14.3: Discussion and Exercises
- Page ID
- 8497

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)The external memory model of computation was introduced by Aggarwal and Vitter [4]. It is sometimes also called the I/O model or the disk access model.
\(B\)-Trees are to external memory searching what binary search trees are to internal memory searching. \(B\)-trees were introduced by Bayer and McCreight [9] in 1970 and, less than ten years later, the title of Comer's ACM Computing Surveys article referred to them as ubiquitous [15].
Like binary search trees, there are many variants of \(B\)-Trees, including \(B^+\)-trees, \(B^*\)-trees, and counted \(B\)-trees. \(B\)-trees are indeed ubiquitous and are the primary data structure in many file systems, including Apple's HFS+, Microsoft's NTFS, and Linux's Ext4; every major database system; and key-value stores used in cloud computing. Graefe's recent survey [36] provides a 200+ page overview of the many modern applications, variants, and optimizations of \(B\)-trees.
\(B\)-trees implement the SSet interface. If only the USet interface is needed, then external memory hashing could be used as an alternative to \(B\)-trees. External memory hashing schemes do exist; see, for example, Jensen and Pagh [43]. These schemes implement the USet operations in \(O(1)\) expected time in the external memory model. However, for a variety of reasons, many applications still use \(B\)-trees even though they only require USet operations.
One reason \(B\)-trees are such a popular choice is that they often perform better than their \(O(\log_B \mathtt{n})\) running time bounds suggest. The reason for this is that, in external memory settings, the value of \(B\) is typically quite large--in the hundreds or even thousands. This means that 99% or even 99.9% of the data in a \(B\)-tree is stored in the leaves. In a database system with a large memory, it may be possible to cache all the internal nodes of a \(B\)-tree in RAM, since they only represent 1% or 0.1% of the total data set. When this happens, this means that a search in a \(B\)-tree involves a very fast search in RAM, through the internal nodes, followed by a single external memory access to retrieve a leaf.
Exercise \(\PageIndex{1}\)
Show what happens when the keys 1.5 and then 7.5 are added to the \(B\)-tree in Figure 14.2.1.
Exercise \(\PageIndex{2}\)
Show what happens when the keys 3 and then 4 are removed from the \(B\)-tree in Figure 14.2.1.
Exercise \(\PageIndex{3}\)
What is the maximum number of internal nodes in a \(B\)-tree that stores \(\mathtt{n}\) keys (as a function of \(\mathtt{n}\) and \(B\))?
Exercise \(\PageIndex{4}\)
The introduction to this chapter claims that \(B\)-trees only need an internal memory of size \(O(B+\log_B\mathtt{n})\). However, the implementation given here actually requires more memory.
- Show that the implementation of the \(\mathtt{add(x)}\) and \(\mathtt{remove(x)}\) methods given in this chapter use an internal memory proportional to \(B\log_B \mathtt{n}\).
- Describe how these methods could be modified in order to reduce their memory consumption to \(O(B + \log_B \mathtt{n})\).
Exercise \(\PageIndex{5}\)
Draw the credits used in the proof of Lemma 14.2.1 on the trees in Figures 14.2.5 and 14.2.6. Verify that (with three additional credits) it is possible to pay for the splits, merges, and borrows and maintain the credit invariant.
Exercise \(\PageIndex{6}\)
Design a modified version of a \(B\)-tree in which nodes can have anywhere from \(B\) up to \(3B\) children (and hence \(B-1\) up to \(3B-1\) keys). Show that this new version of \(B\)-trees performs only \(O(m/B)\) splits, merges, and borrows during a sequence of \(m\) operations. (Hint: For this to work, you will have to be more agressive with merging, sometimes merging two nodes before it is strictly necessary.)
Exercise \(\PageIndex{7}\)
In this exercise, you will design a modified method of splitting and merging in \(B\)-trees that asymptotically reduces the number of splits, borrows and merges by considering up to three nodes at a time.
- Let \(\mathtt{u}\) be an overfull node and let \(\mathtt{v}\) be a sibling immediately to the right of \(\mathtt{u}\). There are two ways to fix the overflow at \(\mathtt{u}\):
- \(\mathtt{u}\) can give some of its keys to \(\mathtt{v}\); or
- \(\mathtt{u}\) can be split and the keys of \(\mathtt{u}\) and \(\mathtt{v}\) can be evenly distributed among \(\mathtt{u}\), \(\mathtt{v}\), and the newly created node, \(\mathtt{w}\).
- Let \(\mathtt{u}\) be an underfull node and let \(\mathtt{v}\) and \(\mathtt{w}\) be siblings of \(\mathtt{u}\) There are two ways to fix the underflow at \(\mathtt{u}\):
- keys can be redistributed among \(\mathtt{u}\), \(\mathtt{v}\), and \(\mathtt{w}\); or
- \(\mathtt{u}\), \(\mathtt{v}\), and \(\mathtt{w}\) can be merged into two nodes and the keys of \(\mathtt{u}\), \(\mathtt{v}\), and \(\mathtt{w}\) can be redistributed amongst these nodes.
- Show that, with these modifications, the number of merges, borrows, and splits that occur during \(m\) operations is \(O(m/B)\).
Exercise \(\PageIndex{8}\)
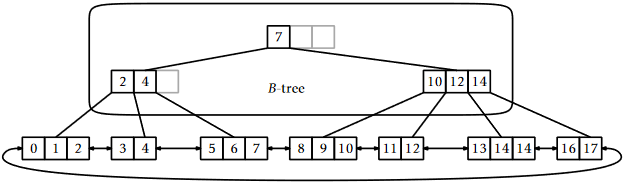
A \(B^+\)-tree, illustrated in Figure \(\PageIndex{1}\) stores every key in a leaf and keeps its leaves stored as a doubly-linked list. As usual, each leaf stores between \(B-1\) and \(2B-1\) keys. Above this list is a standard \(B\)-tree that stores the largest value from each leaf but the last.
- Describe fast implementations of \(\mathtt{add(x)}\), \(\mathtt{remove(x)}\), and \(\mathtt{find(x)}\) in a \(B^+\)-tree.
- Explain how to efficiently implement the \(\mathtt{findRange(x,y)}\) method, that reports all values greater than \(\mathtt{x}\) and less than or equal to \(\mathtt{y}\), in a \(B^+\)-tree.
- Implement a class, BPlusTree, that implements \(\mathtt{find(x)}\), \(\mathtt{add(x)}\), \(\mathtt{remove(x)}\), and \(\mathtt{findRange(x,y)}\).
- \(B^+\)-trees duplicate some of the keys because they are stored both in the \(B\)-tree and in the list. Explain why this duplication does not add up to much for large values of \(B\).