
3.6: Address translation
- Page ID
- 40723

How does a virtual address (VA) get translated to a physical address (PA)? The basic mechanism is simple, but a simple implementation would be too slow and take too much space. So actual implementations are a bit more complicated.
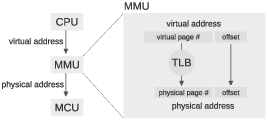
Most processors provide a memory management unit (MMU) that sits between the CPU and main memory. The MMU performs fast translation between VAs and PAs.
- When a program reads or writes a variable, the CPU generates a VA.
- The MMU splits the VA into two parts, called the page number and the offset. A “page” is a chunk of memory; the size of a page depends on the operating system and the hardware, but common sizes are 1–4 KiB.
- The MMU looks up the page number in the translation lookaside buffer (TLB) and gets the corresponding physical page number. Then it combines the physical page number with the offset to produce a PA.
- The PA is passed to main memory, which reads or writes the given location.
The TLB contains cached copies of data from the page table (which is stored in kernel memory). The page table contains the mapping from virtual page numbers to physical page numbers. Since each process has its own page table, the TLB has to make sure it only uses entries from the page table of the process that’s running.
Figure \(\PageIndex{1}\) shows a diagram of this process. To see how it all works, suppose that the VA is 32 bits and the physical memory is 1 GiB, divided into 1 KiB pages.
- Since 1 GiB is \( 2^{30} \)bytes and 1 KiB is \( 2^{10} \)bytes, there are \( 2^{20} \) physical pages, sometimes called “frames.”
- The size of the virtual address space is \(2^{32} \) B and the size of a page is \( 2^{10} \) B, so there are \( 2^{22} \) virtual pages.
- The size of the offset is determined by the page size. In this example the page size is \( 2^{10} \) B, so it takes 10 bits to specify a byte on a page.
- If a VA is 32 bits and the offset is 10 bits, the remaining 22 bits make up the virtual page number.
- Since there are \( 2^{20} \) physical pages, each physical page number is 20 bits. Adding in the 10 bit offset, the resulting PAs are 30 bits.
So far this all seems feasible. But let’s think about how big a page table might have to be. The simplest implementation of a page table is an array with one entry for each virtual page. Each entry would contain a physical page number, which is 20 bits in this example, plus some additional information about each frame. So we expect 3–4 bytes per entry. But with 222 virtual pages, the page table would require 224 bytes, or 16 MiB.
And since we need a page table for each process, a system running 256 processes would need \( 2^{32} \) bytes, or 4 GiB, just for page tables! And that’s just with 32-bit virtual addresses. With 48- or 64-bit VAs, the numbers are ridiculous.
Fortunately, we don’t actually need that much space, because most processes don’t use even a small fraction of their virtual address space. And if a process doesn’t use a virtual page, we don’t need an entry in the page table for it.
Another way to say the same thing is that page tables are “sparse”, which implies that the simple implementation, an array of page table entries, is a bad idea. Fortunately, there are several good implementations for sparse arrays.
One option is a multilevel page table, which is what many operating systems, including Linux, use. Another option is an associative table, where each entry includes both the virtual page number and the physical page number. Searching an associative table can be slow in software, but in hardware we can search the entire table in parallel, so associative arrays are often used to represent the page table entries in the TLB.
You can read more about these implementations at http://en.Wikipedia.org/wiki/Page_table; you might find the details interesting. But the fundamental idea is that page tables are sparse, so we have to choose a good implementation for sparse arrays.
I mentioned earlier that the operating system can interrupt a running process, save its state, and then run another process. This mechanism is called a context switch. Since each process has its own page table, the operating system has to work with the MMU to make sure each process gets the right page table. In older machines, the page table information in the MMU had to be replaced during every context switch, which was expensive. In newer systems, each page table entry in the MMU includes the process ID, so page tables from multiple processes can be in the MMU at the same time.