of the exponent could be base-2 or base-16. Using 16 as the base for the exponent increases the overall range of exponents, but because normalization must occur on four-bit boundaries, the available digits of accuracy are reduced on the average. Later we will see how the IEEE 754 standard for floating-point format represents numbers.
Effects of Floating-Point Representation
One problem with the mantissa/base/exponent representation is that not all base-10 numbers can be expressed perfectly as a base-2 number. For example, 1/2 and 0.25 can be represented perfectly as base-2 values, while 1/3 and 0.1 produce infinitely repeating base-2 decimals. These values must be rounded to be stored in the floating-point format. With sufficient digits of precision, this generally is not a problem for computations. However, it does lead to some anomalies where algebraic rules do not appear to apply. Consider the following example:
REAL*4 X,Y
X = 0.1
Y = 0
DO I=1,10
Y = Y + X
ENDDO
IF ( Y .EQ. 1.0 ) THEN
PRINT *,’Algebra is truth’
ELSE
PRINT *,’Not here’
ENDIF
PRINT *,1.0-Y
END
At first glance, this appears simple enough. Mathematics tells us ten times 0.1 should be one. Unfortunately, because 0.1 cannot be represented exactly as a base-2 decimal, it must be rounded. It ends up being rounded down to the last bit. When ten of these slightly smaller numbers are added together, it does not quite add up to 1.0. When X and Y are REAL*4, the difference is about 10-7, and when they are REAL*8, the difference is about 10-16.
One possible method for comparing computed values to constants is to subtract the values and test to see how close the two values become. For example, one can rewrite the test in the above code to be:
IF ( ABS(1.0-Y).LT. 1E-6) THEN
PRINT *,’Close enough for government work’
ELSE
PRINT *,’Not even close’
ENDIF
The type of the variables in question and the expected error in the computation that produces Y determines the appropriate value used to declare that two values are close enough to be declared equal.
Another area where inexact representation becomes a problem is the fact that algebraic inverses do not hold with all floating-point numbers. For example, using REAL*4, the value (1.0/X) * X does not evaluate to 1.0 for 135 values of X from one to 1000. This can be a problem when computing the inverse of a matrix using LU-decomposition. LU-decomposition repeatedly does division, multiplication, addition, and subtraction. If you do the straightforward LU-decomposition on a matrix with integer coefficients that has an integer solution, there is a pretty good chance you won’t get the exact solution when you run your algorithm. Discussing techniques for improving the accuracy of matrix inverse computation is best left to a numerical analysis text.
More Algebra That Doesn't Work
While the examples in the proceeding section focused on the limitations of multiplication and division, addition and subtraction are not, by any means, perfect. Because of the limitation of the number of digits of precision, certain additions or subtractions have no effect. Consider the following example using REAL*4 with 7 digits of precision:
X = 1.25E8
Y = X + 7.5E-3
IF ( X.EQ.Y ) THEN
PRINT *,’Am I nuts or what?’
ENDIF
While both of these numbers are precisely representable in floating-point, adding them is problematic. Prior to adding these numbers together, their decimal points must be aligned as in [Figure 4].

Unfortunately, while we have computed the exact result, it cannot fit back into a REAL*4 variable (7 digits of accuracy) without truncating the 0.0075. So after the addition, the value in Y is exactly 1.25E8. Even sadder, the addition could be performed millions of times, and the value for Y would still be 1.25E8.
Because of the limitation on precision, not all algebraic laws apply all the time. For instance, the answer you obtain from X+Y will be the same as Y+X, as per the commutative law for addition. Whichever operand you pick first, the operation yields the same result; they are mathematically equivalent. It also means that you can choose either of the following two forms and get the same answer:
(X + Y) + Z
(Y + X) + Z
However, this is not equivalent:
(Y + Z) + X
The third version isn’t equivalent to the first two because the order of the calculations has changed. Again, the rearrangement is equivalent algebraically, but not computationally. By changing the order of the calculations, we have taken advantage of the associativity of the operations; we have made an associative transformation of the original code.
To understand why the order of the calculations matters, imagine that your computer can perform arithmetic significant to only five decimal places.
Also assume that the values of X, Y, and Z are .00005, .00005, and 1.0000, respectively. This means that:
(X + Y) + Z = .00005 + .00005 + 1.0000
= .0001 + 1.0000 = 1.0001
but:
(Y + Z) + X = .00005 + 1.0000 + .00005
= 1.0000 + .00005 = 1.0000
The two versions give slightly different answers. When adding Y+Z+X, the sum of the smaller numbers was insignificant when added to the larger number. But when computing X+Y+Z, we add the two small numbers first, and their combined sum is large enough to influence the final answer. For this reason, compilers that rearrange operations for the sake of performance generally only do so after the user has requested optimizations beyond the defaults.
For these reasons, the FORTRAN language is very strict about the exact order of evaluation of expressions. To be compliant, the compiler must ensure that the operations occur exactly as you express them.5
For Kernighan and Ritchie C, the operator precedence rules are different. Although the precedences between operators are honored (i.e., * comes before +, and evaluation generally occurs left to right for operators of equal precedence), the compiler is allowed to treat a few commutative operations (+, *, &, ˆ and |) as if they were fully associative, even if they are parenthesized. For instance, you might tell the C compiler:
a = x + (y + z);
However, the C compiler is free to ignore you, and combine X, Y, and Z in any order it pleases.
Now armed with this knowledge, view the following harmless-looking code segment:
REAL*4 SUM,A(1000000)
SUM = 0.0
DO I=1,1000000
SUM = SUM + A(I)
ENDDO
Begins to look like a nightmare waiting to happen. The accuracy of this sum depends of the relative magnitudes and order of the values in the array A. If we sort the array from smallest to largest and then perform the additions, we have a more accurate value. There are other algorithms for computing the sum of an array that reduce the error without requiring a full sort of the data. Consult a good textbook on numerical analysis for the details on these algorithms.
If the range of magnitudes of the values in the array is relatively small, the straight-forward computation of the sum is probably sufficient.
Improving Accuracy Using Guard Digits
In this section we explore a technique to improve the precision of floating-point computations without using additional storage space for the floating-point numbers.
Consider the following example of a base-10 system with five digits of accuracy performing the following subtraction:
10.001 - 9.9993 = 0.0017
All of these values can be perfectly represented using our floating-point format. However, if we only have five digits of precision available while aligning the decimal points during the computation, the results end up with significant error as shown in [Figure 5].

To perform this computation and round it correctly, we do not need to increase the number of significant digits for stored values. We do, however, need additional digits of precision while performing the computation.
The solution is to add extra guard digits which are maintained during the interim steps of the computation. In our case, if we maintained six digits of accuracy while aligning operands, and rounded before normalizing and assigning the final value, we would get the proper result. The guard digits only need to be present as part of the floating-point execution unit in the CPU. It is not necessary to add guard digits to the registers or to the values stored in memory.
It is not necessary to have an extremely large number of guard digits. At some point, the difference in the magnitude between the operands becomes so great that lost digits do not affect the addition or rounding results.
History of IEEE Floating-Point Format
Prior to the RISC microprocessor revolution, each vendor had their own floating- point formats based on their designers’ views of the relative importance of range versus accuracy and speed versus accuracy. It was not uncommon for one vendor to carefully analyze the limitations of another vendor’s floating-point format and use this information to convince users that theirs was the only “accurate” floating- point implementation. In reality none of the formats was perfect. The formats were simply imperfect in different ways.
During the 1980s the Institute for Electrical and Electronics Engineers (IEEE) produced a standard for the floating-point format. The title of the standard is “IEEE 754-1985 Standard for Binary Floating-Point Arithmetic.” This standard provided the precise definition of a floating-point format and described the operations on floating-point values.
Because IEEE 754 was developed after a variety of floating-point formats had been in use for quite some time, the IEEE 754 working group had the benefit of examining the existing floating-point designs and taking the strong points, and avoiding the mistakes in existing designs. The IEEE 754 specification had its beginnings in the design of the Intel i8087 floating-point coprocessor. The i8087 floating-point format improved on the DEC VAX floating-point format by adding a number of significant features.
