
4.2: Shared-Memory Multiprocessors
- Page ID
- 13436

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Introduction
In the mid-1980s, shared-memory multiprocessors were pretty expensive and pretty rare. Now, as hardware costs are dropping, they are becoming commonplace. Many home computer systems in the under-$3000 range have a socket for a second CPU. Home computer operating systems are providing the capability to use more than one processor to improve system performance. Rather than specialized resources locked away in a central computing facility, these shared-memory processors are often viewed as a logical extension of the desktop. These systems run the same operating system (UNIX or NT) as the desktop and many of the same applications from a workstation will execute on these multiprocessor servers.
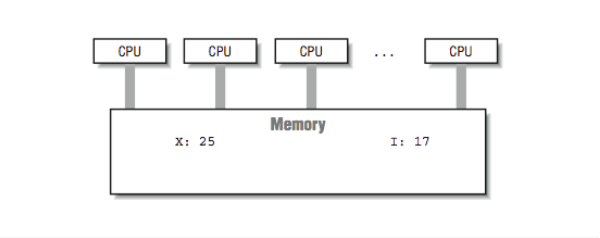
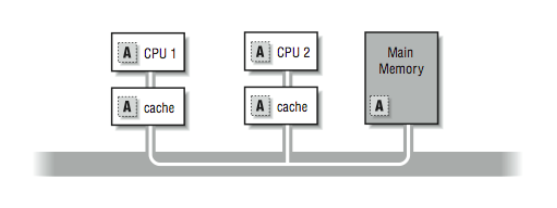
Typically a workstation will have from 1 to 4 processors and a server system will have 4 to 64 processors. Shared-memory multiprocessors have a significant advantage over other multiprocessors because all the processors share the same view of the memory, as shown in [Figure 1].
These processors are also described as uniform memory access (also known as UMA) systems. This designation indicates that memory is equally accessible to all processors with the same performance.
The popularity of these systems is not due simply to the demand for high performance computing. These systems are excellent at providing high throughput for a multiprocessing load, and function effectively as high-performance database servers, network servers, and Internet servers. Within limits, their throughput is increased linearly as more processors are added.
In this book we are not so interested in the performance of database or Internet servers. That is too passé; buy more processors, get better throughput. We are interested in pure, raw, unadulterated compute speed for our high performance application. Instead of running hundreds of small jobs, we want to utilize all $750,000 worth of hardware for our single job.
The challenge is to find techniques that make a program that takes an hour to complete using one processor, complete in less than a minute using 64 processors. This is not trivial. Throughout this book so far, we have been on an endless quest for parallelism. In this and the remaining chapters, we will begin to see the payoff for all of your hard work and dedication!
The cost of a shared-memory multiprocessor can range from $4000 to $30 million. Some example systems include multiple-processor Intel systems from a wide range of vendors, SGI Power Challenge Series, HP/Convex C-Series, DEC AlphaServers, Cray vector/parallel processors, and Sun Enterprise systems. The SGI Origin 2000, HP/Convex Exemplar, Data General AV-20000, and Sequent NUMAQ-2000 all are uniform-memory, symmetric multiprocessing systems that can be linked to form even larger shared nonuniform memory-access systems. Among these systems, as the price increases, the number of CPUs increases, the performance of individual CPUs increases, and the memory performance increases.
In this chapter we will study the hardware and software environment in these systems and learn how to execute our programs on these systems.
Symmetric Multiprocessing Hardware
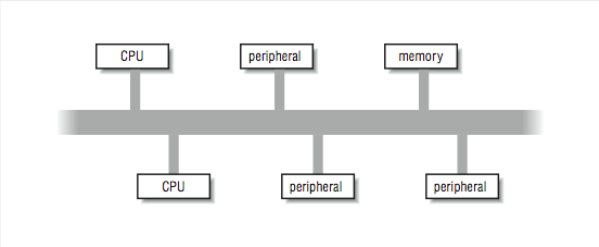
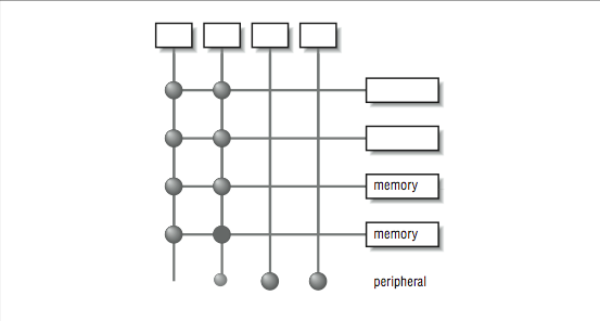
In [Figure 1], we viewed an ideal shared-memory multiprocessor. In this section, we look in more detail at how such a system is actually constructed. The primary advantage of these systems is the ability for any CPU to access all of the memory and peripherals. Furthermore, the systems need a facility for deciding among themselves who has access to what, and when, which means there will have to be hardware support for arbitration. The two most common architectural underpinnings for symmetric multiprocessing are buses and crossbars. The bus is the simplest of the two approaches. [Figure 3] shows processors connected using a bus. A bus can be thought of as a set of parallel wires connecting the components of the computer (CPU, memory, and peripheral controllers), a set of protocols for communication, and some hardware to help carry it out. A bus is less expensive to build, but because all traffic must cross the bus, as the load increases, the bus eventually becomes a performance bottleneck.
A crossbar is a hardware approach to eliminate the bottleneck caused by a single bus. A crossbar is like several buses running side by side with attachments to each of the modules on the machine — CPU, memory, and peripherals. Any module can get to any other by a path through the crossbar, and multiple paths may be active simultaneously. In the 4×5 crossbar of [Figure 3], for instance, there can be four active data transfers in progress at one time. In the diagram it looks like a patchwork of wires, but there is actually quite a bit of hardware that goes into constructing a crossbar. Not only does the crossbar connect parties that wish to communicate, but it must also actively arbitrate between two or more CPUs that want access to the same memory or peripheral. In the event that one module is too popular, it’s the crossbar that decides who gets access and who doesn’t. Crossbars have the best performance because there is no single shared bus. However, they are more expensive to build, and their cost increases as the number of ports is increased. Because of their cost, crossbars typically are only found at the high end of the price and performance spectrum.
Whether the system uses a bus or crossbar, there is only so much memory bandwidth to go around; four or eight processors drawing from one memory system can quickly saturate all available bandwidth. All of the techniques that improve memory performance also apply here in the design of the memory subsystems attached to these buses or crossbars.
The Effect of Cache
The most common multiprocessing system is made up of commodity processors connected to memory and peripherals through a bus. Interestingly, the fact that these processors make use of cache somewhat mitigates the bandwidth bottleneck on a bus-based architecture. By connecting the processor to the cache and viewing the main memory through the cache, we significantly reduce the memory traffic across the bus. In this architecture, most of the memory accesses across the bus take the form of cache line loads and flushes. To understand why, consider what happens when the cache hit rate is very high. In [Figure 4], a high cache hit rate eliminates some of the traffic that would have otherwise gone out across the bus or crossbar to main memory. Again, it is the notion of “locality of reference” that makes the system work. If you assume that a fair number of the memory references will hit in the cache, the equivalent attainable main memory bandwidth is more than the bus is actually capable of. This assumption explains why multiprocessors are designed with less bus bandwidth than the sum of what the CPUs can consume at once.
Imagine a scenario where two CPUs are accessing different areas of memory using unit stride. Both CPUs access the first element in a cache line at the same time. The bus arbitrarily allows one CPU access to the memory. The first CPU fills a cache line and begins to process the data. The instant the first CPU has completed its cache line fill, the cache line fill for the second CPU begins. Once the second cache line fill has completed, the second CPU begins to process the data in its cache line. If the time to process the data in a cache line is longer than the time to fill a cache line, the cache line fill for processor two completes before the next cache line request arrives from processor one. Once the initial conflict is resolved, both processors appear to have conflict-free access to memory for the remainder of their unit-stride loops.
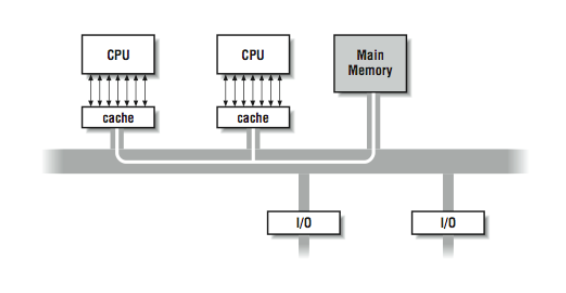
In actuality, on some of the fastest bus-based systems, the memory bus is sufficiently fast that up to 20 processors can access memory using unit stride with very little conflict. If the processors are accessing memory using non-unit stride, bus and memory bank conflict becomes apparent, with fewer processors.
This bus architecture combined with local caches is very popular for general-purpose multiprocessing loads. The memory reference patterns for database or Internet servers generally consist of a combination of time periods with a small working set, and time periods that access large data structures using unit stride. Scientific codes tend to perform more non-unit-stride access than general-purpose codes. For this reason, the most expensive parallel-processing systems targeted at scientific codes tend to use crossbars connected to multibanked memory systems.
The main memory system is better shielded when a larger cache is used. For this reason, multiprocessors sometimes incorporate a two-tier cache system, where each processor uses its own small on-chip local cache, backed up by a larger second board-level cache with as much as 4 MB of memory. Only when neither can satisfy a memory request, or when data has to be written back to main memory, does a request go out over the bus or crossbar.
Coherency
Now, what happens when one CPU of a multiprocessor running a single program in parallel changes the value of a variable, and another CPU tries to read it? Where does the value come from? These questions are interesting because there can be multiple copies of each variable, and some of them can hold old or stale values.
For illustration, say that you are running a program with a shared variable A. Processor 1 changes the value of A and Processor 2 goes to read it.
In [Figure 5], if Processor 1 is keeping A as a register-resident variable, then Processor 2 doesn’t stand a chance of getting the correct value when it goes to look for it. There is no way that 2 can know the contents of 1’s registers; so assume, at the very least, that Processor 1 writes the new value back out. Now the question is, where does the new value get stored? Does it remain in Processor 1’s cache? Is it written to main memory? Does it get updated in Processor 2’s cache?
Really, we are asking what kind of cache coherency protocol the vendor uses to assure that all processors see a uniform view of the values in “memory.” It generally isn’t something that the programmer has to worry about, except that in some cases, it can affect performance. The approaches used in these systems are similar to those used in single-processor systems with some extensions. The most straight-forward cache coherency approach is called a write-through policy : variables written into cache are simultaneously written into main memory. As the update takes place, other caches in the system see the main memory reference being performed. This can be done because all of the caches continuously monitor (also known as snooping ) the traffic on the bus, checking to see if each address is in their cache. If a cache “notices” that it contains a copy of the data from the locations being written, it may either invalidate its copy of the variable or obtain new values (depending on the policy). One thing to note is that a write-through cache demands a fair amount of main memory bandwidth since each write goes out over the main memory bus. Furthermore, successive writes to the same location or bank are subject to the main memory cycle time and can slow the machine down.
A more sophisticated cache coherency protocol is called copyback or writeback. The idea is that you write values back out to main memory only when the cache housing them needs the space for something else. Updates of cached data are coordinated between the caches, by the caches, without help from the processor. Copyback caching also uses hardware that can monitor (snoop) and respond to the memory transactions of the other caches in the system. The benefit of this method over the write-through method is that memory traffic is reduced considerably. Let’s walk through it to see how it works.
Cache Line States
For this approach to work, each cache must maintain a state for each line in its cache. The possible states used in the example include:
- Modified: This cache line needs to be written back to memory.
- Exclusive: There are no other caches that have this cache line.
- Shared: There are read-only copies of this line in two or more caches.
- Empty/Invalid: This cache line doesn’t contain any useful data.
This particular coherency protocol is often called MESI. Other cache coherency protocols are more complicated, but these states give you an idea how multiprocessor writeback cache coherency works.
We start where a particular cache line is in memory and in none of the writeback caches on the systems. The first cache to ask for data from a particular part of memory completes a normal memory access; the main memory system returns data from the requested location in response to a cache miss. The associated cache line is marked exclusive, meaning that this is the only cache in the system containing a copy of the data; it is the owner of the data. If another cache goes to main memory looking for the same thing, the request is intercepted by the first cache, and the data is returned from the first cache — not main memory. Once an interception has occurred and the data is returned, the data is marked shared in both of the caches.
