
8.3: Elements of a process
- Page ID
- 82871

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Elements of a process

Process ID
The process ID (or the PID) is assigned by the operating system and is unique to each running process.
Memory
We will learn exactly how a process gets its memory in the following weeks -- it is one of the most fundamental parts of how the operating system works. However, for now it is sufficient to know that each process gets its own section of memory.
In this memory all the program code is stored, along with variables and any other allocated storage.
Parts of the memory can be shared between processes (called, not surprisingly shared memory). You will often see this called System Five Shared Memory (or SysV SHM) after the original implementation in an older operating system.
Another important concept a process may utilise is that of
mmaping a file on disk to memory. This
means that instead of having to open the file and use commands
such as read() and
write() the file looks as if it
were any other type of
RAM. mmaped areas have
permissions such as read, write and execute which need to be
kept track of. As we know, it is the job of the operating
system to maintain security and stability, so it needs to check
if a process tries to write to a read only area and return an
error.
Code and Data
A process can be further divided into
code and
data sections. Program code
and data should be kept separately since they require
different permissions from the operating system and separation
facilitates sharing of code (as you see later). The operating
system needs to give program code permission to be read and
executed, but generally not written to. On the other hand
data (variables) require read and write permissions but should
not be executable[12].
The Stack
One other very important part of a process is an area of memory called the stack. This can be considered part of the data section of a process, and is intimately involved in the execution of any program.
A stack is generic data structure that works exactly like a stack of plates; you can push an item (put a plate on top of a stack of plates), which then becomes the top item, or you can pop an item (take a plate off, exposing the previous plate).
Stacks are fundamental to function calls. Each time a
function is called it gets a new stack
frame. This is an area of memory which
usually contains, at a minimum, the address to return to when
complete, the input arguments to the function and space for
local variables.
By convention, stacks usually grow down[13] . This means that the stack starts at a high address in memory and progressively gets lower.
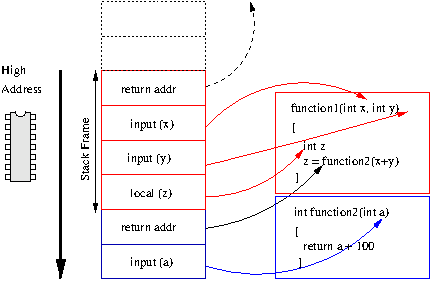
We can see how having a stack brings about many of the features of functions.
Each function has its own copy of its input arguments. This is because each function is allocated a new stack frame with its arguments in a fresh area of memory.
This is the reason why a variable defined inside a function can not be seen by other functions. Global variables (which can be seen by any function) are kept in a separate area of data memory.
This facilitates recursive calls. This means a function is free to call itself again, because a new stack frame will be created for all its local variables.
Each frame contains the address to return to. C only allows a single value to be returned from a function, so by convention this value is returned to the calling function in a specified register, rather than on the stack.
Because each frame has a reference to the one before it, a debugger can "walk" backwards, following the pointers up the stack. From this it can produce a stack trace which shows you all functions that were called leading into this function. This is extremely useful for debugging.
You can see how the way functions works fits exactly into the nature of a stack. Any function can call any other function, which then becomes the up most function (put on top of the stack). Eventually that function will return to the function that called it (takes itself off the stack).
Stacks do make calling functions slower, because values must be moved out of registers and into memory. Some architectures allow arguments to be passed in registers directly; however to keep the semantics that each function gets a unique copy of each argument the registers must rotate.
You may have heard of the term a stack overflow. This is a common way of hacking a system by passing bogus values. If you as a programmer accept arbitrary input into a stack variable (say, reading from the keyboard or over the network) you need to explicitly say how big that data is going to be.
Allowing any amount of data unchecked will simply overwrite memory. Generally this leads to a crash, but some people realised that if they overwrote just enough memory to place a specific value in the return address part of the stack frame, when the function completed rather than returning to the correct place (where it was called from) they could make it return into the data they just sent. If that data contains binary executable code that hacks the system (e.g. starts a terminal for the user with root privileges) then your computer has been compromised.
This happens because the stack grows downwards, but data is read in "upwards" (i.e. from lower address to higher addresses).
There are several ways around this; firstly as a programmer you must ensure that you always check the amount of data you are receiving into a variable. The operating system can help to avoid this on behalf of the programmer by ensuring that the stack is marked as not executable; that is that the processor will not run any code, even if a malicious user tries to pass some into your program. Modern architectures and operating systems support this functionality.
Stacks are ultimately managed by the compiler, as it is responsible for generating the program code. To the operating system the stack just looks like any other area of memory for the process.
To keep track of the current growth of the stack, the hardware defines a register as the stack pointer. The compiler (or the programmer, when writing in assembler) uses this register to keep track of the current top of the stack.
1 $ cat sp.c
void function(void)
{
int i = 100;
5 int j = 200;
int k = 300;
}
$ gcc -fomit-frame-pointer -S sp.c
10
$ cat sp.s
.file "sp.c"
.text
.globl function
15 .type function, @function
function:
subl $16, %esp
movl $100, 4(%esp)
movl $200, 8(%esp)
20 movl $300, 12(%esp)
addl $16, %esp
ret
.size function, .-function
.ident "GCC: (GNU) 4.0.2 20050806 (prerelease) (Debian 4.0.1-4)"
25 .section .note.GNU-stack,"",@progbits
Above we show a simple function allocating three
variables on the stack. The disassembly illustrates the use
of the stack pointer on the x86 architecture[14]. Firstly we allocate some
space on the stack for our local variables. Since the stack
grows down, we subtract from the value held in the stack
pointer. The value 16 is a value large enough to hold our
local variables, but may not be exactly the size required (for
example with 3 4 byte int
values we really only need 12 bytes, not 16) to keep alignment
of the stack in memory on certain boundaries as the compiler
requires.
Then we move the values into the stack memory (and in a real function, use them). Finally, before returning to our parent function we "pop" the values off the stack by moving the stack pointer back to where it was before we started.
The Heap
The heap is an area of memory that is managed by the process for on the fly memory allocation. This is for variables whose memory requirements are not known at compile time.
The bottom of the heap is known as the
brk, so called for the system call which
modifies it. By using the
brk call to grow the area
downwards the process can request the kernel allocate
more memory for it to use.
The heap is most commonly managed by the
malloc library call. This
makes managing the heap easy for the programmer by allowing
them to simply allocate and free (via the
free call) heap memory.
malloc can use schemes like a
buddy allocator to manage the heap memory
for the user. malloc can
also be smarter about allocation and potentially use
anonymous mmaps for extra process memory.
This is where instead of mmaping a file
into the process memory it directly maps an area of system
RAM. This can be more efficient. Due to the complexity of
managing memory correctly, it is very uncommon for any modern
program to have a reason to call
brk directly.
Memory Layout

