
2.5: How to Compare/Contrast Security Definitions
- Page ID
- 7324

In math, a definition can’t really be "wrong" but it can be "not as useful as you hoped" or it can "fail to adequately capture your intuition" about the concept.
Security definitions are no different. In this chapter we introduced two security definitions: one in the "real-vs-random" style and one in the "left-vs-right" style. In this section we treat the security definitions themselves as objects worth studying. Are both of these security definitions "the same", in some sense? Do they both capture all of our intuitions about security?
One Security Definition Implies Another
One way to compare/contrast two security definitions is to prove that one implies the other. In other words, if an encryption scheme satisfies definition #1, then it also satisfies definition #2.
If an encryption scheme \(\sum\) has one-time uniform ciphertexts (Definition 2.5), then \(\sum\) also has one-time secrecy (Definition 2.6). In other words: \[\mathcal{L}_{\text {ots\$-real }}^{\Sigma} \equiv \mathcal{L}_{\text {ots\$-rand }}^{\Sigma} \Longrightarrow \mathcal{L}_{\text {ots-L }}^{\Sigma} \equiv \mathcal{L}_{\text {ots-R }}^{\Sigma}\]
If you are comfortable with what all the terminology means, then the meaning of this statement is quite simple and unsurprising. "If all plaintexts \(m\) induce a uniform distribution of ciphertexts, then all \(m\) induce the same distribution of ciphertexts."
This fairly straight-forward statement can be proven formally, giving us another example of the hybrid proof technique:
Proof
We are proving an if-then statement. We want to show that the "then"-part of the statement is true; that is, \(\mathcal{L}_{\text {ots-L }}^{\Sigma} \equiv \mathcal{L}_{\text {ots-R" }}^{\Sigma}\).We are allowed to use the fact that the "if"-part is true; that is, \(\mathcal{L}_{\text {ots\$-real }}^{\Sigma} \equiv \mathcal{L}_{\text {ots\$-rand }}^{\Sigma}\)
The proof uses the hybrid technique. We will start with the library \(\mathcal{L}_{\text {ots-L, }}\) and make a small sequence of justifiable changes to it, until finally reaching \(\mathcal{L}_{\text {ots-R. Along the way, we }}\) can use the fact that \(\mathcal{L}_{\text {ots\$-real }} \equiv \mathcal{L}_{\text {ots\$-rand. This suggests some "strategy" for the proof: if }}\) we can somehow get \(\mathcal{L}_{\text {ots\$-real }}\) to appear as a component in one of the hybrid libraries, then we can replace it with \(\mathcal{L}_{\text {ots\$-rand }}\) (or vice-versa), in a way that hopefully makes progress towards our goal of transforming \(\mathcal{L}_{\text {ots-L }}\) to \(\mathcal{L}_{\text {ots-R. }}\)
Below we list the sequence of hybrid libraries, and justify why each one is interchangeable with the previous library.
 |
The starting point of our hybrid sequence is \(\mathcal{L}_{\text {ots-L }}^{\Sigma}\) |
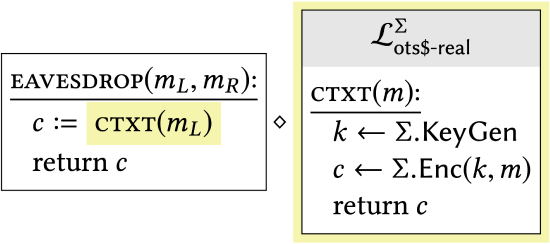 |
Factoring out a block of statements into a subroutine makes it possible to write the library as a compound one, but does not affect its external behavior. Note that the new subroutine is exactly the \(\mathcal{L}_{\text {ots\$-real }}^{\Sigma}\) library from Definition 2.5. This was a strategic choice, because of what happens next. |
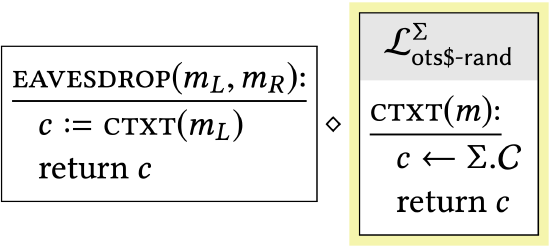 |
\(\mathcal{L}_{\text {ots\$-real }}^{\Sigma}\) has been replaced with \(\mathcal{L}_{\text {ots\$-rand }}\) Lemma \(2.11\) says that this change has no effect on the library’s behavior, since the two \(\mathcal{L}_{\text {ots\$- } \star}\) libraries are interchangeable. |
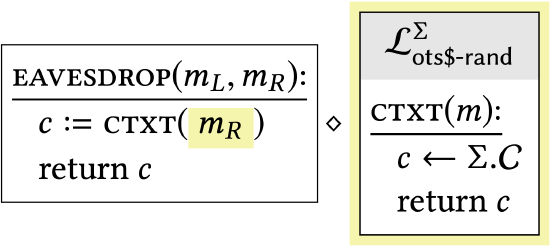 |
The argument to стхт has been changed from \(m_{L}\) to \(m_{R}\). This has no effect on the library’s behavior since стхт does not actually use its argument in these hybrids! |
The previous transition is the most important one in the proof, as it gives insight into how we came up with this particular sequence of hybrids. Looking at the desired endpoints of our sequence of hybrids \(-\mathcal{L}_{\text {ots-L }}^{\Sigma}\) and \(\mathcal{L}_{\text {ots-R }}^{\Sigma}-\) we see that they differ only in swapping \(m_{L}\) for \(m_{R}\). If we are not comfortable eyeballing things, we’d like a better justification for why it is "safe" to exchange \(m_{L}\) for \(m_{R}\) (i.e., why it has no effect on the calling program). However, the uniform ciphertexts property shows that \(\mathcal{L}_{\text {ots-L }}^{\Sigma}\) in fact has the same behavior as a library \(\mathcal{L}_{\text {hyb-2 }}\) that doesn’t use either of \(m_{L}\) or \(m_{R}\). In a program that doesn’t use \(m_{L}\) or \(m_{R}\), it is clear that we can switch them!
