
7.3: Define first (1NF), second (2NF), and third normal (3NF) form
- Page ID
- 93673
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Normalization is a technique in database design used to organize tables in a way that reduces redundancy and dependency of data. The use of this technique splits first into a larger table then into smaller tables, and links all by using entity relationships. The designer of the relational model, Edgar Codd, came up with this theory of normalization that introduces the First Normal (1NF) form and then continues to extend the theory into a second (2NF) and third normal form (3NF). The main idea with this theory is that a table is about a specific topic and only supporting topics are included, which minimizes duplicate data, avoids data modification issues, and simplifies queries.
The first normal form (1NF), like all normal forms, has specific requirements to be validated as 1NF. A table, as below, must be two dimensional with rows and columns, and each row must contain data that relates to something. Each column must contain data for a single attribute of the thing it’s describing, each cell of the table must have only a single value, entries in any column must have the same type of data (Ex. If the entry in one row of a column contains hair color, all the other rows must contain hair color as well), each column must have a unique name, all rows should be uniquely identified (has to have some unique ID), and the order of the columns and rows must have no significance. Tables in first normal form are subject to deletion and insertion anomalies; they may prove useful in some applications but can be unreliable in others.
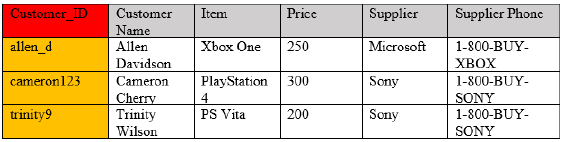
Second normal form (2NF) must have all attributes or non-key columns dependent on the key. For example, if the data is based on making an order as shown in Figure 1, the price of the item isn’t determined by the primary key or unique identifier of the customer, so this would break the second normal form. In this case, the table can be split into two, with one table having the primary key as Customer_ID and all of their personal information and the second being a table with the primary key as the item name and the supplier information and prices. All of this information in each table is now correctly dependent on the primary key.
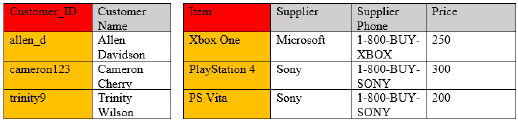
Since the second normal form has two separate tables, a junction table is necessary where both keys are represented in the same table to show who bought what. This can also be used as a compound key where two primary keys are conjoined to represent each other.

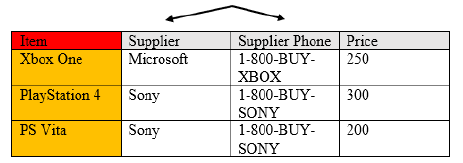
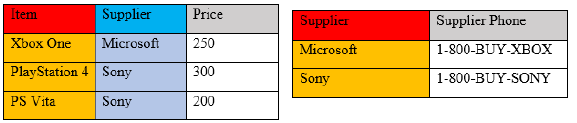
In the third normal form (3NF), all columns can be determined only by the key in the table and no other column. Having this type of normalization gets rid of redundancy and is especially vulnerable to some types of modification anomalies. Take a look at Figure \(\PageIndex{2}\) where the items table has duplicate supplier phone numbers and supplier names. If Sony were to have more products under their item key, the supplier phone number would keep repeating because it’s directly related to the supplier name and will always be that same phone number.
Separating these two tables into individual representations makes all of the columns dependent on only the key in the table and no other column, making the third normal form valid.
- Some researchers discovered that anomalies could occur, and the conditions for Boyce-Codd Normal Form (BCNF) were identified. These normal forms are well-defined so the relation in BCNF is in 3NF, a relation in 3NF is in 2NF, and a relation in 2NF is in 1NF can occur.
- Therefore, the normal forms 2NF through BCNF concern anomalies that happen from functional dependencies. They led to the definition of fourth normal form (4NF) and fifth normal form (5NF).
- Table \(\PageIndex{1}\) shows other anomalies which occurred because of another kind of dependency called a multivalued dependency. Those anomalies could be eliminated by placing each multivalued dependency in a relation of its own, a condition known as 4NF.
|
Anomaly |
Norma Forms |
Design Principles |
|---|---|---|
|
Functional Dependencies |
1NF, 2NF, 3NF, BCNF |
BCNF: Design tables so that every determinant is a candidate key. |
|
Multivalued Dependencies |
4NF |
4NF: Move each multivalued dependency to a table of its own. |
|
Data Constrained |
5NF, DK/NF |
DK/NF: Make every constraint a logical consequence of candidate keys and domains. |
The fifth normal form (5NF), also known as Project-Join Normal Form (PJ/NF) can lead to an anomaly where a table can be split apart but not correctly joined back together. However, the conditions this condition is rather complex, and generally, if a relation is in 4NF it is in 5NF. For more information about 5NF, consult this Wikipedia article.