
2.5: Program to Prompt and Read a String from a User
- Page ID
- 27096

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)The programs to read a number from a user and read a string from a user look very similar, but are conceptually very different. The following program shows reading a string from the user console.
Program 2-3: Program to read a string from the user
# Program File: Program2-3.asm
# Author: Charles Kann
# Program to read a string from a user, and # print that string back to the console.
.text
main:
# Prompt for the string to enter
li $v0, 4
la $a0, prompt
syscall
# Read the string.
li $v0, 8
la $a0, input
lw $a1, inputSize syscall
# Output the text
li $v0, 4
la $a0, output
syscall
# Output the number
li $v0, 4
la $a0, input
syscall
# Exit the program
li $v0, 10
syscall
.data
input: .space 81
inputSize: .word 80
prompt: .asciiz "Please enter an string: "
output: .asciiz "\nYou typed the string: "
2.5.1 Program 2-3 Commentary
The following commentary covers new information which is of interest in reading Program 2-3.
- There was two new assembler directives introduced in this program. The first is the
.spacedirective. The.spacedirective allocatesnbytes of memory in the data region of the program, where n=81 in this program. Since the size of a character is 1 byte, this is equivalent to saving 80 characters for data. Why 81 is used will be covered in the discussion of strings later in this section. - The
.worddirective allocates 4 bytes of space in the data region. The.worddirective can then be given an integer value, and it will initialize the allocated space to that integer value. Be careful as it is incorrect to think of a the.worddirective as a declaration for an integer, as this directive simply allocates and initializes 4 bytes of memory, it is not a data type. What is stored in this memory can by any type of data. - As was discussed earlier in this chapter, the
laoperator loads the address of the label into a register. In HLL this is normally called a reference to the data, and this text will use both of these terms when referring to reference data. This will be shown in the text as follows, which means the value of the label (the memory address) is loaded into a register.$a0 <= label
- A new operator,
lw, was introduced in this section. Thelwoperator loads the value contained at the label into the register, so in the preceding programlw $a1,inputSizeloaded the value80into the register$a1. Loading of values into a register will be shown in the text as follows, which means the value at the label is loaded into a register.$a1 <= M[label]
- In MIPS assembly, a string is a sequence of ASCII characters which are terminated with a null value (a null value is a byte containing 0x00). So for example the string containing "Chuck" would be 0x436875636b00 in ASCII. Thus when handling strings, an extra byte must always be added to include the null terminator. The string "Chuck", which is 5 character, would require 6 bytes to store, or to store this string the following .space directive would be used.
.space 6
This is why in the preceding program the string input, which was 80 characters big, required a space of 81. This is also the reason for the assembler directives
.asciiand.asciiz. The.asciidirective only allocates the ASCII characters, but the.asciizdirective allocates the characters terminated by a null. So the.asciizallocates a string. - Reading a string from the console is done using the
syscallservice 8. When usingsyscallservice 8 to read a string, there are two parameters passed to the service. The first is a reference to the memory to use to store the string (stored in$a0), and the second is the maximum size of the string to read (stored in$a1). Note that the size is 1 less than the number of characters available to account for the null terminator. If the string the user enters is larger than the maximum size of the string, it is truncated to the maximum size. This is to prevent the program from accessing memory not allocated to the string.The parameters passed to the method are the string reference in $a0, and the maximum size of the string in $a1. Note that in the case of the string in $a0, the value for the string is contained in memory, and only the reference is passed to the function. Because the reference is passed, the actual value of the string can be changed in memory in the function. This we will equate to the concept of pass-by-reference6 in a language like Java. In the case of string size, the actual value is contained in $a1. This corresponds to the concept of pass-by-value in a language like Java. A Java program to illustrate this is at the end of this chapter. This topic of value and reference types will be covered in much greater details in the chapters on subprograms and arrays.