When a particular line is marked shared, the caches have to treat it differently than they would if they were the exclusive owners of the data — especially if any of them wants to modify it. In particular, a write to a shared cache entry is preceded by a broadcast message to all the other caches in the system. It tells them to invalidate their copies of the data. The one remaining cache line gets marked as modified to signal that it has been changed, and that it must be returned to main memory when the space is needed for something else. By these mechanisms, you can maintain cache coherence across the multiprocessor without adding tremendously to the memory traffic.
By the way, even if a variable is not shared, it’s possible for copies of it to show up in several caches. On a symmetric multiprocessor, your program can bounce around from CPU to CPU. If you run for a little while on this CPU, and then a little while on that, your program will have operated out of separate caches. That means that there can be several copies of seemingly unshared variables scattered around the machine. Operating systems often try to minimize how often a process is moved between physical CPUs during context switches. This is one reason not to overload the available processors in a system.
Data Placement
There is one more pitfall regarding shared memory we have so far failed to mention. It involves data movement. Although it would be convenient to think of the multiprocessor memory as one big pool, we have seen that it is actually a carefully crafted system of caches, coherency protocols, and main memory. The problems come when your application causes lots of data to be traded between the caches. Each reference that falls out of a given processor’s cache (especially those that require an update in another processor’s cache) has to go out on the bus.
Often, it’s slower to get memory from another processor’s cache than from the main memory because of the protocol and processing overhead involved. Not only do we need to have programs with high locality of reference and unit stride, we also need to minimize the data that must be moved from one CPU to another.
Multiprocessor Software Concepts
Now that we have examined the way shared-memory multiprocessor hardware operates, we need to examine how software operates on these types of computers. We still have to wait until the next chapters to begin making our FORTRAN programs run in parallel. For now, we use C programs to examine the fundamentals of multiprocessing and multithreading. There are several techniques used to implement multithreading, so the topics we will cover include:
- Operating system–supported multiprocessing
- User space multithreading
- Operating system-supported multithreading
The last of these is what we primarily will use to reduce the walltime of our applications.
Operating System–Supported Multiprocessing
Most modern general-purpose operating systems support some form of multiprocessing. Multiprocessing doesn’t require more than one physical CPU; it is simply the operating system’s ability to run more than one process on the system. The operating system context-switches between each process at fixed time intervals, or on interrupts or input-output activity. For example, in UNIX, if you use the ps command, you can see the processes on the system:
% ps -a PID TTY TIME CMD 28410 pts/34 0:00 tcsh 28213 pts/38 0:00 xterm 10488 pts/51 0:01 telnet 28411 pts/34 0:00 xbiff 11123 pts/25 0:00 pine 3805 pts/21 0:00 elm 6773 pts/44 5:48 ansys ... % ps –a | grep ansys 6773 pts/44 6:00 ansys
For each process we see the process identifier (PID), the terminal that is executing the command, the amount of CPU time the command has used, and the name of the command. The PID is unique across the entire system. Most UNIX commands are executed in a separate process. In the above example, most of the processes are waiting for some type of event, so they are taking very few resources except for memory. Process 67731 seems to be executing and using resources. Running ps again confirms that the CPU time is increasing for the ansys process:
% vmstat 5 procs memory page disk faults cpu r b w swap free re mf pi po fr de sr f0 s0 -- -- in sy cs us sy id 3 0 0 353624 45432 0 0 1 0 0 0 0 0 0 0 0 461 5626 354 91 9 0 3 0 0 353248 43960 0 22 0 0 0 0 0 0 14 0 0 518 6227 385 89 11 0
Running the vmstat 5 command tells us many things about the activity on the system. First, there are three runnable processes. If we had one CPU, only one would actually be running at a given instant. To allow all three jobs to progress, the operating system time-shares between the processes. Assuming equal priority, each process executes about 1/3 of the time. However, this system is a two-processor system, so each process executes about 2/3 of the time. Looking across the vmstat output, we can see paging activity (pi, po), context switches (cs), overall user time (us), system time (sy), and idle time (id ).
Each process can execute a completely different program. While most processes are completely independent, they can cooperate and share information using interprocess communication (pipes, sockets) or various operating system-supported shared-memory areas. We generally don’t use multiprocessing on these shared-memory systems as a technique to increase single-application performance.
Multiprocessing software
In this section, we explore how programs access multiprocessing features.2 In this example, the program creates a new process using the fork( ) function. The new process (child) prints some messages and then changes its identity using exec( ) by loading a new program. The original process (parent) prints some messages and then waits for the child process to complete:
int globvar; /* A global variable */
main () {
int pid,status,retval;
int stackvar; /* A stack variable */
globvar = 1;
stackvar = 1;
printf("Main - calling fork globvar=%d stackvar=%d\n",globvar,stackvar);
pid = fork();
printf("Main - fork returned pid=%d\n",pid);
if ( pid == 0 ) {
printf("Child - globvar=%d stackvar=%d\n",globvar,stackvar);
sleep(1);
printf("Child - woke up globvar=%d stackvar=%d\n",globvar,stackvar);
globvar = 100;
stackvar = 100;
printf("Child - modified globvar=%d stackvar=%d\n",globvar,stackvar);
retval = execl("/bin/date", (char *) 0 );
printf("Child - WHY ARE WE HERE retval=%d\n",retval);
} else {
printf("Parent - globvar=%d stackvar=%d\n",globvar,stackvar);
globvar = 5;
stackvar = 5;
printf("Parent - sleeping globvar=%d stackvar=%d\n",globvar,stackvar);
sleep(2);
printf("Parent - woke up globvar=%d stackvar=%d\n",globvar,stackvar);
printf("Parent - waiting for pid=%d\n",pid);
retval = wait(&status);
status = status >> 8; /* Return code in bits 15-8 */
printf("Parent - status=%d retval=%d\n",status,retval);
}
}
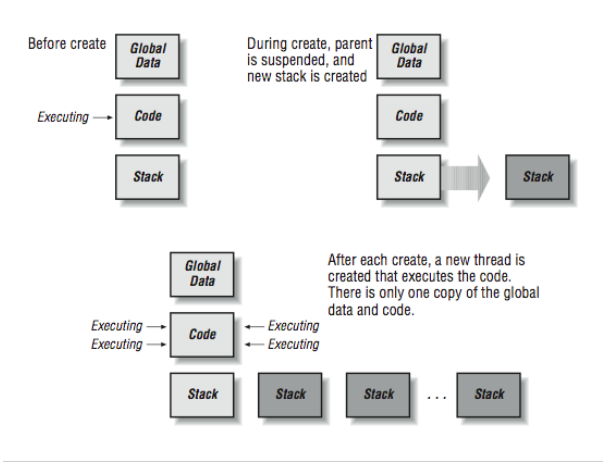
The key to understanding this code is to understand how the fork( ) function operates. The simple summary is that the fork( ) function is called once in a process and returns twice, once in the original process and once in a newly created process. The newly created process is an identical copy of the original process. All the variables (local and global) have been duplicated. Both processes have access to all of the open files of the original process. [Figure 6] shows how the fork operation creates a new process.
