
7.2: What is a program stack
- Page ID
- 76126

This section will cover what is the program stack and how to use it with functions. It will first present a problem with the last program. That problem will be solved using a static variable; this is an old solution that is no longer used and the rationale will be discussed. The section will continue by defining a data structure called a stack and show why adding and removing memory from a stack is simple and fast. Finally, the program stack for the lr will be shown.
7.2.1 Why the increment function is erroneous
The increment function works correctly, so the reader is probably wondering why I call this function erroneous. Remember that the definition of erroneous is not that the program produces an error, but a program that is implemented following a bad or non-standard practice that leads to programs that are less well understood, less rigorously implemented, and more error prone.
This function is erroneous because there is a standard form for functions that should always be followed unless there is a good and well documented reason not to follow the standard.
To see what this standard format is, first an example of how a problem can occur will be shown. Consider the case where the increment function is much more complex, but still does not call any other function. Note also that now the function passes the value into the function in r1, which is a strange behavior. The program will work as shown above. But at some point, the program encounters some complex operation, and the programmer wishes to print out the value of r1. They correctly set up the call to printf, as shown in the code for the increment function in Program 10.
#function increment
increment:
LDR r0, =OutputFormat
BL printf
ADD r1, r1, #1
MOV pc, lr
.data
OutputFormat: .asciz “r1 = “
#end increment
10 Increment function with printf
If this program is run, it prints out the value of r1, but then enters an infinite loop. The ^c (ctrl-c) will stop the program, but the question is, why did it enter an infinite loop?
Next run the program in gdbtui, set a break point at the line “BL printf” and run the program. When it stops at this line, check the value of the lr register, and see that it contains the branch back to the main, as shown in Figure 66.
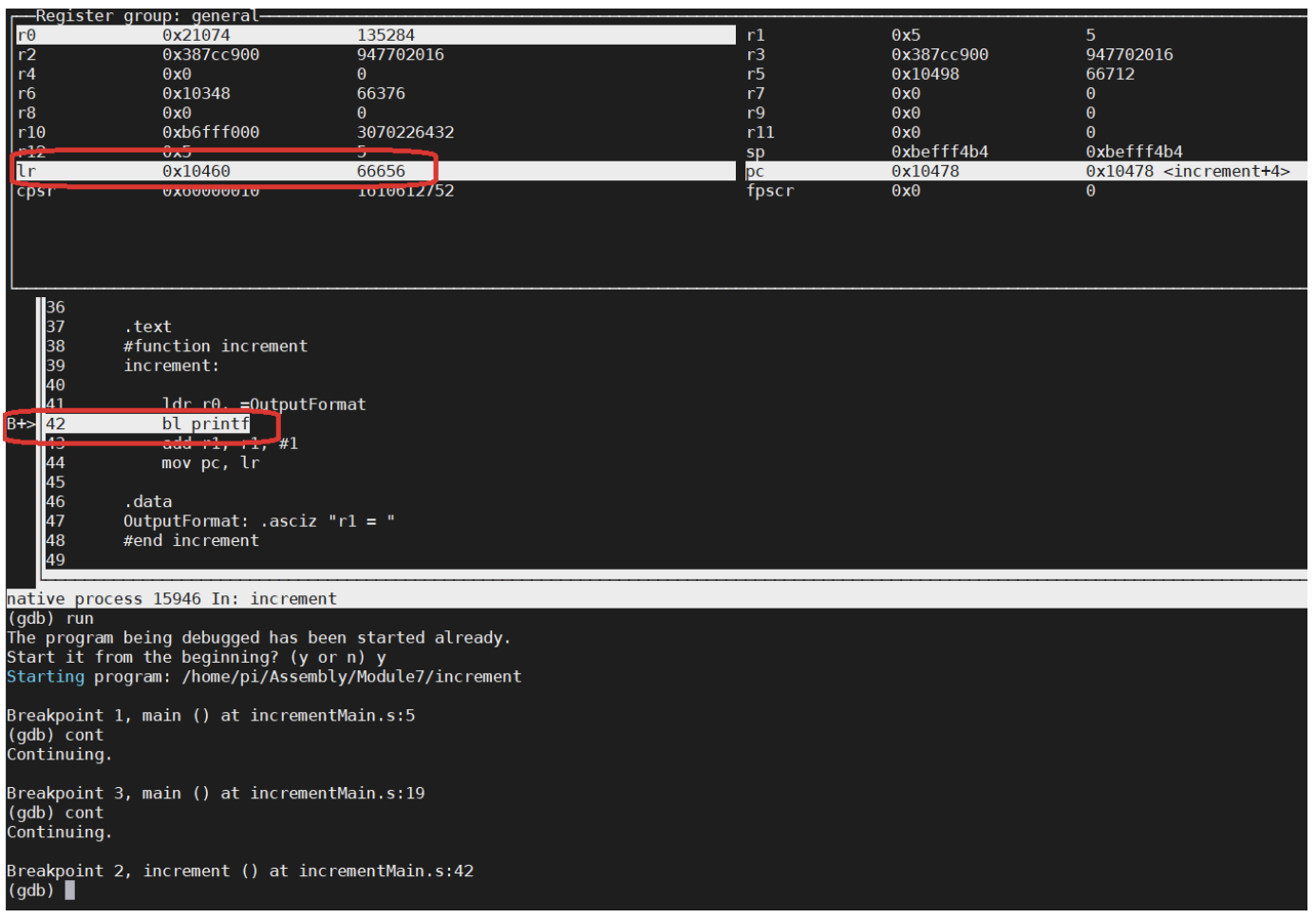
Figure 66: lr before branch printf
Now type next, and notice the value of lr after the call to printf. The call to the function printf has changed it to the current statement, which is the correct place for the function printf to return. But this is not where the function increment should return, and so when the “MOV pc, lr” instruction is executed, it returns to the line “ADD r1, r1, #1” in the current function, creating an infinite loop. This is shown in Figure 67.
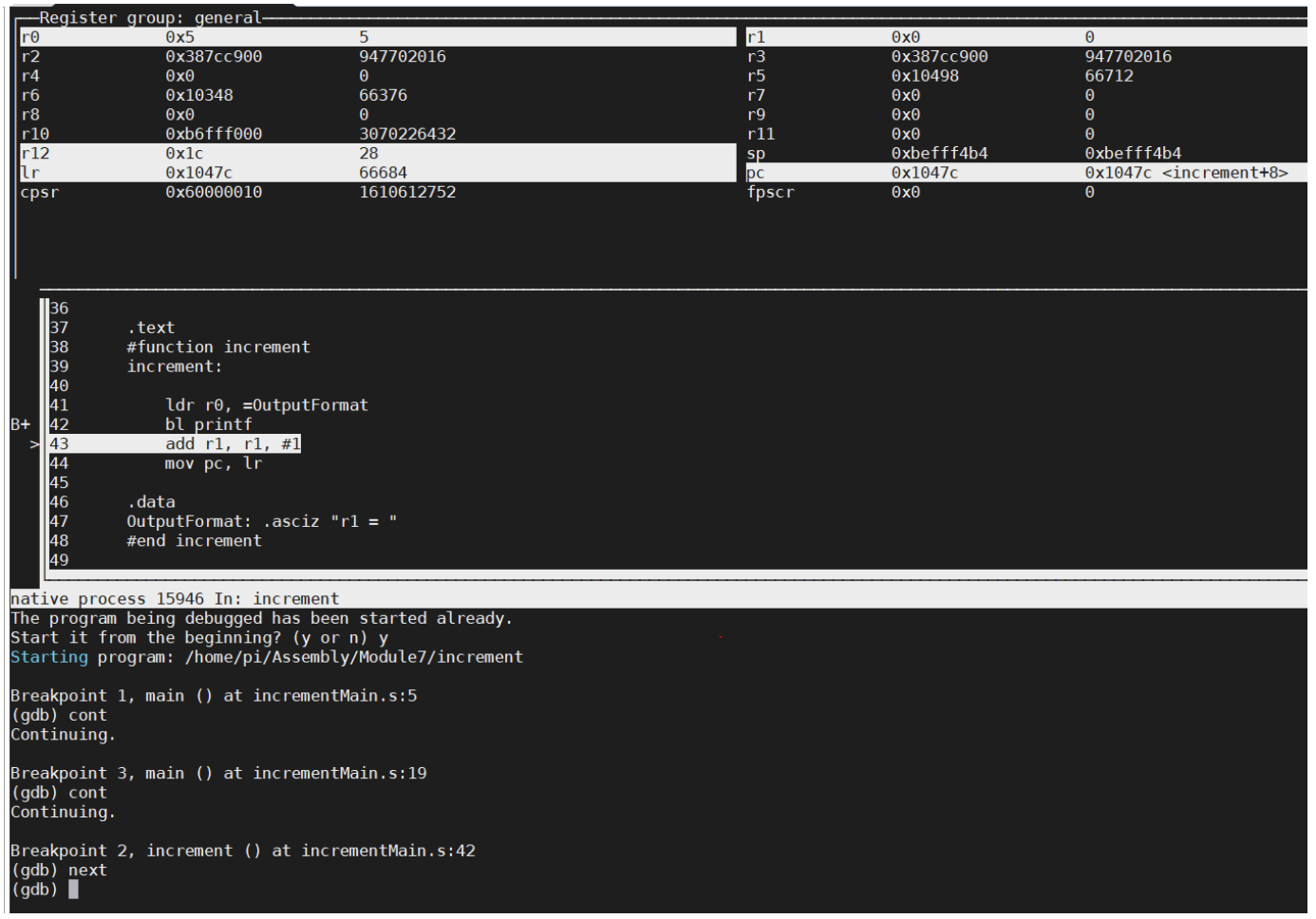
Figure 67: lr after branch to printf
The increment function is a type of function called non-reentrant; it cannot call any other function. Functions that are non-reentrant are often found in the operating system, but nonreentrant functions should be avoided unless there is some very specific use of them.
7.2.2 Fixing the problem with a static variable
To fix this problem, some place needs to be found in memory to store the value of the lr so it can maintain its original value to be used to return to the calling function. Another register is not a solution, as a function branching to another function branching to another function will overwrite that register. A static value can be created, as shown in Program 11, where the lr is stored when entering the function, and then retrieved when exiting the function. This solution was used in early programming language (e.g., FORTRAN versions before FORTRAN 77, COBOL versions before COBOL 2002), but is seldom, if ever, used in current languages. It should be noted that while this solution allows re-entrant function, it does not allow for recursion, as the first call to the function uses the return address variable, and any recursive call to this function will result in the return address being incorrect.
