
0.6: Notation in Pseudocode
- Page ID
- 85512

We’ll often describe algorithms/processes using pseudocode. In doing so, we will use several different operators whose meanings might be easily confused:
| \(\leftarrow\) |
When \(\mathcal{D}\) is a probability distribution, we write " \(x \leftarrow \mathcal{D}\) " to mean "sample \(x\) according to the distribution \(\mathcal{D}\)." If \(\mathcal{A}\) is an algorithm that takes input and also makes some internal random choices, then it is natural to think of its output \(\mathcal{A}(y)\) as a distribution - possibly a different distribution for each input \(y\). Then we write " \(x \leftarrow \mathcal{A}(y)\) " to mean the natural thing: "run \(\mathcal{A}\) on input \(y\) and assign the output to \(x\) " We overload the " \(\leftarrow\) " notation slightly, writing " \(x \leftarrow X\) " when \(X\) is a finite set to mean that \(x\) is sampled from the uniform distribution over \(X\). |
| \(:=\) | We write \(x:=y\) for assignments to variables: "take the value of expression \(y\) and assign it to variable \(x\)." |
| \(\stackrel{?}{=}\) |
We write comparisons as \(\stackrel{?}{=}\) (analogous to \("=="\) in your favorite programming language). So \(x \stackrel{?}{=} y\) doesn’t modify \(x\) (or \(y\) ), but rather it is an expression which returns true if \(x\) and \(y\) are equal. You will often see this notation in the conditional part of an if-statement, but also in return statements as well. The following two snippets are equivalent: 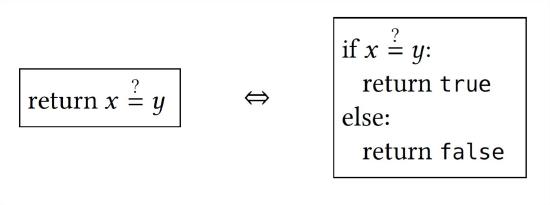 In a similar way, we write \(x \stackrel{?}{\in} S\) as an expression that evaluates to true if \(x\) is in the \(\operatorname{set} S\) |
Subroutine conventions
We’ll use mathematical notation to define the types of subroutine arguments:

\({ }^{3}\) There is something called Kolmogorov complexity that can actually give coherent meaning to statements like " \(x\) is a random string." But Kolmogorov complexity has no relevance to this book. The statement " \(x\) is a random string" remains meaningless with respect to the usual probability-distribution sense of the word "random."