The only difference between the processes is that the return value from the fork( ) function call is 0 in the new (child) process and the process identifier (shown by the ps command) in the original (parent) process. This is the program output:
recs % cc -o fork fork.c
recs % fork
Main - calling fork globvar=1 stackvar=1
Main - fork returned pid=19336
Main - fork returned pid=0
Parent - globvar=1 stackvar=1
Parent - sleeping globvar=5 stackvar=5
Child - globvar=1 stackvar=1
Child - woke up globvar=1 stackvar=1
Child - modified globvar=100 stackvar=100
Thu Nov 6 22:40:33
Parent - woke up globvar=5 stackvar=5
Parent - waiting for pid=19336
Parent - status=0 retval=19336
recs %
Tracing this through, first the program sets the global and stack variable to one and then calls fork( ). During the fork( ) call, the operating system suspends the process, makes an exact duplicate of the process, and then restarts both processes. You can see two messages from the statement immediately after the fork. The first line is coming from the original process, and the second line is coming from the new process. If you were to execute a ps command at this moment in time, you would see two processes running called “fork.” One would have a process identifier of 19336.

As both processes start, they execute an IF-THEN-ELSE and begin to perform different actions in the parent and child. Notice that globvar and stackvar are set to 5 in the parent, and then the parent sleeps for two seconds. At this point, the child begins executing. The values for globvar and stackvar are unchanged in the child process. This is because these two processes are operating in completely independent memory spaces. The child process sleeps for one second and sets its copies of the variables to 100. Next, the child process calls the execl( ) function to overwrite its memory space with the UNIX date program. Note that the execl( ) never returns; the date program takes over all of the resources of the child process. If you were to do a ps at this moment in time, you still see two processes on the system but process 19336 would be called “date.” The date command executes, and you can see its output.3
The parent wakes up after a brief two-second sleep and notices that its copies of global and local variables have not been changed by the action of the child process. The parent then calls the wait( ) function to determine if any of its children exited. The wait( ) function returns which child has exited and the status code returned by that child process (in this case, process 19336).
User Space Multithreading
A thread is different from a process. When you add threads, they are added to the existing process rather than starting in a new process. Processes start with a single thread of execution and can add or remove threads throughout the duration of the program. Unlike processes, which operate in different memory spaces, all threads in a process share the same memory space. [Figure 7] shows how the creation of a thread differs from the creation of a process. Not all of the memory space in a process is shared between all threads. In addition to the global area that is shared across all threads, each thread has a thread private area for its own local variables. It’s important for programmers to know when they are working with shared variables and when they are working with local variables.
When attempting to speed up high performance computing applications, threads have the advantage over processes in that multiple threads can cooperate and work on a shared data structure to hasten the computation. By dividing the work into smaller portions and assigning each smaller portion to a separate thread, the total work can be completed more quickly.
Multiple threads are also used in high performance database and Internet servers to improve the overall throughput of the server. With a single thread, the program can either be waiting for the next network request or reading the disk to satisfy the previous request. With multiple threads, one thread can be waiting for the next network transaction while several other threads are waiting for disk I/O to complete.
The following is an example of a simple multithreaded application.4 It begins with a single master thread that creates three additional threads. Each thread prints some messages, accesses some global and local variables, and then terminates:
#define_REENTRANT /* basic lines for threads */
#include <stdio.h>
#include <pthread.h>
#define THREAD_COUNT 3
void *TestFunc(void *);
int globvar; /* A global variable */
int index[THREAD_COUNT] /* Local zero-based thread index */
pthread_t thread_id[THREAD_COUNT]; /* POSIX Thread IDs */
main() {
int i,retval;
pthread_t tid;
globvar = 0;
printf("Main - globvar=%d\n",globvar);
for(i=0;i<THREAD_COUNT;i++) {
index[i] = i;
retval = pthread_create(&tid,NULL,TestFunc,(void *) index[i]);
printf("Main - creating i=%d tid=%d retval=%d\n",i,tid,retval);
thread_id[i] = tid;
}
printf("Main thread - threads started globvar=%d\n",globvar);
for(i=0;i<THREAD_COUNT;i++) {
printf("Main - waiting for join %d\n",thread_id[i]);
retval = pthread_join( thread_id[i], NULL ) ;
printf("Main - back from join %d retval=%d\n",i,retval);
}
printf("Main thread - threads completed globvar=%d\n",globvar);
}
void *TestFunc(void *parm) {
int me,self;
me = (int) parm; /* My own assigned thread ordinal */
self = pthread_self(); /* The POSIX Thread library thread number */
printf("TestFunc me=%d - self=%d globvar=%d\n",me,self,globvar);
globvar = me + 15;
printf("TestFunc me=%d - sleeping globvar=%d\n",me,globvar);
sleep(2);
printf("TestFunc me=%d - done param=%d globvar=%d\n",me,self,globvar);
}
The global shared areas in this case are those variables declared in the static area outside the main( ) code. The local variables are any variables declared within a routine. When threads are added, each thread gets its own function call stack. In C, the automatic variables that are declared at the beginning of each routine are allocated on the stack. As each thread enters a function, these variables are separately allocated on that particular thread’s stack. So these are the thread-local variables.
Unlike the fork( ) function, the pthread_create( ) function creates a new thread, and then control is returned to the calling thread. One of the parameters of the pthread_create( ) is the name of a function.