#function increment
increment:
LDR r3, =ra
STR lr, [r3, #0]
LDR r0, =OutputFormat
BL printf
ADD r1, r1, #1
LDR r3, =ra
LDR pc, [r3, #0]
.data
ra: word 0
OutputFormat: .asciz “r1 = “
#end increment
11 Saving the lr using a static .data variable
To solve the problem of saving the return address modern programming languages use a program stack. A program works by allocating a part of memory for each program or thread that is executing. This stack is used to store several pieces of data, but for now it will be used to store the lr.
7.2.3 What is a stack
To see how a program stack works, first it is necessary to understand what a stack is. There are two types of memory that can be allocated when a program is running, stack and heap memory. Heap memory is allocated and deleted in non-standard size chunks, and can be held for different periods of time. That makes heap memory management relatively difficult and time consuming.
A stack allocates fixed size chunks of memory that are allocated in a Last In, First-Out (LIFO) format. This allows the stack to be managed relatively easily and quickly.
The most commonly used metaphor for a stack in a computer is trays in a lunch room. When a tray is returned to the stack, it is placed on top of the stack, and each subsequent tray placed on top of the previous tray. When a patron wants a try, they take the first one off of the top of the tray stack. Hence the last tray returned is the first tray used. To better understand this, note that some trays will be heavily used (those on the top), and some, such as the bottom most tray, might never be used.
In a computer a stack is implemented as an array on which there are two operations, push and pop. The push operation places an item on the top of the stack, and so places the item at the next available spot in the array and adds 1 to an array index to the next available spot. A pop operation removes the top most item, so returns the item on top of the stack, and subtracts 1 from the size of the stack.
