
10.2: MeldableHeap - A Randomized Meldable Heap
- Page ID
- 8478

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)In this section, we describe the MeldableHeap, a priority Queue implementation in which the underlying structure is also a heap-ordered binary tree. However, unlike a BinaryHeap in which the underlying binary tree is completely defined by the number of elements, there are no restrictions on the shape of the binary tree that underlies a MeldableHeap; anything goes.
The \(\mathtt{add(x)}\) and \(\mathtt{remove()}\) operations in a MeldableHeap are implemented in terms of the \(\mathtt{merge(h1,h2)}\) operation. This operation takes two heap nodes \(\mathtt{h1}\) and \(\mathtt{h2}\) and merges them, returning a heap node that is the root of a heap that contains all elements in the subtree rooted at \(\mathtt{h1}\) and all elements in the subtree rooted at \(\mathtt{h2}\).
The nice thing about a \(\mathtt{merge(h1,h2)}\) operation is that it can be defined recursively. See Figure \(\PageIndex{1}\). If either \(\mathtt{h1}\) or \(\mathtt{h2}\) is \(\mathtt{nil}\), then we are merging with an empty set, so we return \(\mathtt{h2}\) or \(\mathtt{h1}\), respectively. Otherwise, assume \(\texttt{h1.x} \le \texttt{h2.x}\) since, if \(\texttt{h1.x} > \texttt{h2.x}\), then we can reverse the roles of \(\mathtt{h1}\) and \(\mathtt{h2}\). Then we know that the root of the merged heap will contain \(\texttt{h1.x}\), and we can recursively merge \(\mathtt{h2}\) with \(\texttt{h1.left}\) or \(\texttt{h1.right}\), as we wish. This is where randomization comes in, and we toss a coin to decide whether to merge \(\mathtt{h2}\) with \(\texttt{h1.left}\) or \(\texttt{h1.right}\):
Node<T> merge(Node<T> h1, Node<T> h2) {
if (h1 == nil) return h2;
if (h2 == nil) return h1;
if (compare(h2.x, h1.x) < 0) return merge(h2, h1);
// now we know h1.x <= h2.x
if (rand.nextBoolean()) {
h1.left = merge(h1.left, h2);
h1.left.parent = h1;
} else {
h1.right = merge(h1.right, h2);
h1.right.parent = h1;
}
return h1;
}
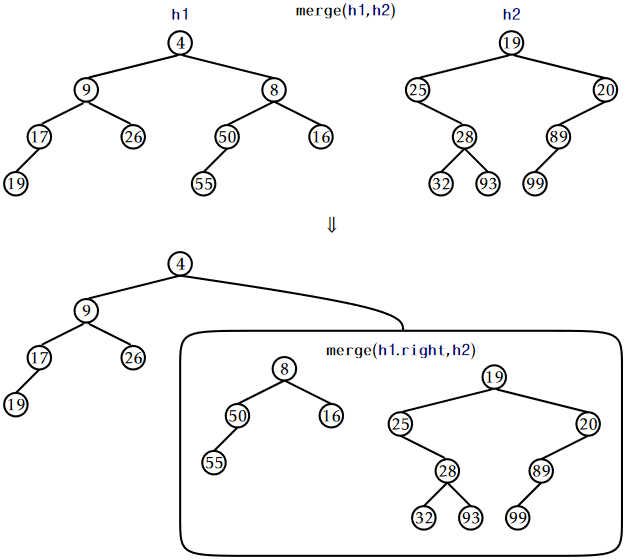
In the next section, we show that \(\mathtt{merge(h1,h2)}\) runs in \(O(\log \mathtt{n})\) expected time, where \(\mathtt{n}\) is the total number of elements in \(\mathtt{h1}\) and \(\mathtt{h2}\).
With access to a \(\mathtt{merge(h1,h2)}\) operation, the \(\mathtt{add(x)}\) operation is easy. We create a new node \(\mathtt{u}\) containing \(\mathtt{x}\) and then merge \(\mathtt{u}\) with the root of our heap:
boolean add(T x) {
Node<T> u = newNode();
u.x = x;
r = merge(u, r);
r.parent = nil;
n++;
return true;
}
This takes \(O(\log (\mathtt{n}+1)) = O(\log \mathtt{n})\) expected time.
The \(\mathtt{remove()}\) operation is similarly easy. The node we want to remove is the root, so we just merge its two children and make the result the root:
T remove() {
T x = r.x;
r = merge(r.left, r.right);
if (r != nil) r.parent = nil;
n--;
return x;
}
Again, this takes \(O(\log \mathtt{n})\) expected time.
Additionally, a MeldableHeap can implement many other operations in \(O(\log \mathtt{n})\) expected time, including:
- \(\mathtt{remove(u)}\): remove the node \(\mathtt{u}\) (and its key \(\texttt{u.x}\)) from the heap.
- \(\mathtt{absorb(h)}\): add all the elements of the MeldableHeap \(\mathtt{h}\) to this heap, emptying \(\mathtt{h}\) in the process.