New threads begin execution in the function TestFunc( ) and the thread finishes when it returns from this function. When this program is executed, it produces the following output:
recs % cc -o create1 -lpthread -lposix4 create1.c
recs % create1
Main - globvar=0
Main - creating i=0 tid=4 retval=0
Main - creating i=1 tid=5 retval=0
Main - creating i=2 tid=6 retval=0
Main thread - threads started globvar=0
Main - waiting for join 4
TestFunc me=0 - self=4 globvar=0
TestFunc me=0 - sleeping globvar=15
TestFunc me=1 - self=5 globvar=15
TestFunc me=1 - sleeping globvar=16
TestFunc me=2 - self=6 globvar=16
TestFunc me=2 - sleeping globvar=17
TestFunc me=2 - done param=6 globvar=17
TestFunc me=1 - done param=5 globvar=17
TestFunc me=0 - done param=4 globvar=17
Main - back from join 0 retval=0
Main - waiting for join 5
Main - back from join 1 retval=0
Main - waiting for join 6
Main - back from join 2 retval=0
Main thread – threads completed globvar=17
recs %
You can see the threads getting created in the loop. The master thread completes the pthread_create( ) loop, executes the second loop, and calls the pthread_join( ) function. This function suspends the master thread until the specified thread completes. The master thread is waiting for Thread 4 to complete. Once the master thread suspends, one of the new threads is started. Thread 4 starts executing. Initially the variable globvar is set to 0 from the main program. The self, me, and param variables are thread-local variables, so each thread has its own copy. Thread 4 sets globvar to 15 and goes to sleep. Then Thread 5 begins to execute and sees globvar set to 15 from Thread 4; Thread 5 sets globvar to 16, and goes to sleep. This activates Thread 6, which sees the current value for globvar and sets it to 17. Then Threads 6, 5, and 4 wake up from their sleep, all notice the latest value of 17 in globvar, and return from the TestFunc( ) routine, ending the threads.
All this time, the master thread is in the middle of a pthread_join( ) waiting for Thread 4 to complete. As Thread 4 completes, the pthread_join( ) returns. The master thread then calls pthread_join( ) repeatedly to ensure that all three threads have been completed. Finally, the master thread prints out the value for globvar that contains the latest value of 17.
To summarize, when an application is executing with more than one thread, there are shared global areas and thread private areas. Different threads execute at different times, and they can easily work together in shared areas.
Limitations of user space multithreading
Multithreaded applications were around long before multiprocessors existed. It is quite practical to have multiple threads with a single CPU. As a matter of fact, the previous example would run on a system with any number of processors, including one. If you look closely at the code, it performs a sleep operation at each critical point in the code. One reason to add the sleep calls is to slow the program down enough that you can actually see what is going on. However, these sleep calls also have another effect. When one thread enters the sleep routine, it causes the thread library to search for other “runnable” threads. If a runnable thread is found, it begins executing immediately while the calling thread is “sleeping.” This is called a user-space thread context switch. The process actually has one operating system thread shared among several logical user threads. When library routines (such as sleep) are called, the thread library5 jumps in and reschedules threads.
We can explore this effect by substituting the following SpinFunc( ) function, replacing TestFunc( ) function in the pthread_create( ) call in the previous example:
void *SpinFunc(void *parm) {
int me;
me = (int) parm;
printf("SpinFunc me=%d - sleeping %d seconds ...\n", me, me+1);
sleep(me+1);
printf("SpinFunc me=%d – wake globvar=%d...\n", me, globvar);
globvar ++;
printf("SpinFunc me=%d - spinning globvar=%d...\n", me, globvar);
while(globvar < THREAD_COUNT ) ;
printf("SpinFunc me=%d – done globvar=%d...\n", me, globvar);
sleep(THREAD_COUNT+1);
}
If you look at the function, each thread entering this function prints a message and goes to sleep for 1, 2, and 3 seconds. Then the function increments globvar (initially set to 0 in main) and begins a while-loop, continuously checking the value of globvar. As time passes, the second and third threads should finish their sleep( ), increment the value for globvar, and begin the while-loop. When the last thread reaches the loop, the value for globvar is 3 and all the threads exit the loop. However, this isn’t what happens:
recs % create2 &
[1] 23921
recs %
Main - globvar=0
Main - creating i=0 tid=4 retval=0
Main - creating i=1 tid=5 retval=0
Main - creating i=2 tid=6 retval=0
Main thread - threads started globvar=0
Main - waiting for join 4
SpinFunc me=0 - sleeping 1 seconds ...
SpinFunc me=1 - sleeping 2 seconds ...
SpinFunc me=2 - sleeping 3 seconds ...
SpinFunc me=0 - wake globvar=0...
SpinFunc me=0 - spinning globvar=1...
recs % ps
PID TTY TIME CMD
23921 pts/35 0:09 create2
recs % ps
PID TTY TIME CMD
23921 pts/35 1:16 create2
recs % kill -9 23921
[1] Killed create2
recs %
We run the program in the background6 and everything seems to run fine. All the threads go to sleep for 1, 2, and 3 seconds. The first thread wakes up and starts the loop waiting for globvar to be incremented by the other threads. Unfortunately, with user space threads, there is no automatic time sharing. Because we are in a CPU loop that never makes a system call, the second and third threads never get scheduled so they can complete their sleep( ) call. To fix this problem, we need to make the following change to the code:
while(globvar < THREAD_COUNT ) sleep(1) ;
With this sleep7 call, Threads 2 and 3 get a chance to be “scheduled.” They then finish their sleep calls, increment the globvar variable, and the program terminates properly.
You might ask the question, “Then what is the point of user space threads?” Well, when there is a high performance database server or Internet server, the multiple logical threads can overlap network I/O with database I/O and other background computations. This technique is not so useful when the threads all want to perform simultaneous CPU-intensive computations. To do this, you need threads that are created, managed, and scheduled by the operating system rather than a user library.
Operating System-Supported Multithreading
When the operating system supports multiple threads per process, you can begin to use these threads to do simultaneous computational activity. There is still no requirement that these applications be executed on a multiprocessor system. When an application that uses four operating system threads is executed on a single processor machine, the threads execute in a time-shared fashion. If there is no other load on the system, each thread gets 1/4 of the processor. While there are good reasons to have more threads than processors for noncompute applications, it’s not a good idea to have more active threads than processors for compute-intensive applications because of thread-switching overhead. (For more detail on the effect of too many threads, see Appendix D, How FORTRAN Manages Threads at Runtime.