The near universal adoption of IEEE 754 floating-point format has occurred over a 10-year time period. The high performance computing vendors of the mid 1980s (Cray IBM, DEC, and Control Data) had their own proprietary floating-point formats that they had to continue supporting because of their installed user base. They really had no choice but to continue to support their existing formats. In the mid to late 1980s the primary systems that supported the IEEE format were RISC workstations and some coprocessors for microprocessors. Because the designers of these systems had no need to protect a proprietary floating-point format, they readily adopted the IEEE format. As RISC processors moved from general-purpose integer computing to high performance floating-point computing, the CPU designers found ways to make IEEE floating-point operations operate very quickly. In 10 years, the IEEE 754 has gone from a standard for floating-point coprocessors to the dominant floating-point standard for all computers. Because of this standard, we, the users, are the beneficiaries of a portable floating-point environment.
IEEE Floating-Point Standard
The IEEE 754 standard specified a number of different details of floating-point operations, including:
- Storage formats
- Precise specifications of the results of operations
- Special values
- Specified runtime behavior on illegal operations
Specifying the floating-point format to this level of detail insures that when a computer system is compliant with the standard, users can expect repeatable execution from one hardware platform to another when operations are executed in the same order.
IEEE Storage Format
The two most common IEEE floating-point formats in use are 32- and 64-bit numbers. [Table below] gives the general parameters of these data types.
| IEEE75 | FORTRAN | C | Bits | Exponent Bits | Mantissa Bits |
|---|---|---|---|---|---|
| Single | REAL*4 | float | 32 | 8 | 24 |
| Double | REAL*8 | double | 64 | 11 | 53 |
| Double-Extended | REAL*10 | long double | >=80 | >=15 | >=64 |
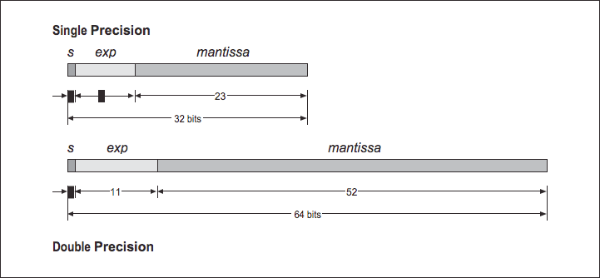
In FORTRAN, the 32-bit format is usually called REAL, and the 64-bit format is usually called DOUBLE. However, some FORTRAN compilers double the sizes for these data types. For that reason, it is safest to declare your FORTRAN variables as REAL*4 or REAL*8. The double-extended format is not as well supported in compilers and hardware as the single- and double-precision formats. The bit arrangement for the single and double formats are shown in [Figure 6].
Based on the storage layouts in [Table 1], we can derive the ranges and accuracy of these formats, as shown in [Table 1].
| IEEE754 | Minimum Normalized Number | Largest Finite Number | Base-10 Accuracy |
|---|---|---|---|
| Single | 1.2E-38 | 3.4 E+38 | 6-9 digits |
| Double | 2.2E-308 | 1.8 E+308 | 15-17 digits |
| Extended Double | 3.4E-4932 | 1.2 E+4932 | 18-21 digits |
Converting from Base-10 to IEEE Internal Format
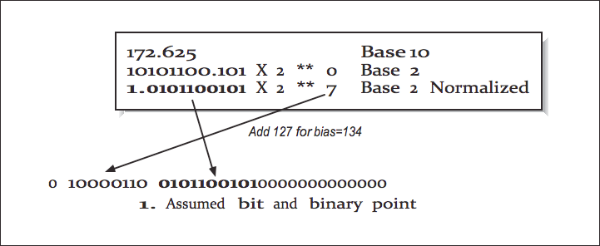
We now examine how a 32-bit floating-point number is stored. The high-order bit is the sign of the number. Numbers are stored in a sign-magnitude format (i.e., not 2’s - complement). The exponent is stored in the 8-bit field biased by adding 127 to the exponent. This results in an exponent ranging from -126 through +127.
The mantissa is converted into base-2 and normalized so that there is one nonzero digit to the left of the binary place, adjusting the exponent as necessary. The digits to the right of the binary point are then stored in the low-order 23 bits of the word. Because all numbers are normalized, there is no need to store the leading 1.