Each of these operations can be implemented using a constant number of \(\mathtt{merge(h1,h2)}\) operations that each take \(O(\log \mathtt{n})\) expected time.
\(\PageIndex{1}\) Analysis of \(\mathtt{merge(h1,h2)}\)
The analysis of \(\mathtt{merge(h1,h2)}\) is based on the analysis of a random walk in a binary tree. A random walk in a binary tree starts at the root of the tree. At each step in the random walk, a coin is tossed and, depending on the result of this coin toss, the walk proceeds to the left or to the right child of the current node. The walk ends when it falls off the tree (the current node becomes \(\mathtt{nil}\)).
The following lemma is somewhat remarkable because it does not depend at all on the shape of the binary tree:
The expected length of a random walk in a binary tree with \(\mathtt{n}\) nodes is at most \(\mathtt{\log (n+1)}\).
Proof. The proof is by induction on \(\mathtt{n}\). In the base case, \(\mathtt{n}=0\) and the walk has length \(0=\log (\mathtt{n}+1)\). Suppose now that the result is true for all non-negative integers \(\mathtt{n}'< \mathtt{n}\).
Let \(\mathtt{n}_1\) denote the size of the root's left subtree, so that \(\mathtt{n}_2=\mathtt{n}-\mathtt{n}_1-1\) is the size of the root's right subtree. Starting at the root, the walk takes one step and then continues in a subtree of size \(\mathtt{n}_1\) or \(\mathtt{n}_2\). By our inductive hypothesis, the expected length of the walk is then
\[ \mathrm{E}[W] = 1 + \frac{1}{2}\log (\mathtt{n}_1+1) + \frac{1}{2}\log (\mathtt{n}_2+1) \enspace , \nonumber\]
since each of \(\mathtt{n}_1\) and \(\mathtt{n}_2\) are less than \(\mathtt{n}\). Since \(\log\) is a concave function, \(\mathrm{E}[W]\) is maximized when \(\mathtt{n}_1=\mathtt{n}_2=(\mathtt{n}-1)/2\). Therefore, the expected number of steps taken by the random walk is
\[\begin{align}
\mathrm{E}[W]
&= 1 + \frac{1}{2}\log (\mathtt{n}_1+1) + \frac{1}{2}\log (\mathtt{n}_2+1)\nonumber\\
&\le 1 + \log ((\mathtt{n}-1)/2+1)\nonumber\\
&= 1 + \log ((\mathtt{n}+1)/2)\nonumber\\
&= \log (\mathtt{n}+1) \enspace .\nonumber
\end{align}\nonumber\]
We make a quick digression to note that, for readers who know a little about information theory, the proof of Lemma \(\PageIndex{1}\) can be stated in terms of entropy.
Information Theoretic Proof of Lemma \(\PageIndex{1}\)
Let \(d_i\) denote the depth of the \(i\)th external node and recall that a binary tree with \(\mathtt{n}\) nodes has \(\mathtt{n+1}\) external nodes. The probability of the random walk reaching the \(i\)th external node is exactly \(p_i=1/2^{d_i}\), so the expected length of the random walk is given by
\[ H=\sum_{i=0}^{\mathtt{n}} p_id_i =\sum_{i=0}^\mathtt{n} p_{i} \log \left(2^{d_i}\right) = \sum_{i=0}^{\mathtt{n}}p_i\log({1/p_i}) \nonumber\]
The right hand side of this equation is easily recognizable as the entropy of a probability distribution over \(\mathtt{n}+1\) elements. A basic fact about the entropy of a distribution over \(\mathtt{n}+1\) elements is that it does not exceed \(\log(\mathtt{n}+1)\), which proves the lemma. ![]()
With this result on random walks, we can now easily prove that the running time of the \(\mathtt{merge(h1,h2)}\) operation is \(O(\log \mathtt{n})\).
Lemma \(\PageIndex{2}\).
If \(\mathtt{h1}\) and \(\mathtt{h2}\) are the roots of two heaps containing \(\mathtt{n}_1\) and \(\mathtt{n}_2\) nodes, respectively, then the expected running time of \(\mathtt{merge(h1,h2)}\) is at most \(O(\log \mathtt{n})\), where \(\mathtt{n}=\mathtt{n}_1+\mathtt{n}_2\).
Proof. Each step of the merge algorithm takes one step of a random walk, either in the heap rooted at \(\mathtt{h1}\) or the heap rooted at \(\mathtt{h2}\). The algorithm terminates when either of these two random walks fall out of its corresponding tree (when \(\mathtt{h1}=\mathtt{null}\) or \(\mathtt{h2}=\mathtt{null}\)). Therefore, the expected number of steps performed by the merge algorithm is at most
\[ \log (\mathtt{n}_1+1) + \log (\mathtt{n}_2+1) \le 2\log \mathtt{n} \enspace . \nonumber\]
\(\PageIndex{2}\) Summary
The following theorem summarizes the performance of a MeldableHeap: