
4.1: Data and Databases
- Page ID
- 84120

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Learning Objectives
Upon successful completion of this chapter, you will be able to:
- describe the differences between data, information, and knowledge;
- define the term database and identify the steps to creating one;
- describe the role of a database management system;
- describe the characteristics of a data warehouse; and
- define data mining and describe its role in an organization.
Introduction
You have already been introduced to the first two components of information systems: hardware and software. However, those two components by themselves do not make a computer useful. Imagine if you turned on a computer, started the word processor, but could not save a document. Imagine if you opened a music player but there was no music to play. Imagine opening a web browser but there were no web pages. Without data, hardware and software are not very useful! Data is the third component of an information system.
Data, Information, and Knowledge
There have been many definitions and theories about data, information, and knowledge. The three terms are often used interchangeably, although they are distinct in nature. We define and illustrate the three terms from the perspective of information systems.
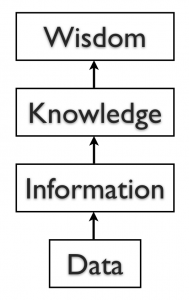
Data are the raw facts, and may be devoid of context or intent. For example, a sales order of computers is a piece of data. Data can be quantitative or qualitative. Quantitative data is numeric, the result of a measurement, count, or some other mathematical calculation. Qualitative data is descriptive. “Ruby Red,” the color of a 2013 Ford Focus, is an example of qualitative data. A number can be qualitative too: if I tell you my favorite number is 5, that is qualitative data because it is descriptive, not the result of a measurement or mathematical calculation.
Information is processed data that possess context, relevance, and purpose. For example, monthly sales calculated from the collected daily sales data for the past year are information. Information typically involves the manipulation of raw data to obtain an indication of magnitude, trends, in patterns in the data for a purpose.
Knowledge in a certain area is human beliefs or perceptions about relationships among facts or concepts relevant to that area. For example, the conceived relationship between the quality of goods and the sales is knowledge. Knowledge can be viewed as information that facilitates action.
Once we have put our data into context, aggregated and analyzed it, we can use it to make decisions for our organization. We can say that this consumption of information produces knowledge. This knowledge can be used to make decisions, set policies, and even spark innovation.
Explicit knowledge typically refers to knowledge that can be expressed into words or numbers. In contrast, tacit knowledge includes insights and intuitions, and is difficult to transfer to another person by means of simple communications.
Evidently, when information or explicit knowledge is captured and stored in computer, it would become data if the context or intent is devoid.
The final step up the information ladder is the step from knowledge (knowing a lot about a topic) to wisdom. We can say that someone has wisdom when they can combine their knowledge and experience to produce a deeper understanding of a topic. It often takes many years to develop wisdom on a particular topic, and requires patience.
Databases
The goal of many information systems is to transform data into information in order to generate knowledge that can be used for decision making. In order to do this, the system must be able to take data, allow the user to put the data into context, and provide tools for aggregation and analysis. A database is designed for just such a purpose.
Why Databases?
Data is a valuable resource in the organization. However, many people do not know much about database technology, but use non-database tools, such as Excel spreadsheet or Word document, to store and manipulate business data, or use poorly designed databases for business processes. As a result, the data are redundant, inconsistent, inaccurate, and corrupted. For a small data set, the use of non-database tools such as spreadsheet may not cause serious problem. However, for a large organization, corrupted data could lead to serious errors and destructive consequences. The common defects in data resources management are explained as follows.
- No control of redundant data
People often keep redundant data for convenience. Redundant data could make the data set inconsistent. We use an illustrative example to explain why redundant data are harmful. Suppose the registrar’s office has two separate files that store student data: one is the registered student roster which records all students who have registered and paid the tuition, and the other is student grade roster which records all students who have received grades.
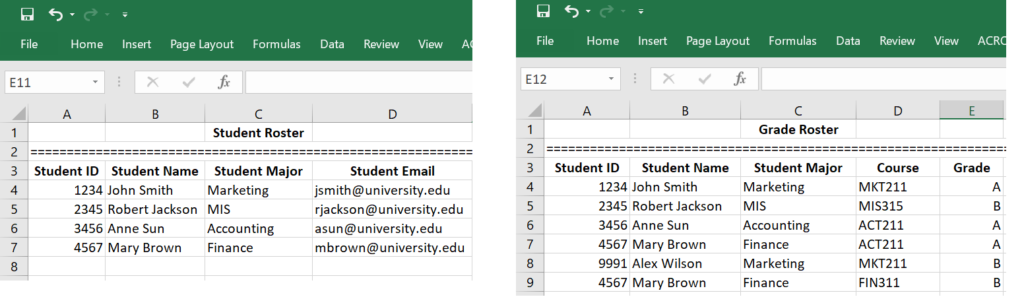
As you can see from the two spreadsheets, this data management system has problems. The fact that “Student 4567 is Mary Brown, and her major is Finance” is stored more than once. Such occurrences are called data redundancy. Redundant data often make data access convenient, but can be harmful. For example, if Mary Brown changes her name or her major, then all her names and major stored in the system must be changed altogether. For small data systems, such a problem looks trivial. However, when the data system is huge, making changes to all redundant data is difficult if not impossible. As a result of data redundancy, the entire data set can be corrupted.
- Violation of data integrity
Data integrity means consistency among the stored data. We use the above illustrative example to explain the concept of data integrity and how data integrity can be violated if the data system is flawed. You can find that Alex Wilson received a grade in MKT211; however, you can’t find Alex Wilson in the student roster. That is, the two rosters are not consistent. Suppose we have a data integrity control to enforce the rules, say, “no student can receive a grade unless she/he has registered and paid tuition”, then such a violation of data integrity can never happen.
- Relying on human memory to store and to search needed data
The third common mistake in data resource management is the over use of human memory for data search. A human can remember what data are stored and where the data are stored, but can also make mistakes. If a piece of data is stored in an un-remembered place, it has actually been lost. As a result of relying on human memory to store and to search needed data, the entire data set eventually becomes disorganized.
To avoid the above common flaws in data resource management, database technology must be applied. A database is an organized collection of related data. It is an organized collection, because in a database, all data is described and associated with other data. For the purposes of this text, we will only consider computerized databases.
Though not good for replacing databases, spreadsheets can be ideal tools for analyzing the data stored in a database. A spreadsheet package can be connected to a specific table or query in a database and used to create charts or perform analysis on that data.