If you are using the POSIX threads library, it is a simple modification to request that your threads be created as operating-system rather rather than user threads, as the following code shows:
#define _REENTRANT /* basic 3-lines for threads */
#include <stdio.h>
#include <pthread.h>
#define THREAD_COUNT 2
void *SpinFunc(void *);
int globvar; /* A global variable */
int index[THREAD_COUNT]; /* Local zero-based thread index */
pthread_t thread_id[THREAD_COUNT]; /* POSIX Thread IDs */
pthread_attr_t attr; /* Thread attributes NULL=use default */
main() {
int i,retval;
pthread_t tid;
globvar = 0;
pthread_attr_init(&attr); /* Initialize attr with defaults */
pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
printf("Main - globvar=%d\n",globvar);
for(i=0;i<THREAD_COUNT;i++) {
index[i] = i;
retval = pthread_create(&tid,&attr,SpinFunc,(void *) index[i]);
printf("Main - creating i=%d tid=%d retval=%d\n",i,tid,retval);
thread_id[i] = tid;
}
printf("Main thread - threads started globvar=%d\n",globvar);
for(i=0;i<THREAD_COUNT;i++) {
printf("Main - waiting for join %d\n",thread_id[i]);
retval = pthread_join( thread_id[i], NULL ) ;
printf("Main - back from join %d retval=%d\n",i,retval);
}
printf("Main thread - threads completed globvar=%d\n",globvar);
}
The code executed by the master thread is modified slightly. We create an “attribute” data structure and set the PTHREAD_SCOPE_SYSTEM attribute to indicate that we would like our new threads to be created and scheduled by the operating system. We use the attribute information on the call to pthread_create( ). None of the other code has been changed. The following is the execution output of this new program:
recs % create3
Main - globvar=0
Main - creating i=0 tid=4 retval=0
SpinFunc me=0 - sleeping 1 seconds ...
Main - creating i=1 tid=5 retval=0
Main thread - threads started globvar=0
Main - waiting for join 4
SpinFunc me=1 - sleeping 2 seconds ...
SpinFunc me=0 - wake globvar=0...
SpinFunc me=0 - spinning globvar=1...
SpinFunc me=1 - wake globvar=1...
SpinFunc me=1 - spinning globvar=2...
SpinFunc me=1 - done globvar=2...
SpinFunc me=0 - done globvar=2...
Main - back from join 0 retval=0
Main - waiting for join 5
Main - back from join 1 retval=0
Main thread - threads completed globvar=2
recs %
Now the program executes properly. When the first thread starts spinning, the operating system is context switching between all three threads. As the threads come out of their sleep( ), they increment their shared variable, and when the final thread increments the shared variable, the other two threads instantly notice the new value (because of the cache coherency protocol) and finish the loop. If there are fewer than three CPUs, a thread may have to wait for a time-sharing context switch to occur before it notices the updated global variable.
With operating-system threads and multiple processors, a program can realistically break up a large computation between several independent threads and compute the solution more quickly. Of course this presupposes that the computation could be done in parallel in the first place.
Techniques for Multithreaded Programs
Given that we have multithreaded capabilities and multiprocessors, we must still convince the threads to work together to accomplish some overall goal. Often we need some ways to coordinate and cooperate between the threads. There are several important techniques that are used while the program is running with multiple threads, including:
- Fork-join (or create-join) programming
- Synchronization using a critical section with a lock, semaphore, or mutex
- Barriers
Each of these techniques has an overhead associated with it. Because these overheads are necessary to go parallel, we must make sure that we have sufficient work to make the benefit of parallel operation worth the cost.
Fork-Join Programming
This approach is the simplest method of coordinating your threads. As in the earlier examples in this chapter, a master thread sets up some global data structures that describe the tasks each thread is to perform and then use the pthread_create( ) function to activate the proper number of threads. Each thread checks the global data structure using its thread-id as an index to find its task. The thread then performs the task and completes. The master thread waits at a pthread_join( ) point, and when a thread has completed, it updates the global data structure and creates a new thread. These steps are repeated for each major iteration (such as a time-step) for the duration of the program:
for(ts=0;ts<10000;ts++) { /* Time Step Loop */
/* Setup tasks */
for (ith=0;ith<NUM_THREADS;ith++) pthread_create(..,work_routine,..)
for (ith=0;ith<NUM_THREADS;ith++) pthread_join(...)
}
work_routine() {
/* Perform Task */
return;
}
The shortcoming of this approach is the overhead cost associated with creating and destroying an operating system thread for a potentially very short task.
The other approach is to have the threads created at the beginning of the program and to have them communicate amongst themselves throughout the duration of the application. To do this, they use such techniques as critical sections or barriers.
Synchronization
Synchronization is needed when there is a particular operation to a shared variable that can only be performed by one processor at a time. For example, in previous SpinFunc( ) examples, consider the line:
globvar++;
In assembly language, this takes at least three instructions:
LOAD R1,globvar
ADD R1,1
STORE R1,globvar
What if globvar contained 0, Thread 1 was running, and, at the precise moment it completed the LOAD into Register R1 and before it had completed the ADD or STORE instructions, the operating system interrupted the thread and switched to Thread 2? Thread 2 catches up and executes all three instructions using its registers: loading 0, adding 1 and storing the 1 back into globvar. Now Thread 2 goes to sleep and Thread 1 is restarted at the ADD instruction. Register R1 for Thread 1 contains the previously loaded value of 0; Thread 1 adds 1 and then stores 1 into globvar. What is wrong with this picture? We meant to use this code to count the number of threads that have passed this point. Two threads passed the point, but because of a bad case of bad timing, our variable indicates only that one thread passed. This is because the increment of a variable in memory is not atomic. That is, halfway through the increment, something else can happen.
Another way we can have a problem is on a multiprocessor when two processors execute these instructions simultaneously. They both do the LOAD, getting 0. Then they both add 1 and store 1 back to memory.8 Which processor actually got the honor of storing their 1 back to memory is simply a race.
We must have some way of guaranteeing that only one thread can be in these three instructions at the same time. If one thread has started these instructions, all other threads must wait to enter until the first thread has exited. These areas are called critical sections. On single-CPU systems, there was a simple solution to critical sections: you could turn off interrupts for a few instructions and then turn them back on. This way you could guarantee that you would get all the way through before a timer or other interrupt occurred:
INTOFF // Turn off Interrupts
LOAD R1,globvar
ADD R1,1
STORE R1,globvar
INTON // Turn on Interrupts
However, this technique does not work for longer critical sections or when there is more than one CPU. In these cases, you need a lock, a semaphore, or a mutex. Most thread libraries provide this type of routine. To use a mutex, we have to make some modifications to our example code:
...
pthread_mutex_t my_mutex; /* MUTEX data structure */
...
main() {
...
pthread_attr_init(&attr); /* Initialize attr with defaults */
pthread_mutex_init (&my_mutex, NULL);
.... pthread_create( ... )
...