This gives a free extra bit of precision. Because this bit is dropped, it’s no longer proper to refer to the stored value as the mantissa. In IEEE parlance, this mantissa minus its leading digit is called the significand.
[Figure 7] shows an example conversion from base-10 to IEEE 32-bit format.
The 64-bit format is similar, except the exponent is 11 bits long, biased by adding 1023 to the exponent, and the significand is 54 bits long.
IEEE Operations
The IEEE standard specifies how computations are to be performed on floating-point values on the following operations:
- Addition
- Subtraction
- Multiplication
- Division
- Square root
- Remainder (modulo)
- Conversion to/from integer
- Conversion to/from printed base-10
These operations are specified in a machine-independent manner, giving flexibility to the CPU designers to implement the operations as efficiently as possible while maintaining compliance with the standard. During operations, the IEEE standard requires the maintenance of two guard digits and a sticky bit for intermediate values. The guard digits above and the sticky bit are used to indicate if any of the bits beyond the second guard digit is nonzero.
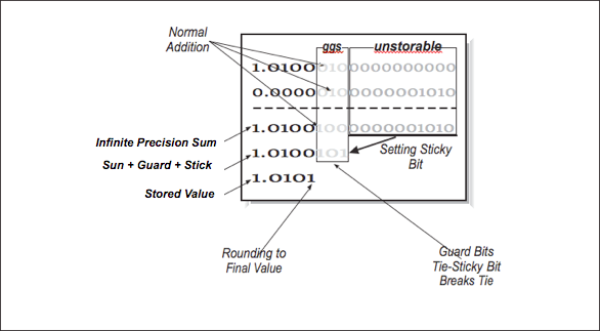
In [Figure 8], we have five bits of normal precision, two guard digits, and a sticky bit. Guard bits simply operate as normal bits — as if the significand were 25 bits. Guard bits participate in rounding as the extended operands are added. The sticky bit is set to 1 if any of the bits beyond the guard bits is nonzero in either operand.6 Once the extended sum is computed, it is rounded so that the value stored in memory is the closest possible value to the extended sum including the guard digits. [Table 3] shows all eight possible values of the two guard digits and the sticky bit and the resulting stored value with an explanation as to why.
| Extended Sum | Stored Value | Why |
|---|---|---|
| 1.0100 000 | 1.0100 | Truncated based on guard digits |
| 1.0100 001 | 1.0100 | Truncated based on guard digits |
| 1.0100 010 | 1.0100 | Rounded down based on guard digits |
| 1.0100 011 | 1.0100 | Rounded down based on guard digits |
| 1.0100 100 | 1.0100 | Rounded down based on sticky bit |
| 1.0100 101 | 1.0101 | Rounded up based on sticky bit |
| 1.0100 110 | 1.0101 | Rounded up based on guard digits |
| 1.0100 111 | 1.0101 | Rounded up based on guard digits |
The first priority is to check the guard digits. Never forget that the sticky bit is just a hint, not a real digit. So if we can make a decision without looking at the sticky bit, that is good. The only decision we are making is to round the last storable bit up or down. When that stored value is retrieved for the next computation, its guard digits are set to zeros. It is sometimes helpful to think of the stored value as having the guard digits, but set to zero.
Two guard digits and the sticky bit in the IEEE format insures that operations yield the same rounding as if the intermediate result were computed using unlimited precision and then rounded to fit within the limits of precision of the final computed value.
At this point, you might be asking, “Why do I care about this minutiae?” At some level, unless you are a hardware designer, you don’t care. But when you examine details like this, you can be assured of one thing: when they developed the IEEE floating-point standard, they looked at the details very carefully. The goal was to produce the most accurate possible floating-point standard within the constraints of a fixed-length 32- or 64-bit format. Because they did such a good job, it’s one less thing you have to worry about. Besides, this stuff makes great exam questions.
Special Values
In addition to specifying the results of operations on numeric data, the IEEE standard also specifies the precise behavior on undefined operations such as dividing by zero. These results are indicated using several special values. These values are bit patterns that are stored in variables that are checked before operations are performed. The IEEE operations are all defined on these special values in addition to the normal numeric values. [Table 4] summarizes the special values for a 32-bit IEEE floating-point number.
| Special Value | Exponent | Significand |
|---|---|---|
| + or – 0 | 00000000 | 0 |
| Denormalized number | 00000000 | nonzero |
| NaN (Not a Number) | 11111111 | nonzero |
| + or – Infinity | 11111111 | 0 |
The value of the exponent and significand determines which type of special value this particular floating-point number represents. Zero is designed such that integer zero and floating-point zero are the same bit pattern.
Denormalized numbers can occur at some point as a number continues to get smaller, and the exponent has reached the minimum value. We could declare that minimum to be the smallest representable value. However, with denormalized values, we can continue by setting the exponent bits to zero and shifting the significand bits to the right, first adding the leading “1” that was dropped, then continuing to add leading zeros to indicate even smaller values. At some point the last nonzero digit is shifted off to the right, and the value becomes zero. This approach is called gradual underflow where the value keeps approaching zero and then eventually becomes zero. Not all implementations support denormalized numbers in hardware; they might trap to a software routine to handle these numbers at a significant performance cost.
At the top end of the biased exponent value, an exponent of all 1s can represent the Not a Number (NaN) value or infinity. Infinity occurs in computations roughly according to the principles of mathematics. If you continue to increase the magnitude of a number beyond the range of the floating-point format, once the range has been exceeded, the value becomes infinity. Once a value is infinity, further additions won’t increase it, and subtractions won’t decrease it. You can also produce the value infinity by dividing a nonzero value by zero. If you divide a nonzero value by infinity, you get zero as a result.
The NaN value indicates a number that is not mathematically defined. You can generate a NaN by dividing zero by zero, dividing infinity by infinity, or taking the square root of -1. The difference between infinity and NaN is that the NaN value has a nonzero significand. The NaN value is very sticky. Any operation that has a NaN as one of its inputs always produces a NaN result.
Exceptions and Traps
In addition to defining the results of computations that aren’t mathematically defined, the IEEE standard provides programmers with the ability to detect when these special values are being produced. This way, programmers can write their code without adding extensive IF tests throughout the code checking for the magnitude of values. Instead they can register a trap handler for an event such as underflow and handle the event when it occurs. The exceptions defined by the IEEE standard include:
- Overflow to infinity
- Underflow to zero
- Division by zero
- Invalid operation
- Inexact operation
According to the standard, these traps are under the control of the user. In most cases, the compiler runtime library manages these traps under the direction from the user through compiler flags or runtime library calls. Traps generally have significant overhead compared to a single floating-point instruction, and if a program is continually executing trap code, it can significantly impact performance.
In some cases it’s appropriate to ignore traps on certain operations. A commonly ignored trap is the underflow trap. In many iterative programs, it’s quite natural for a value to keep reducing to the point where it “disappears.” Depending on the application, this may or may not be an error situation so this exception can be safely ignored.
If you run a program and then it terminates, you see a message such as:
Overflow handler called 10,000,000 times
It probably means that you need to figure out why your code is exceeding the range of the floating-point format. It probably also means that your code is executing more slowly because it is spending too much time in its error handlers.
Compiler Issues
The IEEE 754 floating-point standard does a good job describing how floating- point operations are to be performed. However, we generally don’t write assembly language programs. When we write in a higher-level language such as FORTRAN, it’s sometimes difficult to get the compiler to generate the assembly language you need for your application. The problems fall into two categories:
- The compiler is too conservative in trying to generate IEEE-compliant code and produces code that doesn’t operate at the peak speed of the processor. On some processors, to fully support gradual underflow, extra instructions must be generated for certain instructions. If your code will never underflow, these instructions are unnecessary overhead.
- The optimizer takes liberties rewriting your code to improve its performance, eliminating some necessary steps. For example, if you have the following code:
Z = X + 500 Y = Z - 200The optimizer may replace it withY = X + 300. However, in the case of a value forXthat is close to overflow, the two sequences may not produce the same result.
Sometimes a user prefers “fast” code that loosely conforms to the IEEE standard, and at other times the user will be writing a numerical library routine and need total control over each floating-point operation. Compilers have a challenge supporting the needs of both of these types of users. Because of the nature of the high performance computing market and benchmarks, often the “fast and loose” approach prevails in many compilers.
