
7.6: Min-Max Optimization for Discrete Choices
- Page ID
- 47263

A common dilemma in optimization is the existence of multiple objective functions. For example, in buying a motor, we have power rating, weight, durability and so on to consider. Even if it were a custom job - in which case the variables can be continuously varied - the fact of many objectives makes it messy. Clean optimization problems minimize one function, but if we make a meta-function out of many simpler functions (e.g., a weighted sum), we invariably find that the solution is quite sensitive to how we constructed the meta-function. This is not as it should be! The figure below shows on the left a typical tradeoff of objectives - one is improved at the expense of another. Both are functions of the underlying parameters. Constructing a meta-objective on the right, there is a indeed a minimum (plotted against \(J_1(x)\), but its location depends directly on \(\gamma\).
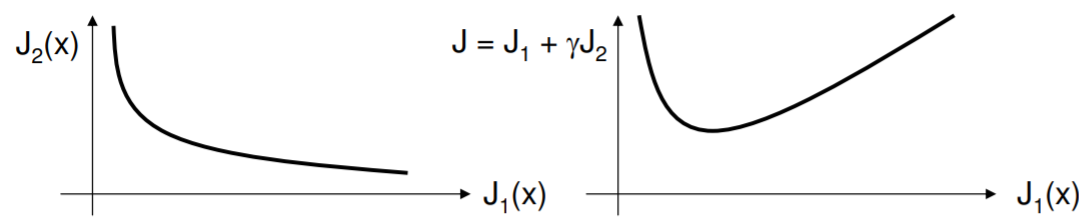.png?revision=1)
A very nice resolution to this problem is the min-max method. What we look for is the candidate solution with the smallest normalized deviation from the peak performance across objectives. Here is an example that explains. Four candidates are to be assessed according to three performance metrics; higher is better. They have raw scores as follows:
| Metric I | Metric II | Metric III | |
|---|---|---|---|
| Candidate A | \(3.5\) | \(9\) | \(80\) |
| Candidate B | \(2.6\) | \(10\) | \(90\) |
| Candidate C | \(4.0\) | \(8.5\) | \(65\) |
| Candidate D | \(3.2\) | \(7.5\) | \(86\) |
Note that each metric is evidently given on different scales. Metric I is perhaps taken out of five, Metric II is out of ten perhaps, and Metric III could be out of one hundred. We make four basic calculations:
- Calculate the range (max minus the min) for each metric: we get \([1.4, 2.5, 35]\).
- Pick out the maximum metric in each metric: we have \([4.0, 10, 90]\).
- Finally, replace the entries in the original table with the normalized deviation from the best
| Metric I | Metric II | Metric III | |
|---|---|---|---|
| Candidate A | \((4.0-3.5)/1.4 = 0.36\) | \((10-9)/2.5 = 0.4\) | \((90-80)/35 = 0.29\) |
| Candidate B | \((4.0-2.6)/1.4 = 1\) | \((10-10)/2.5 = 0\) | \((90-90)/35 = 0\) |
| Candidate C | \((4.0-4.0)/1.4 = 0\) | \((10-8.5)/2.5 = 0.6\) | \((90-65)/35 = 1\) |
| Candidate D | \((4.0-3.2)/1.4 = 0.57\) | \((10-7.5)/2.5 = 1\) | \((90-86)/35 = 0.11\) |
- For each candidate, select the worst (highest) deviation: we get \([0.4, 1, 1, 1]\).
The candidate with the lowest worst (min of the max!) deviation is our choice: Candidate A.
The min-max criterion can break a log-jam in the case of multiple objectives, but of course it is not without pitfalls. For one thing, are the metrics all equally important? If not, would a weighted sum of the deviations add any insight? We also notice that the min-max will rule out a candidate who scores at the bottom of the pack in any metric; this may or may not be perceived as fair. In broader terms, such decision-making can have fascinating social aspects.