}
void *SpinFunc(void *parm) {
...
pthread_mutex_lock (&my_mutex);
globvar ++;
pthread_mutex_unlock (&my_mutex);
while(globvar < THREAD_COUNT ) ;
printf("SpinFunc me=%d – done globvar=%d...\n", me, globvar);
...
}
The mutex data structure must be declared in the shared area of the program. Before the threads are created, pthread_mutex_init must be called to initialize the mutex. Before globvar is incremented, we must lock the mutex and after we finish updating globvar (three instructions later), we unlock the mutex. With the code as shown above, there will never be more than one processor executing the globvar++ line of code, and the code will never hang because an increment was missed. Semaphores and locks are used in a similar way.
Interestingly, when using user space threads, an attempt to lock an already locked mutex, semaphore, or lock can cause a thread context switch. This allows the thread that “owns” the lock a better chance to make progress toward the point where they will unlock the critical section. Also, the act of unlocking a mutex can cause the thread waiting for the mutex to be dispatched by the thread library.
Barriers
Barriers are different than critical sections. Sometimes in a multithreaded application, you need to have all threads arrive at a point before allowing any threads to execute beyond that point. An example of this is a time-based simulation. Each task processes its portion of the simulation but must wait until all of the threads have completed the current time step before any thread can begin the next time step. Typically threads are created, and then each thread executes a loop with one or more barriers in the loop. The rough pseudocode for this type of approach is as follows:
main() {
for (ith=0;ith<NUM_THREADS;ith++) pthread_create(..,work_routine,..)
for (ith=0;ith<NUM_THREADS;ith++) pthread_join(...) /* Wait a long time */
exit()
}
work_routine() {
for(ts=0;ts<10000;ts++) { /* Time Step Loop */
/* Compute total forces on particles */
wait_barrier();
/* Update particle positions based on the forces */
wait_barrier();
}
return;
}
In a sense, our SpinFunc( ) function implements a barrier. It sets a variable initially to 0. Then as threads arrive, the variable is incremented in a critical section. Immediately after the critical section, the thread spins until the precise moment that all the threads are in the spin loop, at which time all threads exit the spin loop and continue on.
For a critical section, only one processor can be executing in the critical section at the same time. For a barrier, all processors must arrive at the barrier before any of the processors can leave.
A Real Example
In all of the above examples, we have focused on the mechanics of shared memory, thread creation, and thread termination. We have used the sleep( ) routine to slow things down sufficiently to see interactions between processes. But we want to go very fast, not just learn threading for threading’s sake.
The example code below uses the multithreading techniques described in this chapter to speed up a sum of a large array. The hpcwall routine is from [Section 2.2].
This code allocates a four-million-element double-precision array and fills it with random numbers between 0 and 1. Then using one, two, three, and four threads, it sums up the elements in the array:
#define _REENTRANT /* basic 3-lines for threads */
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define MAX_THREAD 4
void *SumFunc(void *);
int ThreadCount; /* Threads on this try */
double GlobSum; /* A global variable */
int index[MAX_THREAD]; /* Local zero-based thread index */
pthread_t thread_id[MAX_THREAD]; /* POSIX Thread IDs */
pthread_attr_t attr; /* Thread attributes NULL=use default */
pthread_mutex_t my_mutex; /* MUTEX data structure */
#define MAX_SIZE 4000000
double array[MAX_SIZE]; /* What we are summing... */
void hpcwall(double *);
main() {
int i,retval;
pthread_t tid;
double single,multi,begtime,endtime;
/* Initialize things */
for (i=0; i<MAX_SIZE; i++) array[i] = drand48();
pthread_attr_init(&attr); /* Initialize attr with defaults */
pthread_mutex_init (&my_mutex, NULL);
pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
/* Single threaded sum */
GlobSum = 0;
hpcwall(&begtime);
for(i=0; i<MAX_SIZE;i++) GlobSum = GlobSum + array[i];
hpcwall(&endtime);
single = endtime - begtime;
printf("Single sum=%lf time=%lf\n",GlobSum,single);
/* Use different numbers of threads to accomplish the same thing */
for(ThreadCount=2;ThreadCount<=MAX_THREAD; ThreadCount++) {
printf("Threads=%d\n",ThreadCount);
GlobSum = 0;
hpcwall(&begtime);
for(i=0;i<ThreadCount;i++) {
index[i] = i;
retval = pthread_create(&tid,&attr,SumFunc,(void *) index[i]);
thread_id[i] = tid;
}
for(i=0;i<ThreadCount;i++) retval = pthread_join(thread_id[i],NULL);
hpcwall(&endtime);
multi = endtime - begtime;
printf("Sum=%lf time=%lf\n",GlobSum,multi);
printf("Efficiency = %lf\n",single/(multi*ThreadCount));
} /* End of the ThreadCount loop */
}
void *SumFunc(void *parm){
int i,me,chunk,start,end;
double LocSum;
/* Decide which iterations belong to me */
me = (int) parm;
chunk = MAX_SIZE / ThreadCount;
start = me * chunk;
end = start + chunk; /* C-Style - actual element + 1 */
if ( me == (ThreadCount-1) ) end = MAX_SIZE;
printf("SumFunc me=%d start=%d end=%d\n",me,start,end);
/* Compute sum of our subset*/
LocSum = 0;
for(i=start;i<end;i++ ) LocSum = LocSum + array[i];
/* Update the global sum and return to the waiting join */
pthread_mutex_lock (&my_mutex);
GlobSum = GlobSum + LocSum;
pthread_mutex_unlock (&my_mutex);
}
First, the code performs the sum using a single thread using a for-loop. Then for each of the parallel sums, it creates the appropriate number of threads that call SumFunc( ). Each thread starts in SumFunc( ) and initially chooses an area to operation in the shared array. The “strip” is chosen by dividing the overall array up evenly among the threads with the last thread getting a few extra if the division has a remainder.
