
10.4: Cumulative Sample Means
- Page ID
- 55674
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)In this subsection, we present a practical means of computing sample means. Let us denote the total number of coin flips by \(n_{\max }\), which defines the size of our sample. We assume \(n_{\exp }=1\), as is almost always the case in practice. We create our sample of size \(n_{\max }\), and then for \(n=1, \ldots, n_{\max }\) we compute a sequence of cumulative sample means. That is, we start with a realization of \(n_{\max }\) coin tosses, \[b_{1}, b_{2}, \ldots, b_{n}, \ldots, b_{n_{\max }}\]
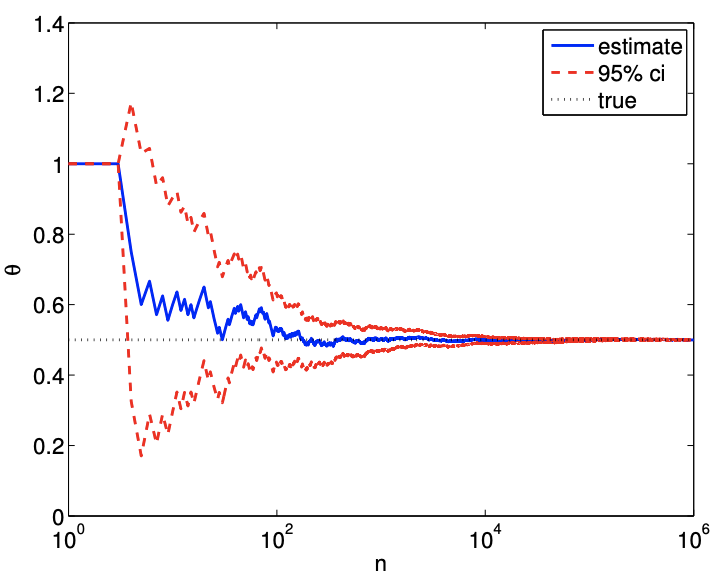
(a) value
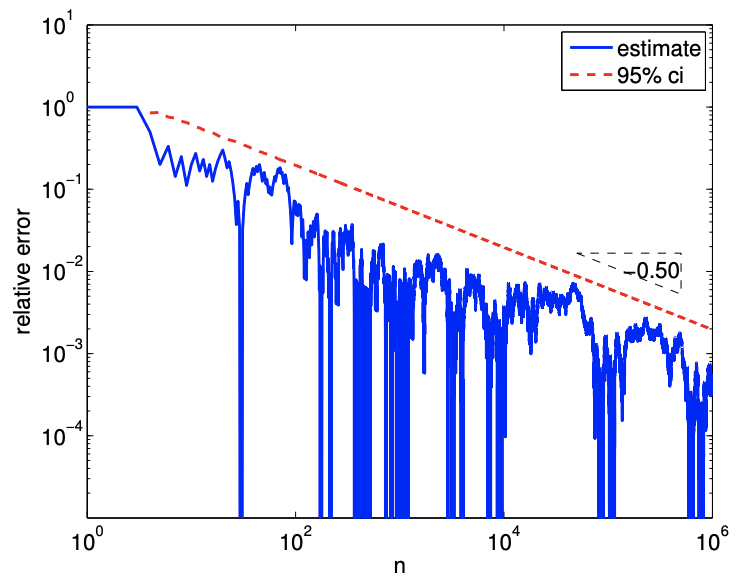
(b) relative error
Figure 10.4: Cumulative sample mean, confidence intervals, and their convergence for a Bernoulli random variable \((\theta=0.5)\).
and then compute the cumulative values,
Note that the random variables \(\bar{B}_{1}, \ldots, \bar{B}_{n_{\max }}\) realized by \(\bar{b}_{1}, \ldots, \bar{b}_{n_{\max }}\) are not independent because the sample means are computed from the same set of realizations; also, the random variable, \([\mathrm{CI}]_{n}\) realized by \([\mathrm{ci}]_{n}\) are not joint with confidence \(\gamma\). However in practice this is a computationally efficient way to estimate the parameter with typically only small loss in rigor. In particular, by plotting \(\hat{\theta}_{n}\) and \([\text { ci }]_{n}\) for \(n=1, \ldots, n_{\max }\), one can deduce the convergence behavior of the simulation. In effect, we only perform one experiment, but we interpret it as \(n_{\max }\) experiments.
Figure \(10.4\) shows an example of computing the sample means and confidence intervals in a cumulative manner. The figure confirms that the estimate converges to the true parameter value of \(\theta=0.5\). The confidence interval is a good indicator of the quality of the solution. The error (and the confidence interval) converges at the rate of \(n^{-1 / 2}\), which agrees with the theory. \[\begin{aligned} & \hat{\theta}_{1}=\bar{b}_{1}=\frac{1}{1} \cdot b_{1} \quad \text { and } \quad[\mathrm{ci}]_{1}=\left[\hat{\theta}_{1}-z_{\gamma} \sqrt{\frac{\hat{\theta}_{1}\left(1-\hat{\theta}_{1}\right)}{1}}, \hat{\theta}_{1}+z_{\gamma} \sqrt{\frac{\hat{\theta}_{1}\left(1-\hat{\theta}_{1}\right)}{1}}\right] \\ & \hat{\theta}_{2}=\bar{b}_{2}=\frac{1}{2}\left(b_{1}+b_{2}\right) \quad \text { and } \quad[\mathrm{ci}]_{2}=\left[\hat{\theta}_{2}-z_{\gamma} \sqrt{\frac{\hat{\theta}_{2}\left(1-\hat{\theta}_{2}\right)}{2}}, \hat{\theta}_{2}+z_{\gamma} \sqrt{\frac{\hat{\theta}_{2}\left(1-\hat{\theta}_{2}\right)}{2}}\right] \\ & \hat{\theta}_{n}=\bar{b}_{n}=\frac{1}{n} \sum_{i=1}^{n} b_{i} \quad \text { and } \quad[\mathrm{ci}]_{n}=\left[\hat{\theta}_{n}-z_{\gamma} \sqrt{\frac{\hat{\theta}_{n}\left(1-\hat{\theta}_{n}\right)}{n}}, \hat{\theta}_{n}+z_{\gamma} \sqrt{\frac{\hat{\theta}_{n}\left(1-\hat{\theta}_{n}\right)}{n}}\right] \\ & \hat{\theta}_{n_{\max }}=\bar{b}_{n_{\max }}=\frac{1}{n} \sum_{i=1}^{n_{\max }} b_{i} \quad \text { and } \quad[\mathrm{ci}]_{n_{\max }}=\left[\hat{\theta}_{n_{\max }}-z_{\gamma} \sqrt{\frac{\hat{\theta}_{n_{\max }}\left(1-\hat{\theta}_{n_{\max }}\right)}{n_{\max }}}, \hat{\theta}_{n_{\max }}+z_{\gamma} \sqrt{\frac{\hat{\theta}_{n_{\max }}\left(1-\hat{\theta}_{n_{\max }}\right)}{n_{\max }}}\right] \text {. } \end{aligned}\]