Figure 2-6: Memory before entering a string
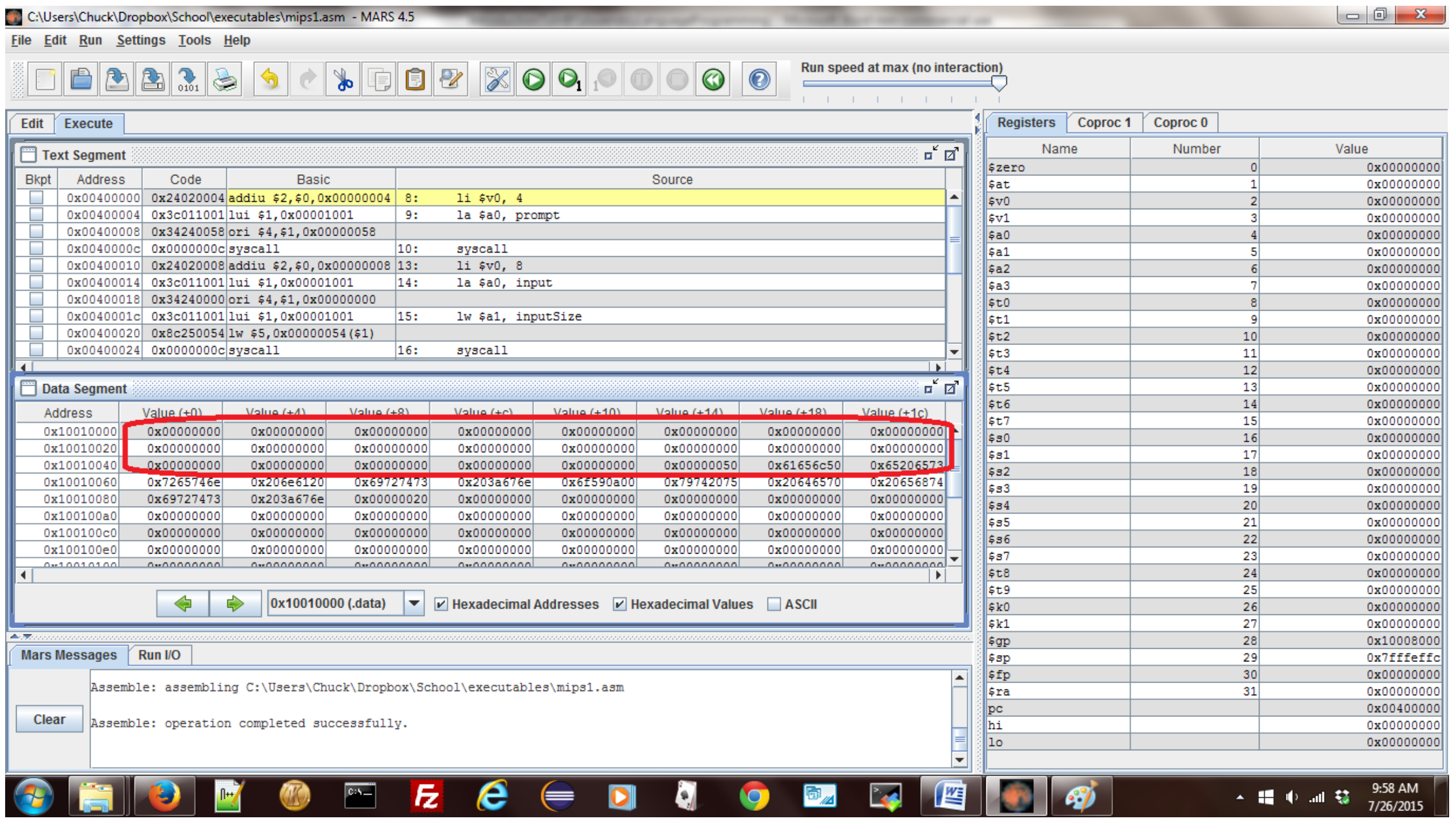
- When using syscall service 8, the syscall actually changes the memory in the data region of the program. To understand this, the preceding figure shows the program execution string immediately before the program is run. Note that the memory circled in red is the space which was saved for the input string, and it is all null values.
Run the program and enter "Chuck" at the prompt for a string. The memory for the input string has been changed to store the value "Chuck", as shown in the circled text in the figure below (be sure to select the ASCII checkbox, or the values will show up in hex).