Then, each thread independently performs the sum on its area. When a thread has finished its computation, it uses a mutex to update the global sum variable with its contribution to the global sum:
recs % addup
Single sum=7999998000000.000000 time=0.256624
Threads=2
SumFunc me=0 start=0 end=2000000
SumFunc me=1 start=2000000 end=4000000
Sum=7999998000000.000000 time=0.133530
Efficiency = 0.960923
Threads=3
SumFunc me=0 start=0 end=1333333
SumFunc me=1 start=1333333 end=2666666
SumFunc me=2 start=2666666 end=4000000
Sum=7999998000000.000000 time=0.091018
Efficiency = 0.939829
Threads=4
SumFunc me=0 start=0 end=1000000
SumFunc me=1 start=1000000 end=2000000
SumFunc me=2 start=2000000 end=3000000
SumFunc me=3 start=3000000 end=4000000
Sum=7999998000000.000000 time=0.107473
Efficiency = 0.596950
recs %
There are some interesting patterns. Before you interpret the patterns, you must know that this system is a three-processor Sun Enterprise 3000. Note that as we go from one to two threads, the time is reduced to one-half. That is a good result given how much it costs for that extra CPU. We characterize how well the additional resources have been used by computing an efficiency factor that should be 1.0. This is computed by multiplying the wall time by the number of threads. Then the time it takes on a single processor is divided by this number. If you are using the extra processors well, this evaluates to 1.0. If the extra processors are used pretty well, this would be about 0.9. If you had two threads, and the computation did not speed up at all, you would get 0.5.
At two and three threads, wall time is dropping, and the efficiency is well over 0.9. However, at four threads, the wall time increases, and our efficiency drops very dramatically. This is because we now have more threads than processors. Even though we have four threads that could execute, they must be time-sliced between three processors.9 This is even worse that it might seem. As threads are switched, they move from processor to processor and their caches must also move from processor to processor, further slowing performance. This cache-thrashing effect is not too apparent in this example because the data structure is so large, most memory references are not to values previously in cache.
It’s important to note that because of the nature of floating-point (see [Section 1.2]), the parallel sum may not be the same as the serial sum. To perform a summation in parallel, you must be willing to tolerate these slight variations in your results.
Closing Notes
As they drop in price, multiprocessor systems are becoming far more common. These systems have many attractive features, including good price/performance, compatibility with workstations, large memories, high throughput, large shared memories, fast I/O, and many others. While these systems are strong in multiprogrammed server roles, they are also an affordable high performance computing resource for many organizations. Their cache-coherent shared-memory model allows multithreaded applications to be easily developed.
We have also examined some of the software paradigms that must be used to develop multithreaded applications. While you hopefully will never have to write C code with explicit threads like the examples in this chapter, it is nice to understand the fundamental operations at work on these multiprocessor systems. Using the FORTRAN language with an automatic parallelizing compiler, we have the advantage that these and many more details are left to the FORTRAN compiler and runtime library. At some point, especially on the most advanced architectures, you may have to explicitly program a multithreaded program using the types of techniques shown in this chapter.
One trend that has been predicted for some time is that we will begin to see multiple cache-coherent CPUs on a single chip once the ability to increase the clock rate on a single chip slows down. Imagine that your new $2000 workstation has four 1-GHz processors on a single chip. Sounds like a good time to learn how to write multithreaded programs!
Exercises
Exercise \(\PageIndex{1}\)
Experiment with the fork code in this chapter. Run the program multiple times and see how the order of the messages changes. Explain the results.
Exercise \(\PageIndex{2}\)
Experiment with the create1 and create3 codes in this chapter. Remove all of the sleep( ) calls. Execute the programs several times on single and multiprocessor systems. Can you explain why the output changes from run to run in some situations and doesn’t change in others?
Exercise \(\PageIndex{3}\)
Experiment with the parallel sum code in this chapter. In the SumFunc( ) routine, change the for-loop to:
for(i=start;i<end;i++ ) GlobSum = GlobSum + array[i];
Remove the three lines at the end that get the mutex and update the GlobSum. Execute the code. Explain the difference in values that you see for GlobSum. Are the patterns different on a single processor and a multiprocessor? Explain the performance impact on a single processor and a multiprocessor.
Exercise \(\PageIndex{4}\)
Explain how the following code segment could cause deadlock — two or more processes waiting for a resource that can’t be relinquished:
...
call lock (lword1)
call lock (lword2)
...
call unlock (lword1)
call unlock (lword2)
.
.
.
call lock (lword2)
call lock (lword1)
...
call unlock (lword2)
call unlock (lword1)
...
Exercise \(\PageIndex{5}\)
If you were to code the functionality of a spin-lock in C, it might look like this:
while (!lockword);
lockword = !lockword;
As you know from the first sections of the book, the same statements would be compiled into explicit loads and stores, a comparison, and a branch. There’s a danger that two processes could each load lockword, find it unset, and continue on as if they owned the lock (we have a race condition). This suggests that spin-locks are implemented differently — that they’re not merely the two lines of C above. How do you suppose they are implemented?
Footnotes
- ANSYS is a commonly used structural-analysis package.
- These examples are written in C using the POSIX 1003.1 application programming interface. This example runs on most UNIX systems and on other POSIX-compliant systems including OpenNT, Open- VMS, and many others.
- It’s not uncommon for a human parent process to “fork” and create a human child process that initially seems to have the same identity as the parent. It’s also not uncommon for the child process to change its overall identity to be something very different from the parent at some later point. Usually human children wait 13 years or so before this change occurs, but in UNIX, this happens in a few microseconds. So, in some ways, in UNIX, there are many parent processes that are “disappointed” because their children did not turn out like them!
- This example uses the IEEE POSIX standard interface for a thread library. If your system supports POSIX threads, this example should work. If not, there should be similar routines on your system for each of the thread functions.
- The pthreads library supports both user-space threads and operating-system threads, as we shall soon see. Another popular early threads package was called cthreads.
- Because we know it will hang and ignore interrupts.
- Some thread libraries support a call to a routine sched_yield( ) that checks for runnable threads. If it finds a runnable thread, it runs the thread. If no thread is runnable, it returns immediately to the calling thread. This routine allows a thread that has the CPU to ensure that other threads make progress during CPU-intensive periods of its code.
- Boy, this is getting pretty picky. How often will either of these events really happen? Well, if it crashes your airline reservation system every 100,000 transactions or so, that would be way too often.
- It is important to match the number of runnable threads to the available resources. In compute code, when there are more threads than available processors, the threads compete among themselves, causing unnecessary overhead and reducing the efficiency of your computation.