Having made this crucial change, we can now perform the same sequence of steps, but in reverse.
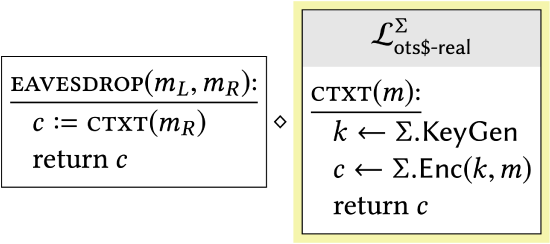 |
\(\mathcal{L}_{\text {ots\$-rand }}^{\Sigma}\) has been replaced with \(\mathcal{L}_{\text {ots\$-real }}^{\Sigma} .\) This is another application of the chaining lemma. |
 |
A subroutine call has been inlined, which has no effect on the library’s behavior. The result is exactly \(\mathcal{L}_{\text {ots-R }}^{\Sigma}\) |
Putting everything together, we showed that \(\mathcal{L}_{\text {ots- }}^{\Sigma} \equiv \mathcal{L}_{\text {hyb-1 }} \equiv \cdots \equiv \mathcal{L}_{\text {hyb-4 }} \equiv \mathcal{L}_{\text {ots-R }}\). This completes the proof, and we conclude that \(\sum\) satisfies the definition of one-time secrecy.
One Security Definition Doesn’t Imply Another
Another way we might compare security definitions is to identify any schemes that satisfy one definition without satisfying the other. This helps us understand the boundaries and "edge cases" of the definition.
A word of warning: If we have two security definitions that both capture our intuitions rather well, then any scheme which satisfies one definition and not the other is bound to appear unnatural and contrived. The point is to gain more understanding of the security definitions themselves, and unnatural/contrived schemes are just a means to do that.
There is an encryption scheme that satisfies one-time secrecy (Definition 2.6) but not one-time uniform ciphertexts (Definition 2.5). In other words, one-time secrecy does not necessarily imply one-time uniform ciphertexts.
Proof
One such encryption scheme is given below:
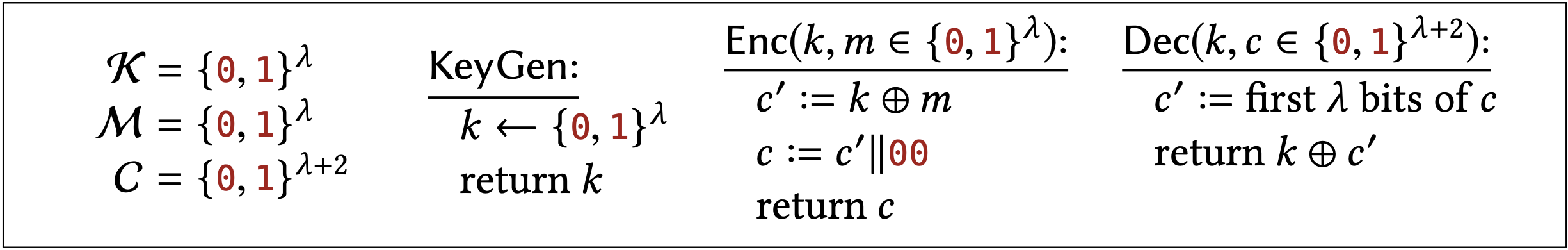
This scheme is just OTP with the bits 00 added to every ciphertext. The following facts about the scheme should be believable (and the exercises encourage you to prove them formally if you would like more practice at that sort of thing):
- This scheme satisfies one-time one-time secrecy, meaning that encryptions of \(m_{L}\) are distributed identically to encryptions of \(m_{R}\), for any \(m_{L}\) and \(m_{R}\) of the attacker’s choice. We can characterize the ciphertext distribution in both cases as " \(\lambda\) uniform bits followed by 00 ." Think about how you might use the hybrid proof technique to formally prove that this scheme satisfies one-time secrecy!
- This scheme does not satisfy the one-time uniform ciphertexts property. Its ciphertexts always end with 00 , whereas uniform strings end with 00 with probability 1/4. Think about how you might formallize this observation as a calling program / distinguisher for the relevant two libraries!
You might be thinking, surely this can be fixed by redefining the ciphertext space as \(C\) as the set of \(\lambda+2\)-bit strings whose last two bits are 00 . This is a clever idea, and indeed it would work. If we change the definition of the ciphertext space \(C\) following this suggestion, then the scheme would satisfy the uniform ciphertexts property (this is because the \(\mathcal{L}_{\text {ots\$-rand }}\) library samples uniformly from whatever \(C\) is specified as part of the encryption scheme).
But this observation raises an interesting point. Isn’t it weird that security hinges on how narrowly you define the set \(C\) of ciphertexts, when \(C\) really has no effect on the functionality of encryption? Again, no one really cares about this contrived "OTP + 00 " encryption scheme. The point is to illuminate interesting edge cases in the security definition itself!