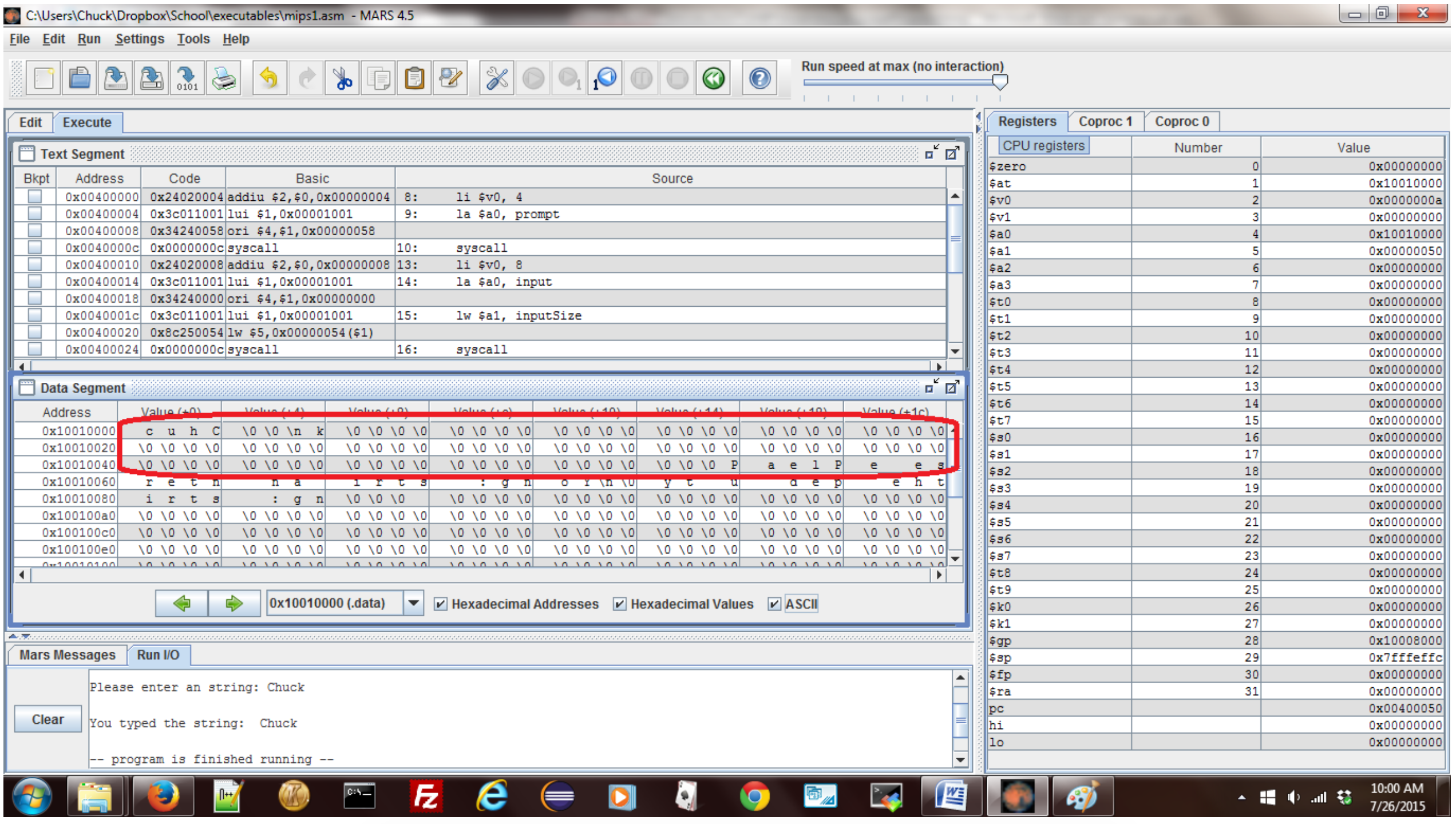
In his figure there are 8 bytes containing the characters "cuhC \0\0\nk". This is the string "Chuck", plus a new line character which is always returned by service 8, the null terminator and an extra byte of memory which was not used. This shows that the $a0 parameter to service 8 was actually a memory reference, and the service updated the memory directly.
The second thing to note in this figure is that the letters are stored backwards each grouping of 4 bytes, or a memory word. In this example, the string "Chuck\n" was broken into two strings "Chuc" and "k\n". The characters were then reversed, resulting in "cuhC" and "\nk". This is a common format in computer hardware referred to as little endian. Little endian means that bytes are stored with the least significant byte in the lowest address, which reverses the 4 bytes in the memory word. Big endian is the reverse, and in a big endian system the string would appear in memory as it was typed. The choice of big endian verses little endian is a decision made by the implementers of the hardware. You as a programmer just have to realize what type of format is used, and adjust how you interpret the characters appropriately.
Note from this figure that the service 8 call always appends a "\n" to the string. There is no mechanism to change this in MARS, and no programmatic way to handle this in our programs. This is an annoyance which we will be stuck with until strings are covered at the end of this text.
Finally see that while the string which is returned has 6 character, "Chuck\n", the other 80 characters in memory have all be set to zero. The space allocated for the string is still 80, but the string size is 6. What determines the string size (the actual number of characters used) is the position of the first zero, or null. Thus strings are referred to as
"null terminated". Many HLL, like C and C++7 , use this definition of a string.
6 It would be more exact to call this a pass-by-reference-value, as it is not a true pass-by-reference as is implemented in a language like C or C#. But this parameter passing mechanism is commonly called pass-by-reference in Java, and the difference between the two is beyond what can be explained in assembly at this point.