The following is an example of how a stack works. This example demonstrates the following operations on the stack:
push(5)
push(7)
push(2)
print(pop())
push(4)
print(pop())
print(pop())
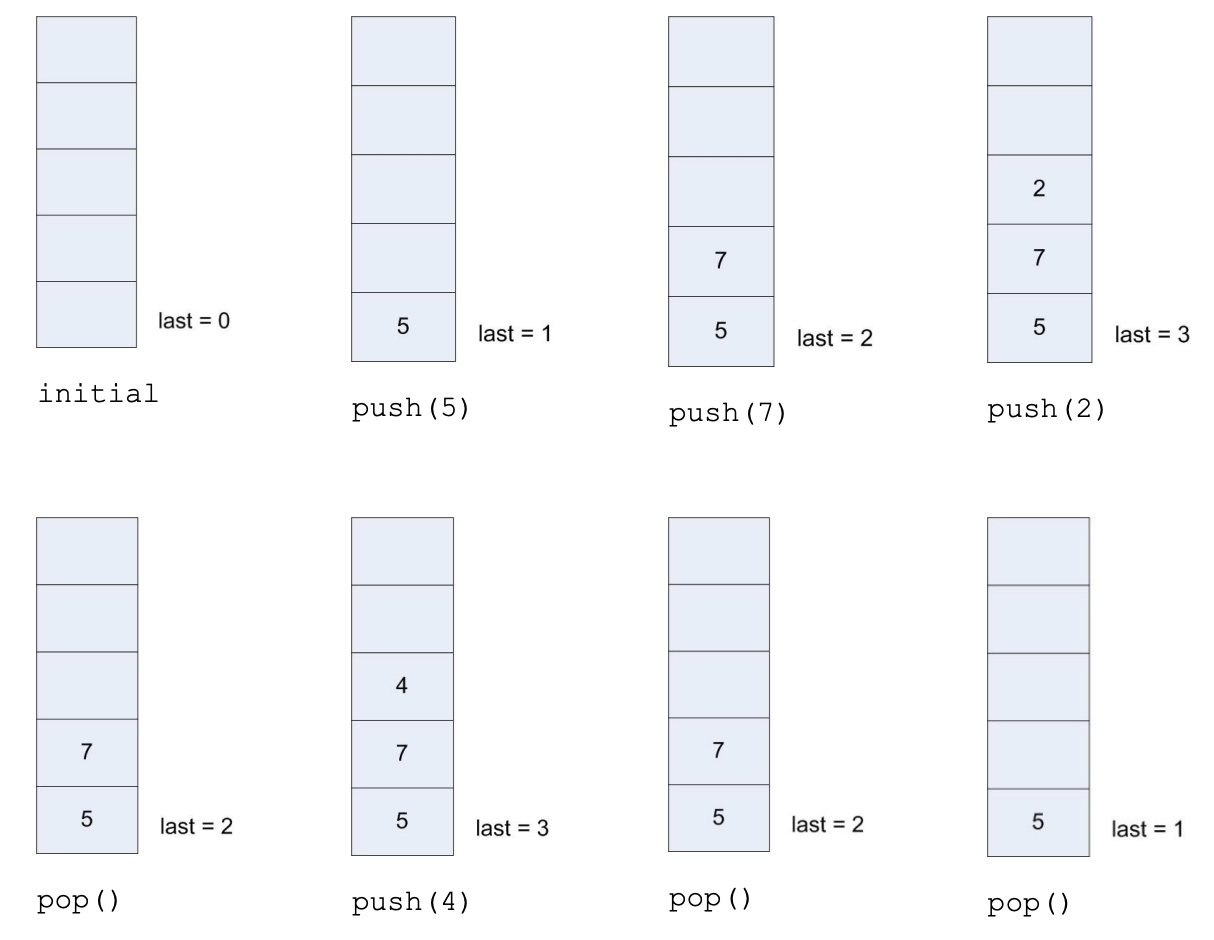
Figure 7: Push/Pop Example 1
The output of the program would be \(2, 4, 7\).
This example has a problem though. It seems to imply that every object pushed onto the stack should be the same size. Consider the following example that pushes the words “black” and “cat” onto a stack. In this example, the value pushed on the stack will be different sizes. The first entry on the stack is the number of spaces that entry requires, and the actual entries follow. This example demonstrates the following operations on the stack:
push(“Black”)
push(“Cat”)
The stack that would be created would be stored in the array of bytes as follows:
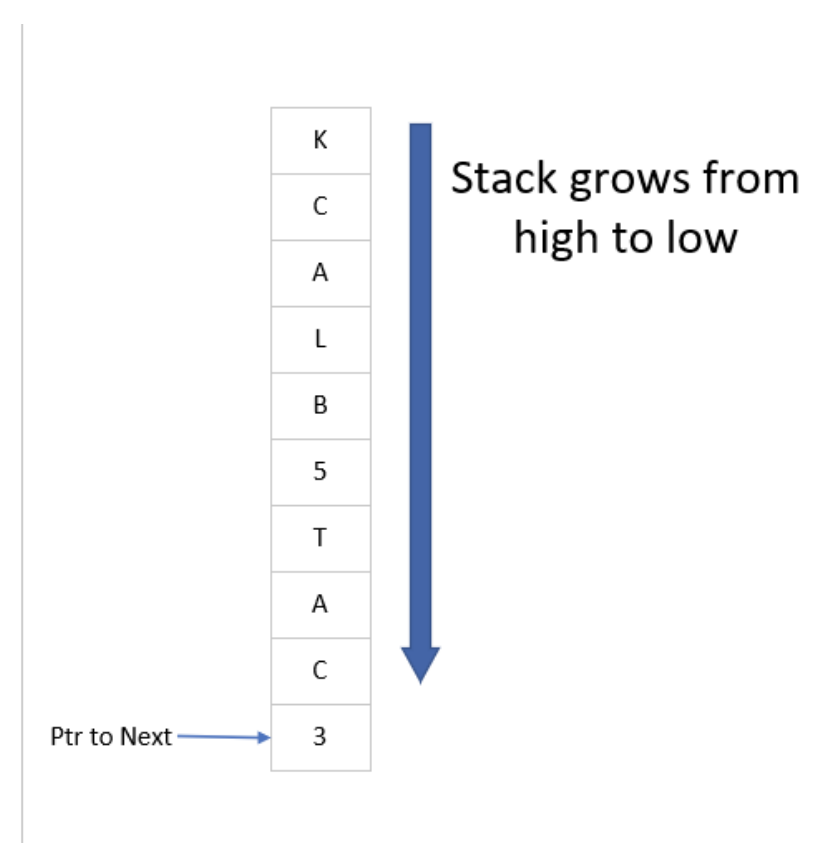
Figure 8: Stack growth
Because the size of the entry (n) is stored with the entry, the entries can be pushed and popped easily by reading the entry at the Ptr to Next entry, and adding n+1 to the pointer. This is how the stack will be implemented in ARM assembly.
7.2.4 The program stack
The program stack is an area of memory that by convention all programmers agree to use as stack memory. A pointer to the last entry in the stack, called the stack pointer or the sp register, is maintained. This points to the beginning of a stack record (or activation record) that maintains data about the function. To create a stack record, the programmer calculates how much space they will need for this stack record. For now, only the lr will be stored, so the size will be 4 bytes, the size of a register. This value is subtracted from the sp, allocating 4 bytes stack record on the stack, and having the sp point to that 4 bytes. The lr is then stored at that point on the stack. When the function is exited, the 4 bytes are subtracted from the sp, returning the memory and causing the sp to point to the stack record for the function that called the current function.
#function increment
increment:
#stack push
SUB sp, 4
STR lr, [sp, #0]
LDR r0, =OutputFormat
BL printf
ADD r1, r1, #1
#stack pop
LDR lr, [sp, #0]
ADD sp, 4
MOV pc, lr
.data
ra: word 0
OutputFormat: .asciz “r1 = “
#end increment
12 Saving the lr using the program stack
Because each function uses this same standard format at the start and end of the function, the function printf no longer interferes with the lr for this function, and the return works correctly.
Observant readers will recognize this is most of the standard code that is placed around the main methods of all programs in this textbook.
This is what is meant by a standard format for the functions, that the stack for the function be pushed when the function is entered, and popped when the function is left. It also means that there is one entry and one exit from any function. You cannot enter a function except at the beginning, and you cannot exit except at the end. Further all code for a function must exist between the push and the pop. This might seem obvious to the reader, but the experience of the author shows that this is far from trivial. The author has seen some pretty egregious violations of this simple rule by experienced programmers, creating situations where the code might work, but is definitely not working as the implementer expected.