As we have seen a process has smaller areas of memory allocated to it, each with a specific purpose.
An example of how the process is laid out in memory by the kernel is given above. Starting from the top, the kernel reserves itself some memory at the top of the process (we see with virtual memory how this memory is actually shared between all processes).
Underneath that is room for
mmaped files and libraries.
Underneath that is the stack, and below that the heap.
At the bottom is the program image, as loaded from the executable file on disk. We take a closer look at the process of loading this data in later chapters.
File Descriptors
In the first week we learnt about
stdin,
stdout and
stderr; the default files given
to each process. You will remember that these files always have
the same file descriptor number (0,1,2 respectively).
Thus, file descriptors are kept by the kernel individually for each process.
File descriptors also have permissions. For example, you may be able to read from a file but not write to it. When the file is opened, the operating system keeps a record of the processes permissions to that file in the file descriptor and doesn't allow the process to do anything it shouldn't.
Registers
We know from the previous chapter that the processor essentially performs generally simple operations on values in registers. These values are read (and written) to memory -- we mentioned above that each process is allocated memory which the kernel keeps track of.
So the other side of the equation is keeping track of the registers. When it comes time for the currently running process to give up the processor so another process can run, it needs to save its current state. Equally, we need to be able to restore this state when the process is given more time to run on the CPU. To do this the operating system needs to store a copy of the CPU registers to memory. When it is time for the process to run again, the operating system will copy the register values back from memory to the CPU registers and the process will be right back where it left off.
Kernel State
Internally, the kernel needs to keep track of a number of elements for each process.
Process State
Another important element for the operating system to keep track of is the process state. If the process is currently running it makes sense to have it in a running state.
However, if the process has requested to read a file from disk we know from our memory hierarchy that this may take a significant amount of time. The process should give up its current execution to allow another process to run, but the kernel need not let the process run again until the data from the disk is available in memory. Thus it can mark the process as disk wait (or similar) until the data is ready.
Priority
Some processes are more important than others, and get a higher priority. See the discussion on the scheduler below.
Statistics
The kernel can keep statistics on each processes behaviour which can help it make decisions about how the process behaves; for example does it mostly read from disk or does it mostly do CPU intensive operations?
[12] Not all architectures support this, however. This has lead to a wide range of security problems on many architectures.
[13] Some architectures, such as PA-RISC from HP, have stacks that grow upwards. On some other architectures, such as IA64, there are other storage areas (the register backing store) that grow from the bottom toward the stack.
[14] Note we used the special flag to gcc
-fomit-frame-pointer which
specifies that an extra register should
not be used to keep a pointer to the
start of the stack frame. Having this pointer helps debuggers
to walk upwards through the stack frames, however it makes one
less register available for other
applications.