17.6: Packrat Parsers
- Page ID
- 43769

In the beginning of the chapter, we have mentioned four parser methodologies, one of them was Packrat Parsers. We claimed that packrat parsing gives linear parse times. But in the debugging example we saw that original version of the BacktrackingParser parsed \( \mathit{input}_{c} \) of length 10 in 233 steps. And if you try to parse \( \mathit{longinput}_{c} = \) 'aaaaaaaaaaaaaaaaaaaac' (length 20), you will see that the original parser needs 969 steps. Indeed, the progress is not linear.
The PetitParser framework does not use packrat parsing by default. You need to send the memoized message to enable packrat parsing. The memoized parser ensures that the parsing for the particular position in an input and the particular parser will be performed only once and the result will be remembered in a dictionary for a future use. The second time the parser wants to parse the input, the result will be looked up in the dictionary. This way, a lot of unnecessary parsing can be avoided. The disadvantage is that PetitParser needs much more memory to remember all the results of all the possible parsers at all the possible positions.
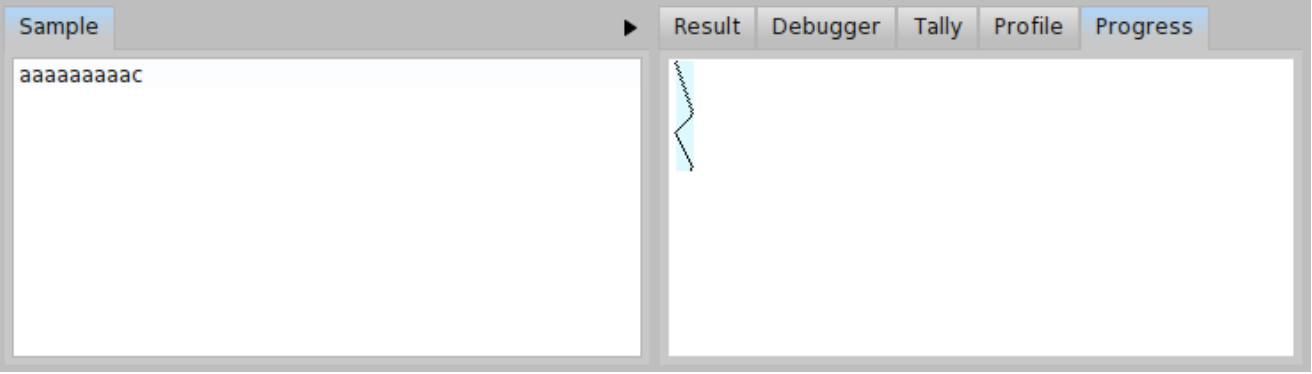
To give you an example with a packrat parser, let us return back to the BacktrackingParser once again (see Code 18.5.4). As we have analyzed before, the problem was in the parser ab that constantly failed in the p -> ab -> ap -> p loop. Now we can do the trick and memoize the parser ab by updating the method ab as in Code \(\PageIndex{1}\). When the memoization is applied, we get the progress as in Figure \(\PageIndex{1}\) with the total number of 63 invocations for \( \mathit{input}_{c} \) and the 129 invocations for \( \mathit{longinput}_{c} \). With the minor modification of BacktrackingParser we got a linear parsing time (related to the length of the input) with a factor around 6.
Code \(\PageIndex{1}\) (Pharo): Memoized version of the parser ab
BacktrackingParser>>ab
^ ( 'b' asParser /
('a' asParser, ab)
) memoized