Closing Notes
While this is a relatively long chapter with a lot of technical detail, it does not even begin to scratch the surface of the IEEE floating-point format or the entire field of numerical analysis. We as programmers must be careful about the accuracy of our programs, lest the results become meaningless. Here are a few basic rules to get you started:
- Look for compiler options that relax or enforce strict IEEE compliance and choose the appropriate option for your program. You may even want to change these options for different portions of your program.
- Use
REAL*8for computations unless you are sureREAL*4has sufficient precision. Given that REAL*4 has roughly 7 digits of precision, if the bottom digits become meaningless due to rounding and computations, you are in some danger of seeing the effect of the errors in your results.REAL*8with 13 digits makes this much less likely to happen. - Be aware of the relative magnitude of numbers when you are performing additions.
- When summing up numbers, if there is a wide range, sum from smallest to largest.
- Perform multiplications before divisions whenever possible.
- When performing a comparison with a computed value, check to see if the values are “close” rather than identical.
- Make sure that you are not performing any unnecessary type conversions during the critical portions of your code.
An excellent reference on floating-point issues and the IEEE format is “What Every Computer Scientist Should Know About Floating-Point Arithmetic,” written by David Goldberg, in ACM Computing Surveys magazine (March 1991). This article gives examples of the most common problems with floating-point and outlines the solutions. It also covers the IEEE floating-point format very thoroughly. I also recommend you consult Dr. William Kahan’s home page (http://www.cs.berkeley.edu/~wkahan/) for some excellent materials on the IEEE format and challenges using floating-point arithmetic. Dr. Kahan was one of the original designers of the Intel i8087 and the IEEE 754 floating-point format.
Exercises
Exercise \(\PageIndex{1}\)
Run the following code to count the number of inverses that are not perfectly accurate:
REAL*4 X,Y,Z
INTEGER I
I = 0
DO X=1.0,1000.0,1.0
Y = 1.0 / X
Z = Y * X
IF ( Z .NE. 1.0 ) THEN
I = I + 1
ENDIF
ENDDO
PRINT *,’Found ’,I
END
Exercise \(\PageIndex{2}\)
Change the type of the variables to REAL*8 and repeat. Make sure to keep the optimization at a sufficiently low level (-00) to keep the compiler from eliminating the computations.
Exercise \(\PageIndex{3}\)
Write a program to determine the number of digits of precision for REAL*4 and REAL*8.
Exercise \(\PageIndex{4}\)
Write a program to demonstrate how summing an array forward to backward and backward to forward can yield a different result.
Exercise \(\PageIndex{5}\)
Assuming your compiler supports varying levels of IEEE compliance, take a significant computational code and test its overall performance under the various IEEE compliance options. Do the results of the program change?
Footnotes
- In high performance computing we often simulate the real world, so it is somewhat ironic that we use simulated real numbers (floating-point) in those simulations of the real world.
- Interestingly, analog computers have an easier time representing real numbers. Imagine a “water- adding” analog computer which consists of two glasses of water and an empty glass. The amount of water in the two glasses are perfectly represented real numbers. By pouring the two glasses into a third, we are adding the two real numbers perfectly (unless we spill some), and we wind up with a real number amount of water in the third glass. The problem with analog computers is knowing just how much water is in the glasses when we are all done. It is also problematic to perform 600 million additions per second using this technique without getting pretty wet. Try to resist the temptation to start an argument over whether quantum mechanics would cause the real numbers to be rational numbers. And don’t point out the fact that even digital computers are really analog computers at their core. I am trying to keep the focus on floating-point values, and you keep drifting away!
- Perhaps banks round this instead of truncating, knowing that they will always make it up in teller machine fees.
- Interestingly, there was an easy answer to the question for many programmers. Generally they trusted the results from the computer they used to debug the code and dismissed the results from other computers as garbage.
- Often even if you didn’t mean it.
- If you are somewhat hardware-inclined and you think about it for a moment, you will soon come up with a way to properly maintain the sticky bit without ever computing the full “infinite precision sum.” You just have to keep track as things get shifted around.